[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
Na primeira parte desta série, vimos como o problema do Halloween se aplica a
UPDATE consultas. Para recapitular brevemente, o problema era que um índice usado para localizar registros a serem atualizados tinha suas chaves modificadas pela própria operação de atualização (outro bom motivo para usar colunas incluídas em um índice em vez de estender as chaves). O otimizador de consulta introduziu um operador Eager Table Spool para separar os lados de leitura e gravação do plano de execução para evitar o problema. Nesta postagem, veremos como o mesmo problema subjacente pode afetar INSERT e DELETE declarações. Inserir declarações
Agora que sabemos um pouco sobre as condições que exigem a Proteção do Dia das Bruxas, é muito fácil criar um
INSERT exemplo que envolve ler e gravar nas chaves da mesma estrutura de índice. O exemplo mais simples é duplicar linhas em uma tabela (onde adicionar novas linhas inevitavelmente modifica as chaves do índice clusterizado):CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
INSERT dbo.Demo
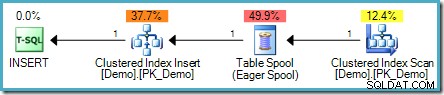
SELECT SomeKey FROM dbo.Demo; O problema é que as linhas recém-inseridas podem ser encontradas pelo lado de leitura do plano de execução, resultando potencialmente em um loop que adiciona linhas para sempre (ou pelo menos até que algum limite de recurso seja atingido). O otimizador de consulta reconhece esse risco e adiciona um Eager Table Spool para fornecer a separação de fases necessária :
Um exemplo mais realista
Você provavelmente não costuma escrever consultas para duplicar todas as linhas em uma tabela, mas provavelmente escreve consultas onde a tabela de destino para um
INSERT também aparece em algum lugar no SELECT cláusula. Um exemplo é adicionar linhas de uma tabela de preparo que ainda não existem no destino:CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
-- Test query
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
); O plano de execução é:
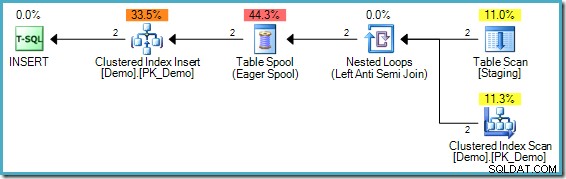
O problema neste caso é sutilmente diferente, embora ainda seja um exemplo do mesmo problema central. Não há valor '1234' na tabela Demo de destino, mas a tabela Staging contém duas dessas entradas. Sem separação de fase, o primeiro valor '1234' encontrado seria inserido com sucesso, mas a segunda verificação descobriria que o valor '1234' agora existe e não tentaria inseri-lo novamente. A declaração como um todo seria concluída com sucesso.
Isso pode produzir um resultado desejável neste caso específico (e pode até parecer intuitivamente correto), mas não é uma implementação correta. O padrão SQL exige que as consultas de modificação de dados sejam executadas como se as três fases de leitura, gravação e verificação de restrições ocorressem completamente separadamente (consulte a primeira parte).
Buscando todas as linhas para inserir como uma única operação, devemos selecionar ambas as linhas ‘1234’ da tabela Staging, pois este valor ainda não existe no destino. O plano de execução deve, portanto, tentar inserir ambos '1234' linhas da tabela Staging, resultando em uma violação de chave primária:
Msg 2627, Nível 14, Estado 1, Linha 1
Violação da restrição PRIMARY KEY 'PK_Demo'.
Não é possível inserir chave duplicada no objeto 'dbo.Demo'.
O valor da chave duplicada é ( 1234).
A instrução foi encerrada.
A separação de fases fornecida pelo Table Spool garante que todas as verificações de existência sejam concluídas antes que qualquer alteração seja feita na tabela de destino. Se você executar a consulta no SQL Server com os dados de exemplo acima, receberá a mensagem de erro (correta).
Halloween Protection é necessário para instruções INSERT em que a tabela de destino também é referenciada na cláusula SELECT.
Excluir extratos
Podemos esperar que o problema do Halloween não se aplique a
DELETE instruções, já que não deveria importar se tentarmos excluir uma linha várias vezes. Podemos modificar nosso exemplo de tabela de preparo para remover linhas da tabela Demo que não existem no Staging:TRUNCATE TABLE dbo.Demo;
TRUNCATE TABLE dbo.Staging;
INSERT dbo.Demo (SomeKey) VALUES (1234);
DELETE dbo.Demo
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Staging AS s
WHERE s.SomeKey = dbo.Demo.SomeKey
); Este teste parece validar nossa intuição porque não há Spool de Tabela no plano de execução:
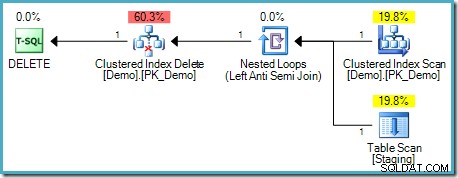
Este tipo de
DELETE não requer separação de fase porque cada linha tem um identificador exclusivo (um RID se a tabela for um heap, chaves de índice clusterizadas e possivelmente um unificador caso contrário). Este localizador de linha exclusivo é uma chave estável – não há nenhum mecanismo pelo qual ele possa mudar durante a execução deste plano, então o problema do Halloween não surge. EXCLUIR Proteção de Dia das Bruxas
No entanto, há pelo menos um caso em que um
DELETE requer proteção de Halloween:quando o plano faz referência a uma linha na tabela diferente daquela que está sendo excluída. Isso requer uma autojunção, comumente encontrada quando os relacionamentos hierárquicos são modelados. Um exemplo simplificado é mostrado abaixo:CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', 'A'),
('C', 'B'),
('D', 'C'); Realmente deveria haver uma referência de chave estrangeira de mesma tabela definida aqui, mas vamos ignorar essa falha de design por um momento – a estrutura e os dados são válidos (e infelizmente é bastante comum encontrar chaves estrangeiras omitidas no mundo real). De qualquer forma, a tarefa é deletar qualquer linha onde a ref coluna aponta para um pk inexistente valor. O
DELETE natural consulta que corresponde a este requisito é:DELETE dbo.Test
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t2
WHERE t2.pk = dbo.Test.ref
); O plano de consulta é:
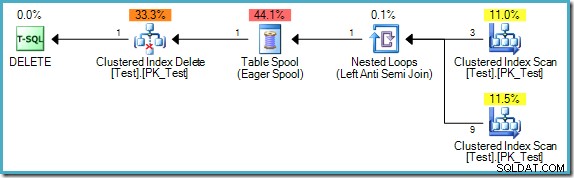
Observe que este plano agora apresenta um caro Eager Table Spool. A separação de fases é necessária aqui porque, caso contrário, os resultados podem depender da ordem em que as linhas são processadas:
Se o mecanismo de execução iniciar com a linha em que pk =B, não encontraria nenhuma linha correspondente (ref =A e não há linha onde pk =A). Se a execução passa para a linha onde pk =C, também seria excluído porque acabamos de remover a linha B apontada por sua ref coluna. O resultado final seria que o processamento iterativo nessa ordem excluiria todas as linhas da tabela, o que é claramente incorreto.
Por outro lado, se o mecanismo de execução processou a linha com pk =D primeiro, encontraria uma linha correspondente (ref =C). Assumindo que a execução continuou no sentido inverso pk ordem, a única linha excluída da tabela seria aquela em que pk =B. Este é o resultado correto (lembre-se que a consulta deve ser executada como se as fases de leitura, gravação e validação tivessem ocorrido sequencialmente e sem sobreposições).
Separação de fase para validação de restrição
Como aparte, podemos ver outro exemplo de separação de fases se adicionarmos uma restrição de chave estrangeira de mesma tabela ao exemplo anterior:
DROP TABLE dbo.Test;
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk),
CONSTRAINT FK_ref_pk
FOREIGN KEY (ref)
REFERENCES dbo.Test (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', NULL),
('C', 'B'),
('D', 'C'); O plano de execução do INSERT é:
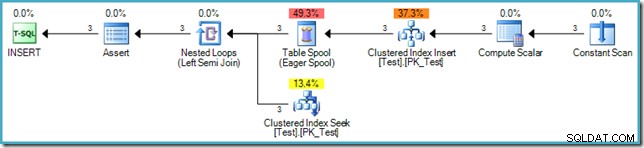
A inserção em si não requer proteção de Halloween, pois o plano não lê da mesma tabela (a fonte de dados é uma tabela virtual na memória representada pelo operador Constant Scan). No entanto, o padrão SQL exige que a fase 3 (verificação de restrição) ocorra após a conclusão da fase de gravação. Por esse motivo, um Eager Table Spool de separação de fases é adicionado ao plano depois o Índice de Índice Agrupado e logo antes de cada linha ser verificada para garantir que a restrição de chave estrangeira permaneça válida.
Se você está começando a pensar que traduzir uma consulta de modificação de SQL declarativa baseada em conjunto para um plano de execução física iterativo robusto é um negócio complicado, você está começando a ver por que o processamento de atualização (do qual a Proteção de Halloween é apenas uma parte muito pequena) é o parte mais complexa do Processador de Consultas.
Declarações DELETE exigem proteção de Halloween quando uma autojunção da tabela de destino está presente.
Resumo
A proteção de Halloween pode ser um recurso caro (mas necessário) em planos de execução que alteram dados (onde 'alterar' inclui toda a sintaxe SQL que adiciona, altera ou remove linhas). A proteção de Halloween é necessária para
UPDATE planos onde as chaves de uma estrutura de índice comum são lidas e modificadas, para INSERT planos em que a tabela de destino é referenciada no lado de leitura do plano e para DELETE planos em que uma autojunção na tabela de destino é executada. A próxima parte desta série abordará algumas otimizações especiais de problemas de Halloween que se aplicam apenas a
MERGE declarações. [ Parte 1 | Parte 2 | Parte 3 | Parte 4]