Autor convidado:Monica Rathbun (@SQLEspresso)
Às vezes, problemas de desempenho de hardware, como latência de E/S de disco, se resumem a uma carga de trabalho não otimizada, em vez de um hardware com baixo desempenho. Muitos administradores de banco de dados, inclusive eu, querem imediatamente culpar o armazenamento pela lentidão. Antes de gastar muito dinheiro em um novo hardware, você deve sempre examinar sua carga de trabalho em busca de E/S desnecessária.
Coisas a examinar
| Item | Impacto de E/S | Soluções possíveis |
|---|---|---|
| Índices não usados | Gravações extras | Remover / Desativar Índice |
| Índices ausentes | Leituras extras | Adicionar índice/índices de cobertura |
| Conversões implícitas | Leituras e gravações extras | Campo oculto ou lançado na origem antes de avaliar o valor |
| Funções | Leituras e gravações extras | Removido, converta os dados antes da avaliação |
| ETL | Leituras e gravações extras | Use SSIS, Replicação, Change Data Capture, Grupos de Disponibilidade |
| Ordenar e Agrupar Bys | Leituras e gravações extras | Remova-os sempre que possível |
Índices não utilizados
Todos nós conhecemos o poder de um índice. Ter os índices adequados pode fazer anos-luz de diferença na velocidade da consulta. No entanto, quantos de nós mantemos continuamente nossos índices acima e além da reconstrução e reorganização do índice? É importante executar regularmente um script de índice para avaliar quais índices estão realmente sendo usados. Eu pessoalmente uso as consultas de diagnóstico de Glenn Berry para fazer isso.
Você ficará surpreso ao descobrir que alguns de seus índices não foram lidos. Esses índices sobrecarregam os recursos, especialmente em uma tabela altamente transacional. Ao observar os resultados, preste atenção aos índices que possuem um número alto de gravações combinado com um número baixo de leituras. Neste exemplo, você pode ver que estou desperdiçando gravações. O índice não agrupado foi gravado 11 milhões de vezes, mas lido apenas duas vezes.

Começo desativando os índices que se enquadram nessa categoria e, em seguida, descarto-os depois de confirmar que não surgiram problemas. Fazer este exercício rotineiramente pode reduzir muito as gravações de E/S desnecessárias em seu sistema, mas lembre-se de que as estatísticas de uso em seus índices são tão boas quanto a última reinicialização, portanto, certifique-se de coletar dados por um ciclo de negócios completo antes de cancelar um índice como "inútil".
Índices ausentes
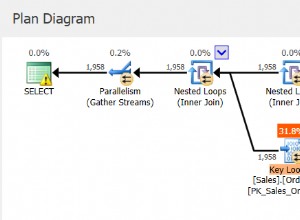
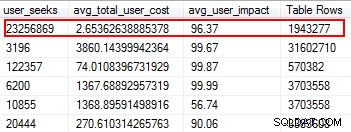
Índices ausentes são uma das coisas mais fáceis de corrigir; afinal, quando você executa um plano de execução, ele informa se algum índice não foi encontrado, mas isso teria sido útil. Mas espere, espero que você não esteja apenas adicionando índices arbitrariamente com base nessa sugestão. Isso pode criar índices duplicados e índices que podem ter uso mínimo e, portanto, desperdiçar E/S. Novamente, voltando aos scripts de Glenn, ele nos dá uma ótima ferramenta para avaliar a utilidade de um índice fornecendo buscas de usuários, impacto do usuário e número de linhas. Preste atenção àqueles com leituras altas, além de baixo custo e impacto. Este é um ótimo lugar para começar e o ajudará a reduzir a E/S de leitura.
Conversões implícitas
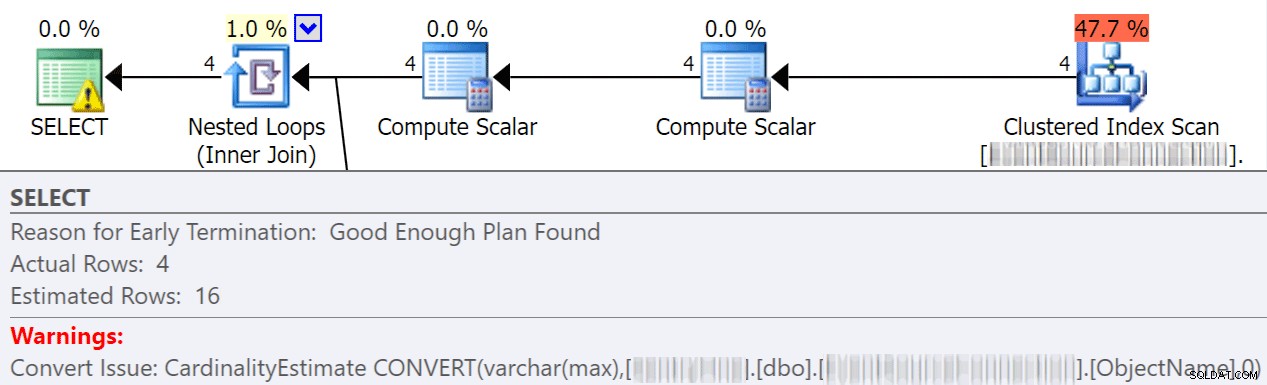
As conversões implícitas geralmente acontecem quando uma consulta compara duas ou mais colunas com diferentes tipos de dados. No exemplo abaixo, o sistema está tendo que realizar E/S extra para comparar uma coluna varchar(max) com uma coluna nvarchar(4000), o que leva a uma conversão implícita e, por fim, a uma varredura em vez de uma busca. Ao corrigir as tabelas para que tenham tipos de dados correspondentes ou simplesmente converter esse valor antes da avaliação, você pode reduzir bastante a E/S e melhorar a cardinalidade (as linhas estimadas que o otimizador deve esperar).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias entra em muito mais detalhes neste ótimo post:"Quão caras são as conversões implícitas do lado da coluna?"
Funções
Uma das coisas mais evitáveis e fáceis de corrigir que encontrei que economizam despesas de E/S é remover funções das cláusulas where. Um exemplo perfeito é uma comparação de datas, conforme mostrado abaixo.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Seja em uma instrução JOIN ou em uma cláusula WHERE, isso faz com que cada coluna seja convertida antes de ser avaliada. Simplesmente convertendo essas colunas antes da avaliação em uma tabela temporária, você pode eliminar uma tonelada de E/S desnecessárias.
Ou, melhor ainda, não execute nenhuma conversão (para este caso específico, Aaron Bertrand fala aqui sobre como evitar funções na cláusula where, e observe que isso ainda pode ser ruim mesmo que convert to date seja sargável).
ETL
Reserve um tempo para examinar como seus dados estão sendo carregados. Você está truncando e recarregando tabelas? Você pode implementar a replicação, uma réplica de AG somente leitura ou o envio de logs? Todas as tabelas que estão sendo gravadas estão realmente sendo lidas? Como você está carregando os dados? É através de procedimentos armazenados ou SSIS? Examinar coisas como essa pode reduzir drasticamente a E/S.
No meu ambiente, descobri que estávamos truncando 48 tabelas diariamente com mais de 120 milhões de linhas todas as manhãs. Além disso, estávamos carregando 9,6 milhões de linhas por hora. Você pode imaginar quanta E/S desnecessária isso criou. No meu caso, implementar a replicação transacional foi minha solução de escolha. Uma vez implementado, tivemos muito menos reclamações de usuários de lentidão durante nossos tempos de carregamento, que inicialmente foram atribuídos ao armazenamento lento.
Ordenar por e agrupar por
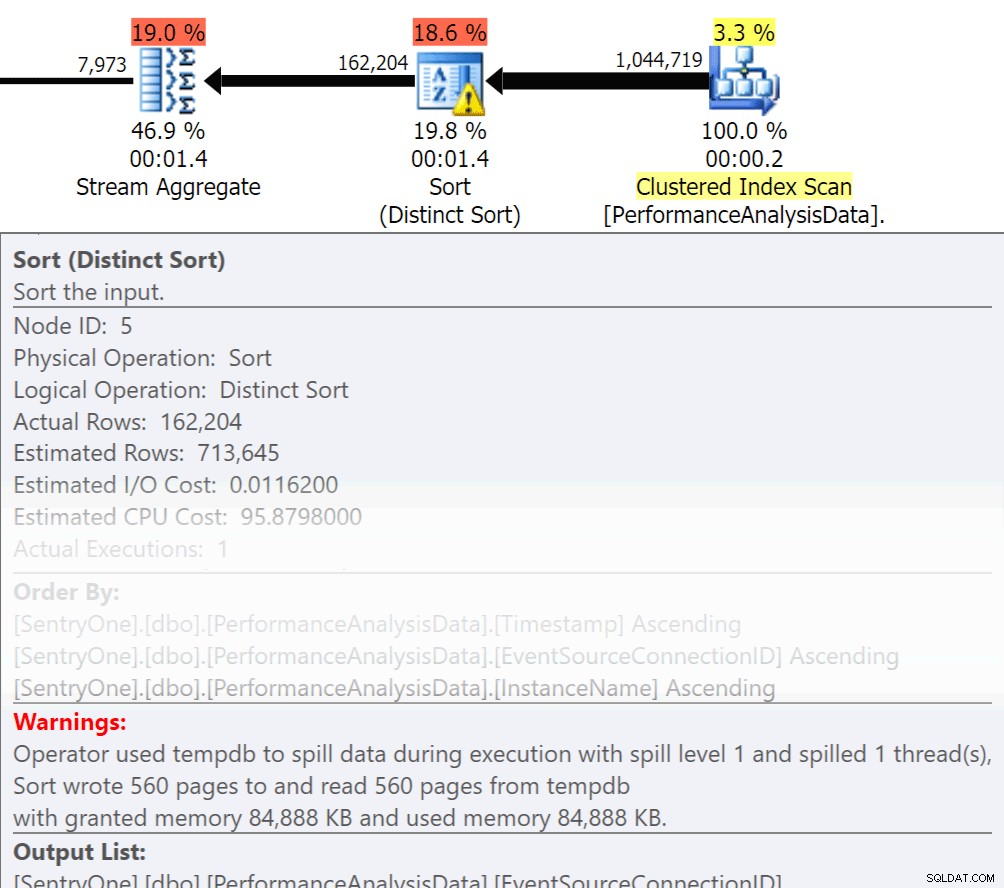 Pergunte a si mesmo, esses dados precisam ser retornados em ordem? Realmente precisamos agrupar no procedimento, ou podemos lidar com isso em um relatório ou aplicativo? As operações Order By e Group By podem fazer com que as leituras transbordem para o disco, o que causa E/S de disco adicional. Se essas ações forem garantidas, certifique-se de ter índices de suporte e estatísticas atualizadas nas colunas que estão sendo classificadas ou agrupadas. Isso ajudará o otimizador durante a criação do plano. Como às vezes usamos Order By e Group By em tabelas temporárias. certifique-se de ter Auto Create Statistics On para TEMPDB, bem como seus bancos de dados de usuário. Quanto mais atualizadas as estatísticas estiverem, melhor a cardinalidade o otimizador poderá obter, resultando em melhores planos, menos transbordamento e menos E/S.
Pergunte a si mesmo, esses dados precisam ser retornados em ordem? Realmente precisamos agrupar no procedimento, ou podemos lidar com isso em um relatório ou aplicativo? As operações Order By e Group By podem fazer com que as leituras transbordem para o disco, o que causa E/S de disco adicional. Se essas ações forem garantidas, certifique-se de ter índices de suporte e estatísticas atualizadas nas colunas que estão sendo classificadas ou agrupadas. Isso ajudará o otimizador durante a criação do plano. Como às vezes usamos Order By e Group By em tabelas temporárias. certifique-se de ter Auto Create Statistics On para TEMPDB, bem como seus bancos de dados de usuário. Quanto mais atualizadas as estatísticas estiverem, melhor a cardinalidade o otimizador poderá obter, resultando em melhores planos, menos transbordamento e menos E/S. Agora Group By definitivamente tem seu lugar quando se trata de agregar dados em vez de retornar uma tonelada de linhas. Mas a chave aqui é reduzir a E/S, a adição da agregação aumenta a E/S.
Resumo
Essas são apenas as coisas da ponta do iceberg, mas um ótimo lugar para começar a reduzir a E/S. Antes de culpar o hardware por seus problemas de latência, dê uma olhada no que você pode fazer para minimizar a pressão do disco.
Sobre o autor
 Monica Rathbun é atualmente consultora da Denny Cherry &Associates Consulting e MVP da Microsoft Data Platform. Ela é uma DBA solitária há 15 anos, trabalhando com todos os aspectos do SQL Server e Oracle. Ela viaja falando no SQLSaturdays ajudando outros DBAs Lone com técnicas de como se pode fazer o trabalho de muitos. Monica é a líder do grupo de usuários do Hampton Roads SQL Server e é uma mentora regional do Mid-Atlantic Pass. Você sempre pode encontrar Monica no Twitter (@SQLEspresso) distribuindo dicas e truques úteis para seus seguidores. Quando ela não está ocupada com o trabalho, você a encontrará brincando de motorista de táxi para suas duas filhas irem e voltarem para as aulas de dança.
Monica Rathbun é atualmente consultora da Denny Cherry &Associates Consulting e MVP da Microsoft Data Platform. Ela é uma DBA solitária há 15 anos, trabalhando com todos os aspectos do SQL Server e Oracle. Ela viaja falando no SQLSaturdays ajudando outros DBAs Lone com técnicas de como se pode fazer o trabalho de muitos. Monica é a líder do grupo de usuários do Hampton Roads SQL Server e é uma mentora regional do Mid-Atlantic Pass. Você sempre pode encontrar Monica no Twitter (@SQLEspresso) distribuindo dicas e truques úteis para seus seguidores. Quando ela não está ocupada com o trabalho, você a encontrará brincando de motorista de táxi para suas duas filhas irem e voltarem para as aulas de dança.