Um dos problemas mais desconcertantes para solucionar problemas no SQL Server pode ser aqueles relacionados a concessões de memória. Algumas consultas precisam de mais memória do que outras para serem executadas, com base em quais operações precisam ser executadas (por exemplo, classificação, hash). O otimizador do SQL Server estima a quantidade de memória necessária e a consulta deve obter a concessão de memória para iniciar a execução. Ele mantém essa concessão durante a execução da consulta - o que significa que, se o otimizador superestimar a memória, você poderá ter problemas de simultaneidade. Se subestimar a memória, você poderá ver vazamentos no tempdb. Nenhum dos dois é o ideal e, quando você simplesmente tem muitas consultas solicitando mais memória do que a disponível para conceder, verá RESOURCE_SEMAPHORE aguardando. Existem várias maneiras de atacar esse problema, e um dos meus novos métodos favoritos é usar o Query Store.
Configuração
Usaremos uma cópia de WideWorldImporters que inflacionei usando o procedimento armazenado DataLoadSimulation.DailyProcessToCreateHistory. A tabela Sales.Orders tem cerca de 4,6 milhões de linhas e a tabela Sales.OrderLines tem cerca de 9,2 milhões de linhas. Restauraremos o backup e habilitaremos o Repositório de Consultas e limparemos todos os dados antigos do Repositório de Consultas para não alterar nenhuma métrica para esta demonstração.
Lembrete:Não execute ALTER DATABASE
USE [master]; GO RESTORE DATABASE [WideWorldImporters] FROM DISK = N'C:\Backups\WideWorldImporters.bak' WITH FILE = 1, MOVE N'WWI_Primary' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.mdf', MOVE N'WWI_UserData' TO N'C:\Databases\WideWorldImporters\WideWorldImporters_UserData.ndf', MOVE N'WWI_Log' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.ldf', NOUNLOAD, REPLACE, STATS = 5 GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, INTERVAL_LENGTH_MINUTES = 10 ); GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE CLEAR; GO
O procedimento armazenado que usaremos para testar as consultas das tabelas Orders e OrderLines acima mencionadas com base em um intervalo de datas:
USE [WideWorldImporters]; GO DROP PROCEDURE IF EXISTS [Sales].[usp_OrderInfo_OrderDate]; GO CREATE PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO
Teste
Vamos executar o procedimento armazenado com três conjuntos diferentes de parâmetros de entrada:
EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
A primeira execução retorna 1.958 linhas, a segunda retorna 267.268 linhas e a última retorna mais de 2,2 milhões de linhas. Se você observar os intervalos de datas, isso não é surpreendente – quanto maior o intervalo de datas, mais dados serão retornados.
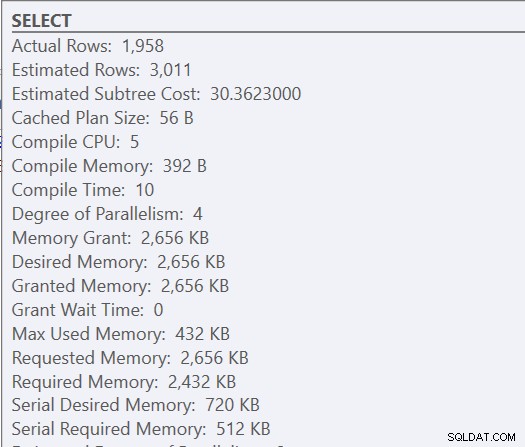
Por se tratar de um procedimento armazenado, os parâmetros de entrada utilizados inicialmente determinam o plano, bem como a memória a ser concedida. Se observarmos o plano de execução real para a primeira execução, veremos loops aninhados e uma concessão de memória de 2656 KB.
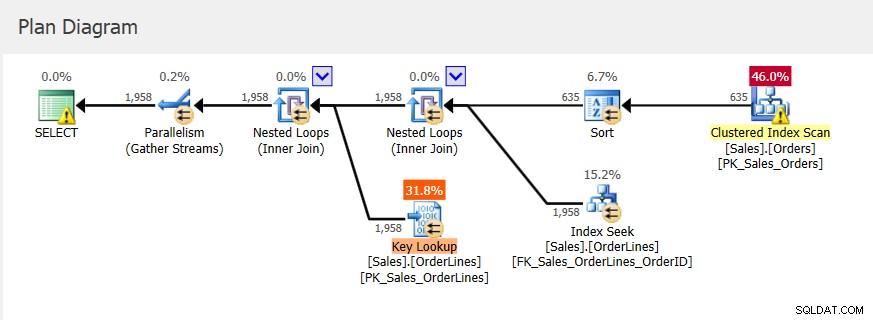
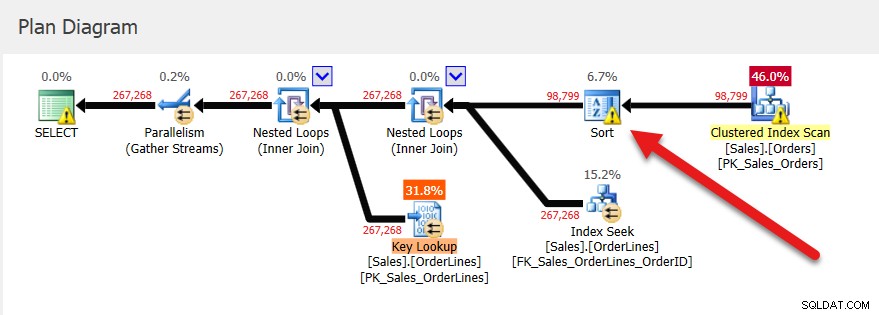
As execuções subsequentes têm o mesmo plano (já que foi isso que foi armazenado em cache) e a mesma concessão de memória, mas temos uma pista de que não é suficiente porque há um aviso de classificação.
Se procurarmos no Repositório de Consultas por esse procedimento armazenado, veremos três execuções e os mesmos valores para a memória UsedKB, independentemente de examinarmos o Desvio Médio, Mínimo, Máximo, Último ou Padrão. Observação:as informações de concessão de memória no Query Store são relatadas como o número de páginas de 8 KB.
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], --memory grant (reported as the number of 8 KB pages) for the query plan within the aggregation interval [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE [qsq].[object_id] = OBJECT_ID(N'Sales.usp_OrderInfo_OrderDate');

Se estivermos procurando por problemas de concessão de memória neste cenário – onde um plano é armazenado em cache e reutilizado – o Query Store não nos ajudará.
Mas e se a consulta específica for compilada na execução, seja por causa de uma dica RECOMPILE ou porque é ad-hoc?
Podemos alterar o procedimento para adicionar a dica RECOMPILE à instrução (o que é recomendado em vez de adicionar RECOMPILE no nível do procedimento ou executar o procedimento WITH RECOMPIPLE):
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate] OPTION (RECOMPILE); GO
Agora vamos reexecutar nosso procedimento com os mesmos parâmetros de entrada de antes e verificar a saída:

Observe que temos um novo query_id – o texto da consulta mudou porque adicionamos OPTION (RECOMPILE) a ele – e também temos dois novos valores de plan_id e temos diferentes números de concessão de memória para um de nossos planos. Para plan_id 5, há apenas uma execução e os números de concessão de memória correspondem à execução inicial – de modo que o plano é para o pequeno intervalo de datas. Os dois intervalos de data maiores geraram o mesmo plano, mas há uma variabilidade significativa nas concessões de memória – 94.528 para o mínimo e 573.568 para o máximo.
Se observarmos as informações de concessão de memória usando os relatórios do Repositório de Consultas, essa variabilidade será um pouco diferente. Abrindo o relatório Top Resource Consumers do banco de dados e, em seguida, alterando a métrica para Memory Consumption (KB) e Avg, nossa consulta com o RECOMPILE chega ao topo da lista.
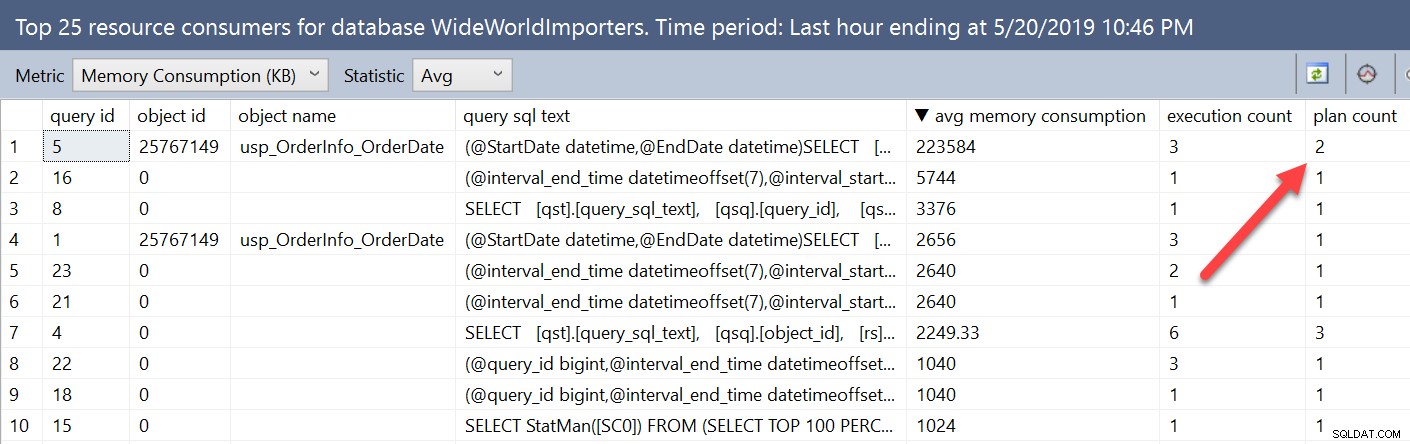
Nesta janela, as métricas são agregadas por consulta, não por plano. A consulta que executamos diretamente nas visualizações do Query Store listou não apenas o query_id, mas também o plan_id. Aqui podemos ver que a consulta tem dois planos e podemos visualizar ambos na janela de resumo do plano, mas as métricas são combinadas para todos os planos nesta visualização.
A variabilidade nas concessões de memória é óbvia quando estamos olhando diretamente para as visualizações. Podemos encontrar consultas com variabilidade usando a interface do usuário alterando a estatística de Avg para StDev:
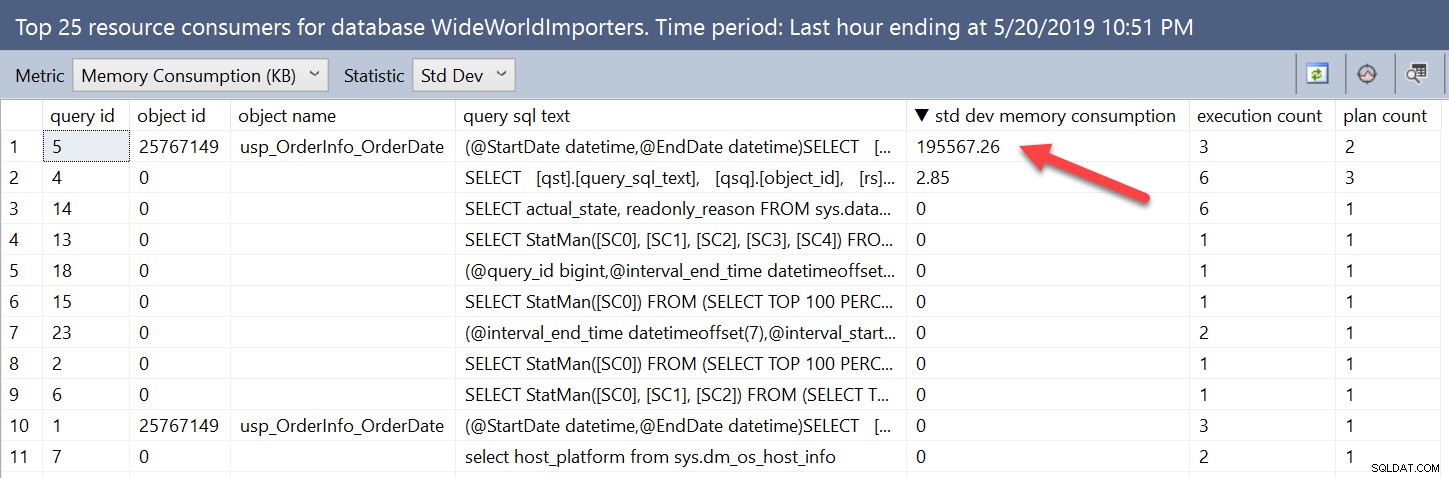
Podemos encontrar as mesmas informações consultando as visualizações do Query Store e ordenando por stdev_query_max_used_memory decrescente. Mas também podemos pesquisar com base na diferença entre a concessão de memória mínima e máxima, ou uma porcentagem da diferença. Por exemplo, se estivéssemos preocupados com casos em que a diferença nas concessões fosse maior que 512 MB, poderíamos executar:
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE ([rs].[max_query_max_used_memory]*8) - ([rs].[min_query_max_used_memory]*8) > 524288;
Aqueles de vocês que executam o SQL Server 2017 com índices Columnstore, que têm a vantagem do feedback de concessão de memória, também podem usar essas informações no Repositório de Consultas. Primeiro, alteraremos nossa tabela Orders para adicionar um índice Columnstore clusterizado:
ALTER TABLE [Sales].[Invoices] DROP CONSTRAINT [FK_Sales_Invoices_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [FK_Sales_Orders_BackorderOrderID_Sales_Orders]; GO ALTER TABLE [Sales].[OrderLines] DROP CONSTRAINT [FK_Sales_OrderLines_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [PK_Sales_Orders] WITH ( ONLINE = OFF ); GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Orders ON [Sales].[Orders];
Em seguida, definiremos o modo de penteabilidade do banco de dados para 140 para que possamos aproveitar o feedback de concessão de memória:
ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 140; GO
Por fim, alteraremos nosso procedimento armazenado para remover OPTION (RECOMPILE) de nossa consulta e executá-lo algumas vezes com os diferentes valores de entrada:
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
No Query Store, vemos o seguinte:

Temos um novo plano para query_id =1, que tem valores diferentes para as métricas de concessão de memória e um StDev um pouco menor do que tínhamos com plan_id 6. Se examinarmos o plano no Query Store, veremos que ele acessa o índice Columnstore clusterizado :
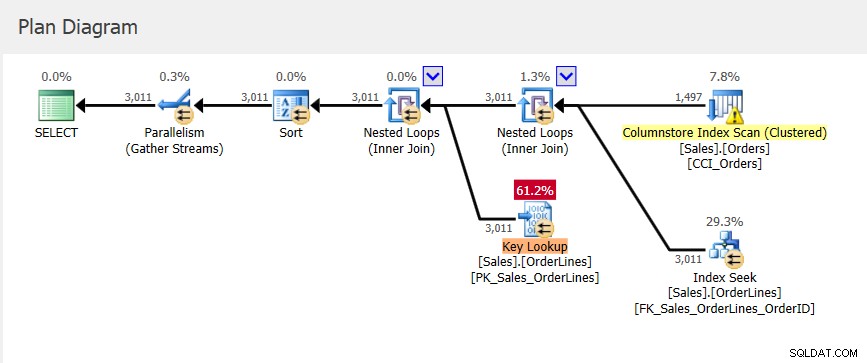
Lembre-se de que o plano no Query Store é aquele que foi executado, mas contém apenas estimativas. Embora o plano no cache do plano tenha informações de concessão de memória atualizadas quando ocorre o feedback de memória, essas informações não são aplicadas ao plano existente no Repositório de Consultas.
Resumo
Aqui está o que eu gosto de usar o Query Store para examinar consultas com concessões de memória variável:os dados estão sendo coletados automaticamente. Se esse problema aparecer inesperadamente, não precisamos fazer nada para tentar coletar informações, já o capturamos no Query Store. No caso em que uma consulta é parametrizada, pode ser mais difícil encontrar variabilidade de concessão de memória devido ao potencial de valores estáticos devido ao cache do plano. No entanto, também podemos descobrir que, devido à recompilação, a consulta possui vários planos com valores de concessão de memória extremamente diferentes que poderíamos usar para rastrear o problema. Há várias maneiras de investigar o problema usando os dados capturados no Repositório de Consultas e permite que você examine os problemas de forma proativa e reativa.