A execução de um Galera Cluster em uma nuvem híbrida deve consistir em pelo menos dois locais geográficos diferentes, conectando hosts na nuvem local ou privada com os da nuvem pública. Quer você use plataformas de nuvem privada ou de nuvem pública inquebráveis, a Recuperação de Desastres (DR) é realmente uma questão fundamental. Não se trata de copiar seus dados para um site de backup e poder restaurá-los, trata-se de continuidade dos negócios e da rapidez com que você pode recuperar serviços quando ocorre um desastre.
Nesta postagem de blog, examinaremos diferentes maneiras de projetar seus Clusters Galera para tolerância a falhas em um ambiente de nuvem híbrida.
Configuração ativo-ativo
Galera Cluster deve ser executado com um número ímpar de nós em um cluster e geralmente começa com 3 nós. Isso ocorre porque o Galera Cluster utiliza o quorum para determinar automaticamente o componente primário, onde a maioria dos nós conectados deve ser capaz de atender o cluster por vez, caso ocorra o particionamento do cluster.
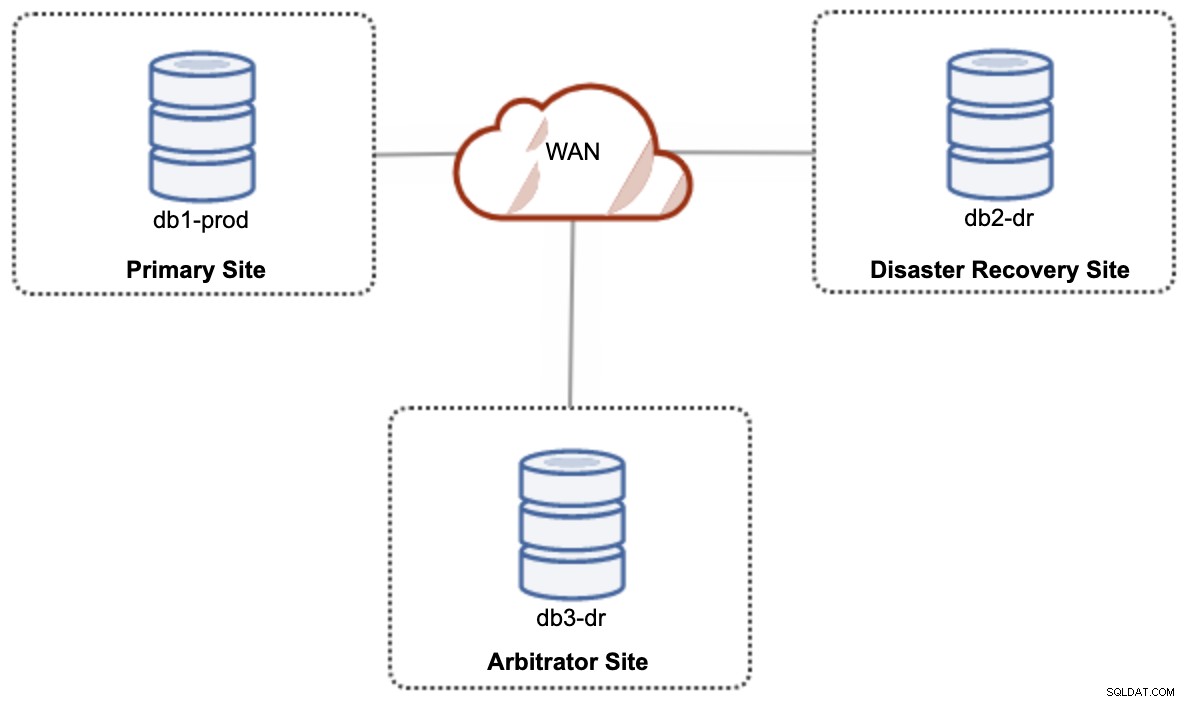
Para uma configuração de nuvem híbrida de configuração ativa-ativa, o Galera requer pelo menos 3 locais diferentes, formando um Galera Cluster na WAN. Geralmente, você precisaria de um terceiro site para atuar como árbitro, votando por quórum e preservando o “componente primário” se algum dos sites estiver inacessível. Isso pode ser configurado como um cluster de no mínimo 3 nós em 3 sites diferentes (1 nó por site), semelhante ao diagrama a seguir:
No entanto, para fins de desempenho e confiabilidade, é recomendável ter um 7 -node cluster, conforme mostrado no diagrama a seguir:
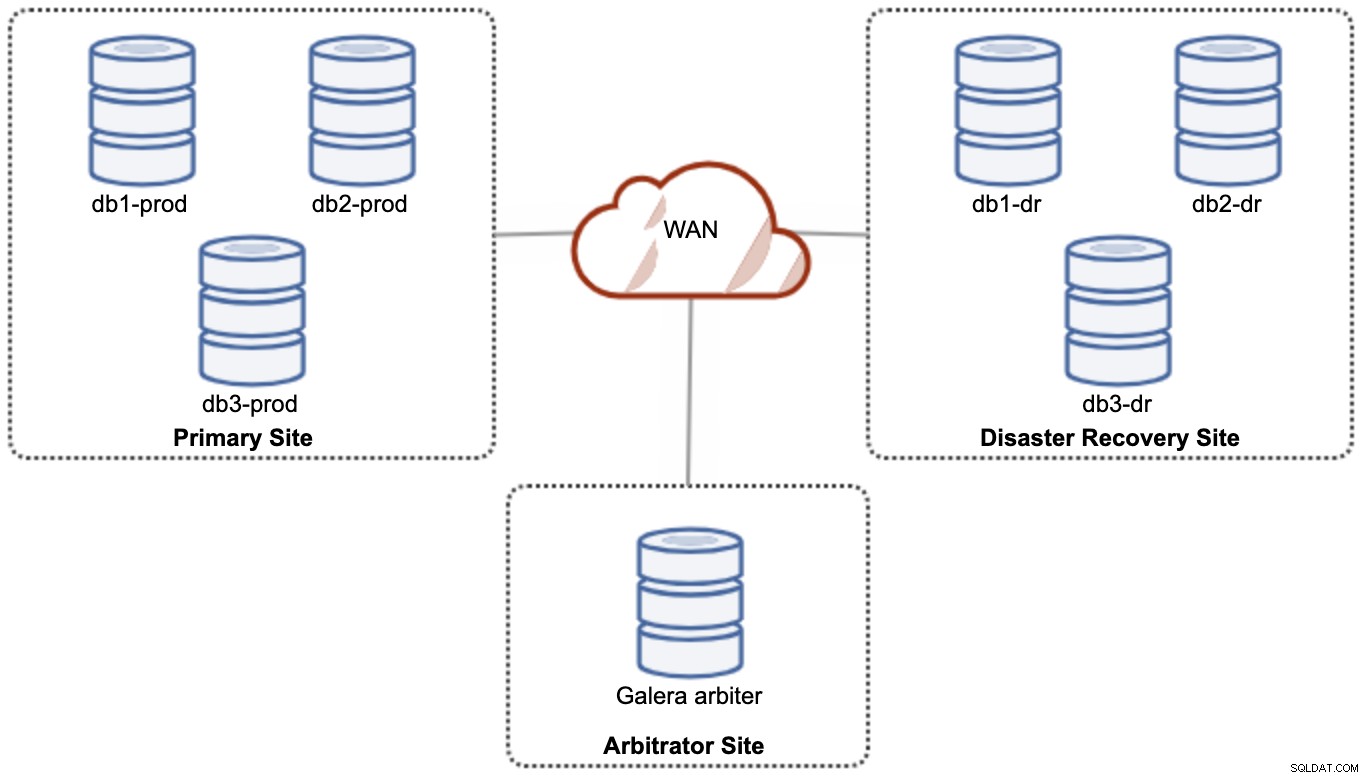
Esta é considerada a melhor topologia para suportar uma configuração ativa-ativa, onde o site de DR deve estar disponível quase que imediatamente, sem nenhuma intervenção. Ambos os sites podem receber leituras/gravações a qualquer momento, desde que o cluster esteja no quorum.
No entanto, é muito caro ter 3 sites e 7 nós de banco de dados (o 7º nó pode ser substituído por um garbd, pois é muito improvável que seja usado para fornecer dados aos clientes/aplicativos). Geralmente, essa não é uma implantação popular no início do projeto devido ao enorme custo inicial e à sensibilidade da comunicação e replicação do grupo Galera à latência da rede.
Configuração ativa-passiva
Em uma configuração ativa-passiva, são necessários pelo menos 2 sites e apenas um site está ativo por vez, conhecido como site primário e os nós no site secundário apenas replicam dados provenientes do site primário servidor/grupo. Para o Galera Cluster, podemos usar a replicação assíncrona do MySQL (replicação mestre-escravo) ou também podemos usar a replicação virtualmente síncrona do Galera com alguns ajustes para diminuir o tom de sua replicação de conjunto de escrita para atuar como replicação assíncrona.
O site secundário deve ser protegido contra gravações acidentais, usando o sinalizador somente leitura, firewall de aplicativo, proxy reverso ou qualquer outro meio, pois o fluxo de dados está sempre vindo do site primário para o secundário, a menos que um failover iniciou e promoveu o site secundário como primário.
Usando replicação assíncrona
Uma coisa boa sobre a replicação assíncrona é que a replicação não afeta o servidor/cluster de origem, mas pode ficar atrasada em relação ao mestre. Essa configuração tornará o site primário e o de DR independentes um do outro, conectados livremente com a replicação assíncrona. Isso pode ser configurado como um cluster mínimo de 4 nós em 2 sites diferentes, semelhante ao diagrama a seguir:
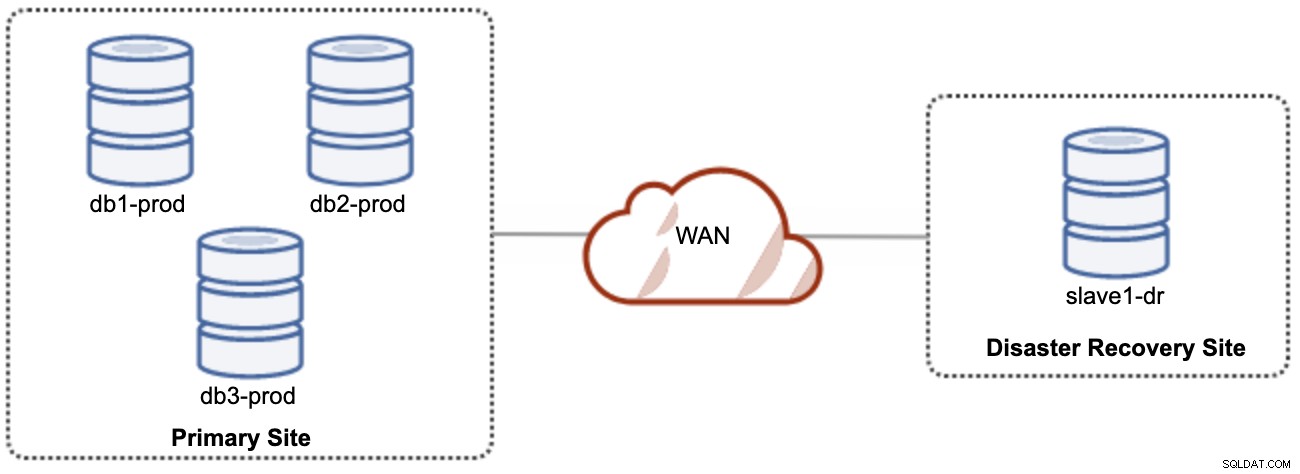
Um dos nós Galera no site DR será um escravo, que replica de um dos nós Galera (mestre) no site primário. Ambos os sites precisam produzir logs binários com GTID e log_slave_updates estão habilitados - as atualizações que vêm do fluxo de replicação assíncrona serão aplicadas aos outros nós do cluster. No entanto, para uso em produção, recomendamos ter dois conjuntos de clusters em ambos os sites, conforme mostrado no diagrama a seguir:
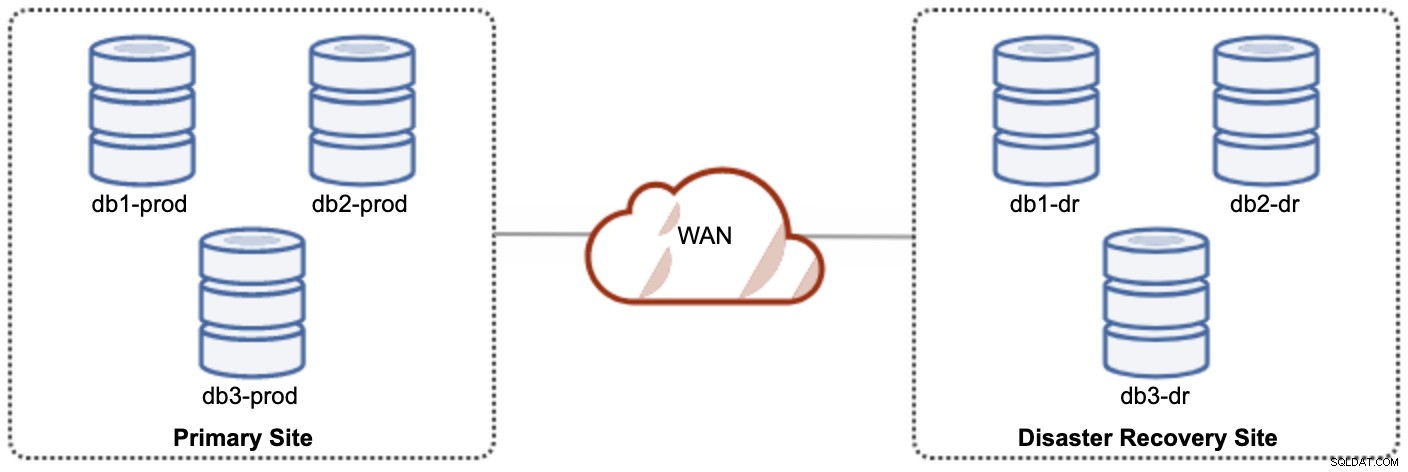
Tendo dois clusters separados, eles serão fracamente acoplados e não impactarão um ao outro, por exemplo. uma falha de cluster no site primário não afetará o site de DR. Em termos de desempenho, a latência da WAN não afetará as atualizações no cluster ativo. Eles são enviados de forma assíncrona para o site de backup. O cluster de DR pode ser executado em instâncias menores em um ambiente de nuvem pública, desde que possam acompanhar o cluster primário. As instâncias podem ser atualizadas, se necessário. Os aplicativos devem enviar gravações para o site primário e o site secundário deve ser configurado para ser executado no modo somente leitura. O site de recuperação de desastres pode ser usado para outros fins, como backup de banco de dados, backup de logs binários e relatórios ou processamento de consultas analíticas (OLAP).
No lado negativo, há uma chance de perda de dados durante o failover/fallback se o escravo estiver atrasado. Portanto, é recomendável habilitar a replicação semi-síncrona para reduzir o risco de perda de dados. Observe que o uso de replicação semi-síncrona ainda não oferece fortes garantias contra perda de dados, se comparado à replicação virtualmente síncrona do Galera. Leia este manual do MySQL com atenção, por exemplo, estas frases:
"Com a replicação semi-síncrona, se a fonte falhar e for executado um failover para uma réplica, a fonte com falha não deve ser reutilizada como fonte de replicação e deve ser descartada. Pode haver transações que foram não reconhecido por nenhuma réplica, que, portanto, não foi confirmado antes do failover."
O processo de failover é bastante simples. Para promover o site de recuperação de desastres, basta desativar o sinalizador somente leitura e começar a direcionar o aplicativo para os nós do banco de dados no site de recuperação de desastres. A estratégia de fallback é um pouco complicada, porém, e requer alguma experiência em preparar os dados em ambos os sites, alternar a função mestre/escravo de um cluster e redirecionar o fluxo de replicação escravo para o caminho oposto.
Usando a replicação do Galera
Para configuração ativa-passiva, podemos colocar a maioria dos nós localizados no site primário enquanto a minoria dos nós localizados no site de recuperação de desastres, conforme mostrado na captura de tela a seguir para um 3- nó Galera Cluster:
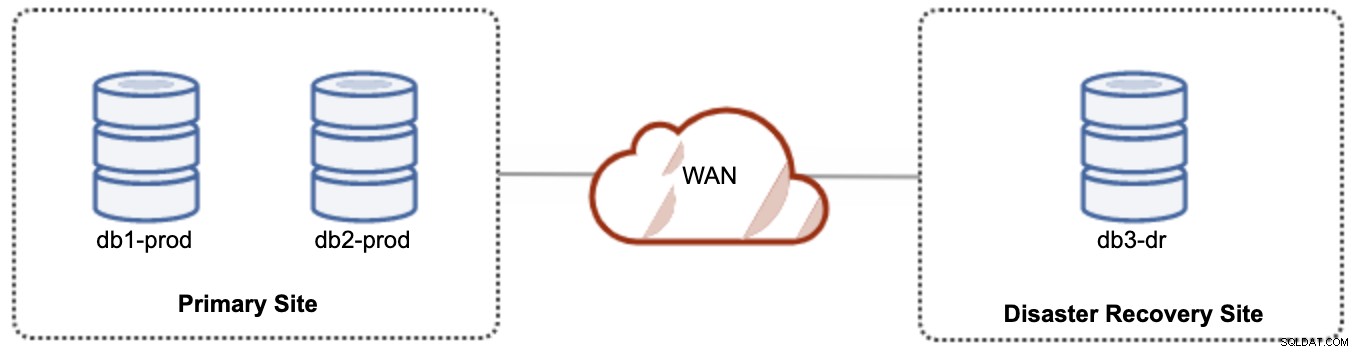
Se o site primário estiver inativo, o cluster falhará porque está fora do quorum. O nó Galera no site de recuperação de desastres (db3-dr) precisará ser inicializado manualmente como um componente primário de nó único. Assim que o site primário voltar a funcionar, ambos os nós no site primário (db1-prod e db2-prod) precisam se juntar novamente à galera3 para serem sincronizados. Ter um gcache bastante grande deve ajudar a reduzir o risco de SST sobre WAN. Essa arquitetura é fácil de configurar e administrar e muito econômica.
O failover é manual, pois o administrador precisa promover o nó único como o componente principal (bootstrap db3-dr ou use set pc.bootstrap=1 no parâmetro wsrep_provider_options. Haveria tempo de inatividade nesse meio tempo . O desempenho pode ser um problema, pois o site de DR será executado com um número menor de nós (já que o site de DR é sempre a minoria) para executar toda a carga. Talvez seja possível expandir com mais nós após alternar para o site DR, mas cuidado com a carga adicional.
Observe que o Galera Cluster é sensível à rede devido à sua natureza virtualmente síncrona. Quanto mais distantes os nós Galera estiverem em um determinado cluster, maior a latência e sua capacidade de gravação para distribuir e certificar os conjuntos de gravação. Além disso, se a conectividade não for estável, o particionamento do cluster pode ocorrer facilmente, o que pode acionar a sincronização do cluster nos nós do joiner. Em alguns casos, isso pode introduzir instabilidade no cluster. Isso requer um pouco de ajuste nos parâmetros do Galera, conforme mostrado nesta postagem do blog, Implantando um ambiente de infraestrutura híbrida para Percona XtraDB Cluster.
Considerações finais
O Galera Cluster é uma ótima tecnologia que pode ser implantada de diferentes maneiras - um cluster estendido em vários sites, vários clusters mantidos em sincronia por meio de replicação assíncrona, uma mistura de replicação síncrona e assíncrona e assim por diante. A solução real será ditada por fatores como latência de WAN, consistência de dados eventual versus forte e orçamento.