A paginação é um caso de uso comum em aplicativos cliente e da Web em todos os lugares. O Google mostra 10 resultados por vez, seu banco on-line pode mostrar 20 contas por página e o software de rastreamento de bugs e controle de origem pode exibir 50 itens na tela.
Eu queria examinar a abordagem de paginação comum no SQL Server 2012 – OFFSET / FETCH (um padrão equivalente à cláusula LIMIT prioritária do MySQL) – e sugerir uma variação que levará a um desempenho de paginação mais linear em todo o conjunto, em vez de apenas ser ideal no inicio. O que, infelizmente, é tudo o que muitas lojas vão testar.
O que é paginação no SQL Server?
Com base na indexação da tabela, nas colunas necessárias e no método de classificação escolhido, a paginação pode ser relativamente fácil. Se você estiver procurando os "primeiros" 20 clientes e o índice clusterizado oferecer suporte a essa classificação (digamos, um índice clusterizado em uma coluna IDENTITY ou em uma coluna DateCreated), a consulta será relativamente eficiente. Se você precisar dar suporte à classificação que requer índices não clusterizados e, especialmente, se tiver colunas necessárias para saída que não são cobertas pelo índice (não importa se não houver índice de suporte), as consultas podem ficar mais caras. E mesmo a mesma consulta (com um parâmetro @PageNumber diferente) pode ficar muito mais cara à medida que o @PageNumber aumenta – já que mais leituras podem ser necessárias para chegar a essa "fatia" dos dados.
Alguns dirão que progredir até o final do conjunto é algo que você pode resolver colocando mais memória no problema (assim você elimina qualquer E/S física) e/ou usando cache em nível de aplicativo (assim você não vai o banco de dados). Vamos supor para os propósitos deste post que mais memória nem sempre é possível, já que nem todo cliente pode adicionar RAM a um servidor que está sem slots de memória ou que não está sob seu controle, ou apenas estalar os dedos e ter servidores mais novos e maiores prontos ir. Especialmente porque alguns clientes estão na Standard Edition, portanto, são limitados a 64 GB (SQL Server 2012) ou 128 GB (SQL Server 2014), ou estão usando edições ainda mais limitadas, como Express (1 GB) ou uma das muitas ofertas de nuvem.
Então, eu queria examinar a abordagem de paginação comum no SQL Server 2012 – OFFSET / FETCH – e sugerir uma variação que levará a um desempenho de paginação mais linear em todo o conjunto, em vez de ser ideal apenas no início. O que, infelizmente, é tudo o que muitas lojas vão testar.
Configuração/Exemplo de Dados de Paginação
Vou pegar emprestado de outro post, Maus hábitos:concentrando-se apenas no espaço em disco ao escolher chaves, onde preenchi a seguinte tabela com 1.000.000 linhas de dados de clientes aleatórios (mas não totalmente realistas):
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Como eu sabia que estaria testando E/S aqui, e estaria testando de um cache quente e frio, tornei o teste pelo menos um pouco mais justo reconstruindo todos os índices para minimizar a fragmentação (como seria feito menos de forma disruptiva, mas regularmente, na maioria dos sistemas ocupados que executam qualquer tipo de manutenção de índice):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Após a reconstrução, a fragmentação chega agora em 0,05% – 0,17% para todos os índices (nível de índice =0), as páginas são preenchidas acima de 99% e a contagem de linhas/páginas para os índices é a seguinte:
| Índice | Contagem de páginas | Contagem de linhas |
|---|---|---|
| C_PK_Customers_I (índice clusterizado) | 19.210 | 1.000.000 |
| C_Email_Customers_I | 7.344 | 1.000.000 |
| C_Active_Customers_I (índice filtrado) | 13.648 | 815.235 |
| C_Name_Customers_I | 16.824 | 1.000.000 |
Índices, contagens de páginas, contagens de linhas
Obviamente, essa não é uma tabela superlarga, e desta vez deixei a compressão de fora. Talvez eu explore mais configurações em um teste futuro.
Como paginar efetivamente uma consulta SQL
O conceito de paginação – mostrando ao usuário apenas linhas por vez – é mais fácil de visualizar do que explicar. Pense no índice de um livro físico, que pode ter várias páginas de referências a pontos dentro do livro, mas organizado em ordem alfabética. Para simplificar, digamos que dez itens caibam em cada página do índice. Isso pode se parecer com isso:
Agora, se eu já li as páginas 1 e 2 do índice, sei que para chegar à página 3, preciso pular 2 páginas. Mas como sei que há 10 itens em cada página, também posso pensar nisso como pular 2 x 10 itens e começar no 21º item. Ou, em outras palavras, preciso pular os primeiros (10*(3-1)) itens. Para tornar isso mais genérico, posso dizer que para começar na página n, preciso pular os primeiros (10 * (n-1)) itens. Para chegar à primeira página, pulo 10*(1-1) itens, para terminar no item 1. Para chegar à segunda página, pulo 10*(2-1) itens, para terminar no item 11. E assim em.
Com essas informações, os usuários formularão uma consulta de paginação como esta, já que as cláusulas OFFSET / FETCH adicionadas no SQL Server 2012 foram projetadas especificamente para pular tantas linhas:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Como mencionei acima, isso funciona muito bem se houver um índice que suporte o ORDER BY e que cubra todas as colunas na cláusula SELECT (e, para consultas mais complexas, as cláusulas WHERE e JOIN). No entanto, os custos de classificação podem ser esmagadores sem índice de suporte e, se as colunas de saída não forem cobertas, você acabará com um monte de pesquisas de chave ou poderá até obter uma verificação de tabela em alguns cenários.
Práticas recomendadas de classificação de paginação SQL
Dada a tabela e os índices acima, eu queria testar esses cenários, onde queremos mostrar 100 linhas por página e gerar todas as colunas da tabela:
- Padrão –
ORDER BY CustomerID(índice agrupado). Essa é a ordenação mais conveniente para o pessoal do banco de dados, pois não requer classificação adicional e todos os dados dessa tabela que podem ser necessários para exibição estão incluídos. Por outro lado, esse pode não ser o índice mais eficiente a ser usado se você estiver exibindo um subconjunto da tabela. O pedido também pode não fazer sentido para os usuários finais, especialmente se CustomerID for um identificador substituto sem significado externo. - Catálogo telefônico –
ORDER BY LastName, FirstName(suportando índice não clusterizado). Essa é a ordenação mais intuitiva para os usuários, mas exigiria um índice não agrupado para oferecer suporte à classificação e à cobertura. Sem um índice de suporte, a tabela inteira teria que ser verificada. - Definido pelo usuário –
ORDER BY FirstName DESC, EMail(sem índice de suporte). Isso representa a capacidade de o usuário escolher qualquer ordem de classificação que desejar, um padrão sobre o qual Michael J. Swart alerta em "Padrões de design de interface do usuário que não escalam".
Eu queria testar esses métodos e comparar planos e métricas quando – em cenários de cache quente e cache frio – olhar para a página 1, página 500, página 5.000 e página 9.999. Criei esses procedimentos (diferindo apenas pela cláusula ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail Na realidade, você provavelmente terá apenas um procedimento que usa SQL dinâmico (como no meu exemplo de “pia da cozinha”) ou uma expressão CASE para ditar a ordem.
Em ambos os casos, você poderá ver os melhores resultados usando OPTION (RECOMPILE) na consulta para evitar a reutilização de planos ideais para uma opção de classificação, mas não para todas. Eu criei procedimentos separados aqui para remover essas variáveis; Eu adicionei OPTION (RECOMPILE) para esses testes para ficar longe de sniffing de parâmetros e outros problemas de otimização sem liberar todo o cache do plano repetidamente.
Uma abordagem alternativa para paginação do SQL Server para melhor desempenho
Uma abordagem um pouco diferente, que não vejo implementada com muita frequência, é localizar a "página" em que estamos usando apenas a chave de cluster e, em seguida, juntar-se a ela:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
É um código mais detalhado, é claro, mas espero que esteja claro o que o SQL Server pode ser forçado a fazer:evitar uma varredura ou pelo menos adiar pesquisas até que um conjunto de resultados muito menor seja reduzido. Paul White (@SQL_Kiwi) investigou uma abordagem semelhante em 2010, antes de OFFSET/FETCH ser introduzido nos primeiros betas do SQL Server 2012 (eu publiquei pela primeira vez sobre isso no final daquele ano).
Diante dos cenários acima, criei mais três procedimentos, com a única diferença entre a(s) coluna(s) especificada(s) nas cláusulas ORDER BY (agora precisamos de duas, uma para a própria página e outra para ordenar o resultado):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Observação:isso pode não funcionar tão bem se sua chave primária não estiver em cluster – parte do truque que faz isso funcionar melhor, quando um índice de suporte pode ser usado, é que a chave de cluster já está no índice, então um a pesquisa geralmente é evitada.
Testando a classificação de chave de cluster
Primeiro, testei o caso em que não esperava muita variação entre os dois métodos – classificação pela chave de cluster. Eu executei essas instruções em um lote no SQL Sentry Plan Explorer e observei a duração, as leituras e os planos gráficos, certificando-me de que cada consulta estava começando de um cache completamente frio:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
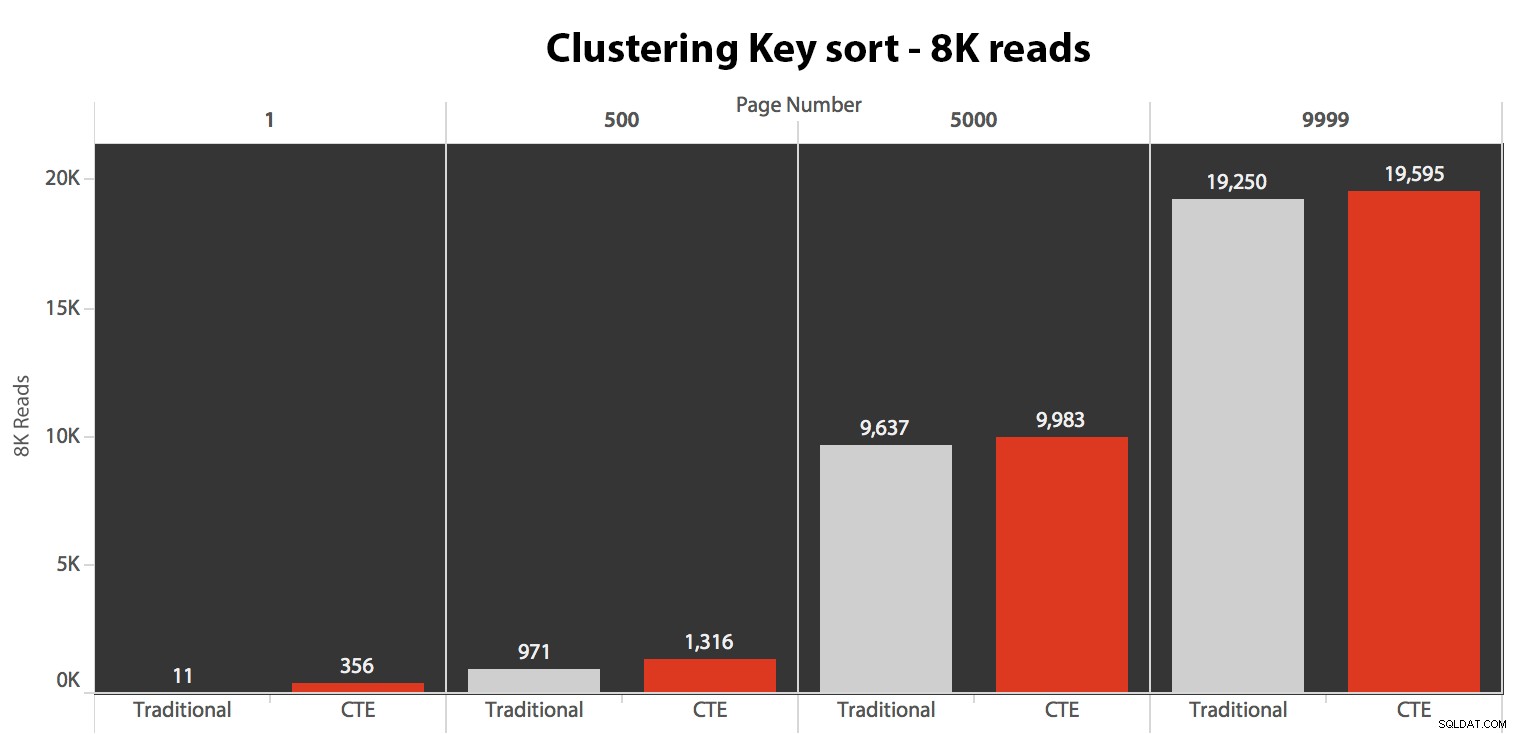
Os resultados aqui não foram surpreendentes. Acima de 5 execuções, o número médio de leituras é mostrado aqui, mostrando diferenças insignificantes entre as duas consultas, em todos os números de página, ao classificar pela chave de clustering:
O plano para o método padrão (como mostrado no Plan Explorer) em todos os casos foi o seguinte:
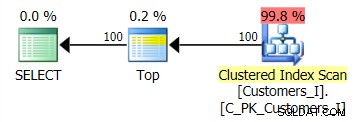
Enquanto o plano para o método baseado em CTE era assim:
Agora, enquanto a E/S era a mesma independentemente do cache (apenas muito mais leituras antecipadas no cenário de cache frio), eu medi a duração com um cache frio e também com um cache quente (onde comentei os comandos DROPCLEANBUFFERS e executou as consultas várias vezes antes de medir). Essas durações ficaram assim:
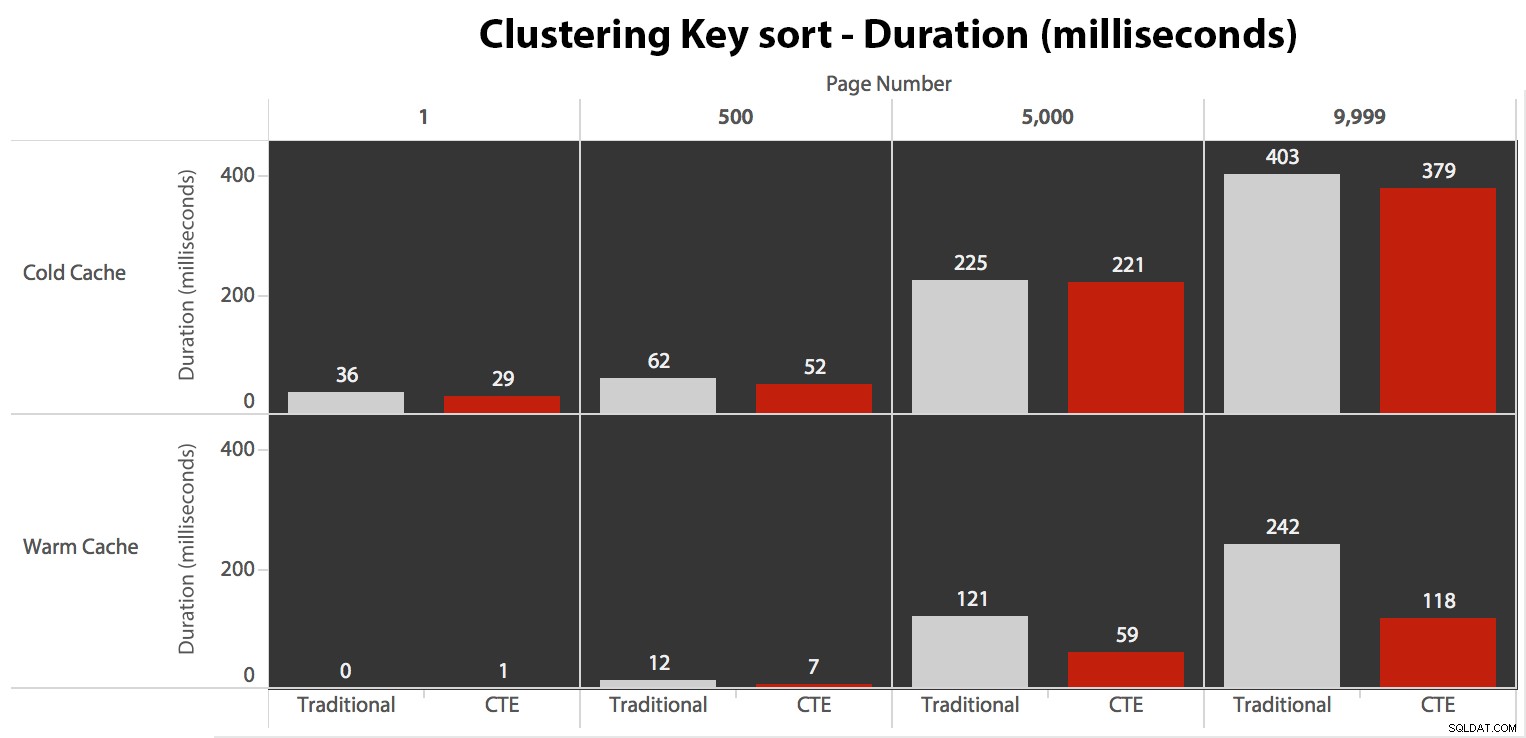
Embora você possa ver um padrão que mostra a duração aumentando à medida que o número da página aumenta, lembre-se da escala:para atingir as linhas 999.801 -> 999.900, estamos falando de meio segundo no pior caso e 118 milissegundos no melhor caso. A abordagem CTE vence, mas não por muito.
Testando a classificação da lista telefônica
Em seguida, testei o segundo caso, em que a classificação era suportada por um índice não abrangente em LastName, FirstName. A consulta acima acabou de alterar todas as instâncias de
Test_1 para Test_2 . Aqui estavam as leituras usando um cache frio: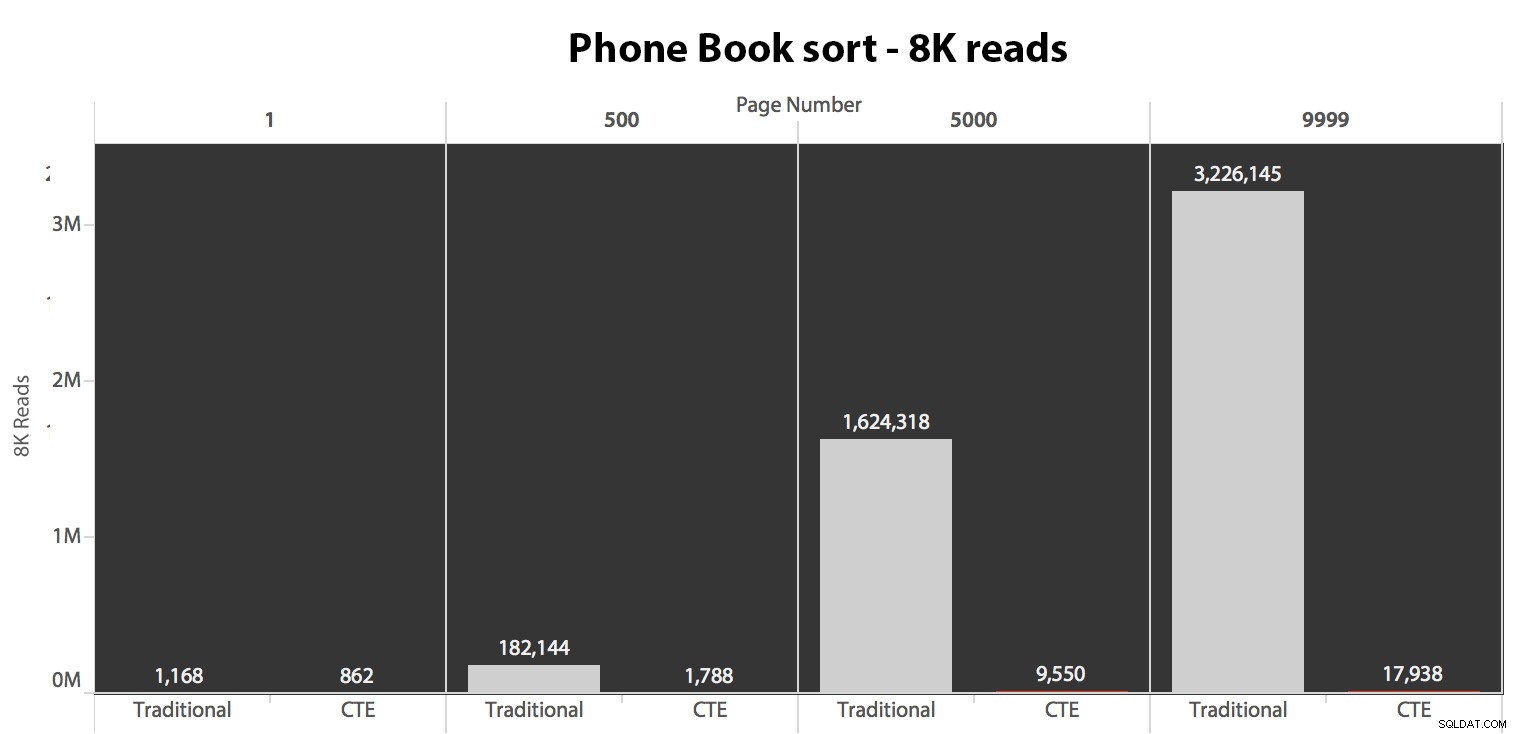
(As leituras em um cache quente seguiram o mesmo padrão – os números reais diferiram um pouco, mas não o suficiente para justificar um gráfico separado.)
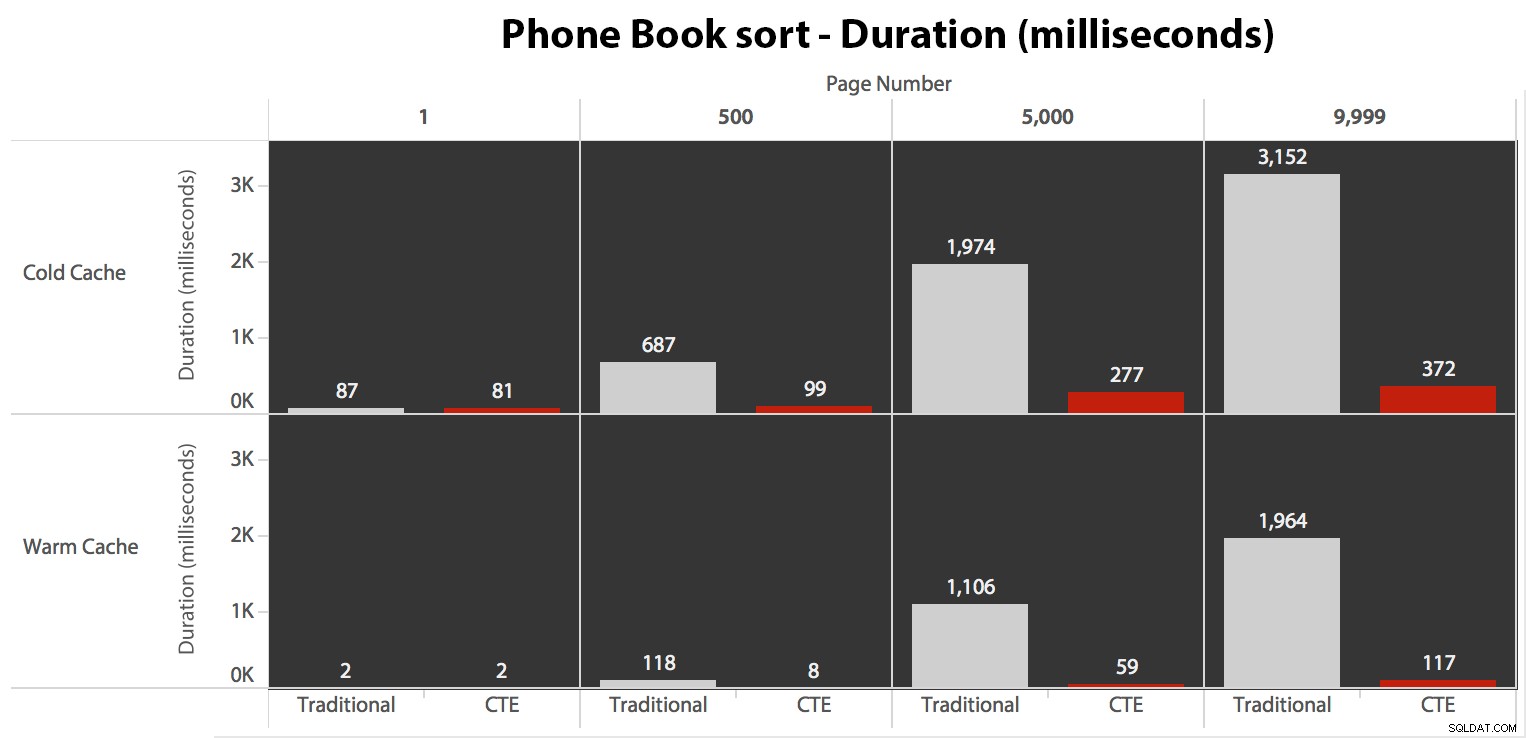
Quando não estamos usando o índice clusterizado para classificar, fica claro que os custos de E/S envolvidos com o método tradicional de OFFSET/FETCH são muito piores do que quando identificamos as chaves primeiro em um CTE e puxamos o restante das colunas apenas para esse subconjunto.
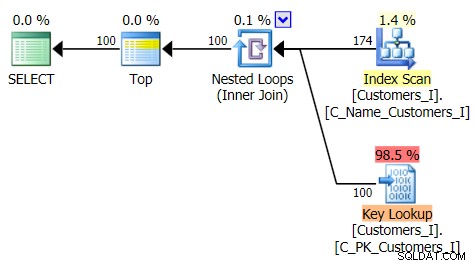
Aqui está o plano para a abordagem de consulta tradicional:
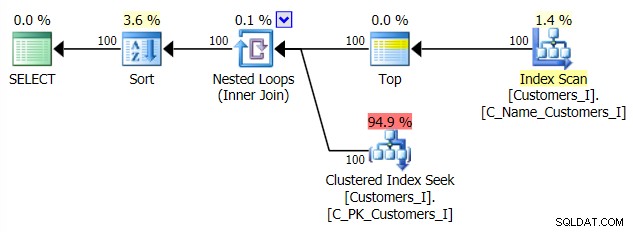
E o plano para minha abordagem alternativa CTE:
Por fim, as durações:
A abordagem tradicional mostra um aumento muito óbvio na duração à medida que você avança para o final da paginação. A abordagem CTE também mostra um padrão não linear, mas é muito menos pronunciado e produz um melhor tempo em cada número de página. Vemos 117 milissegundos para a penúltima página, contra a abordagem tradicional chegando em quase dois segundos.
Testando a classificação definida pelo usuário
Por fim, alterei a consulta para usar o
Test_3 procedimentos armazenados, testando o caso em que a classificação foi definida pelo usuário e não teve um índice de suporte. A E/S foi consistente em cada conjunto de testes; o gráfico é tão desinteressante, eu vou ligar para ele. Para encurtar a história:houve pouco mais de 19.000 leituras em todos os testes. A razão é porque cada variação teve que realizar uma varredura completa devido à falta de um índice para suportar a ordenação. Aqui está o plano para a abordagem tradicional: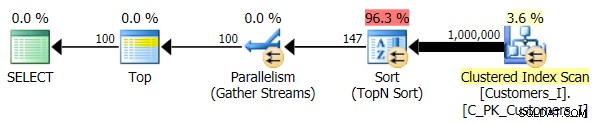
E enquanto o plano para a versão CTE da consulta parece assustadoramente mais complexo…
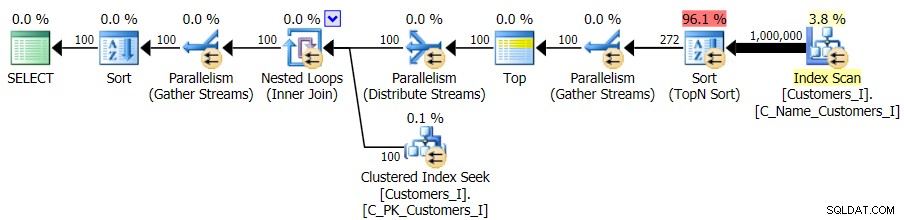
…isso leva a durações mais baixas em todos os casos, exceto em um. Aqui estão as durações:
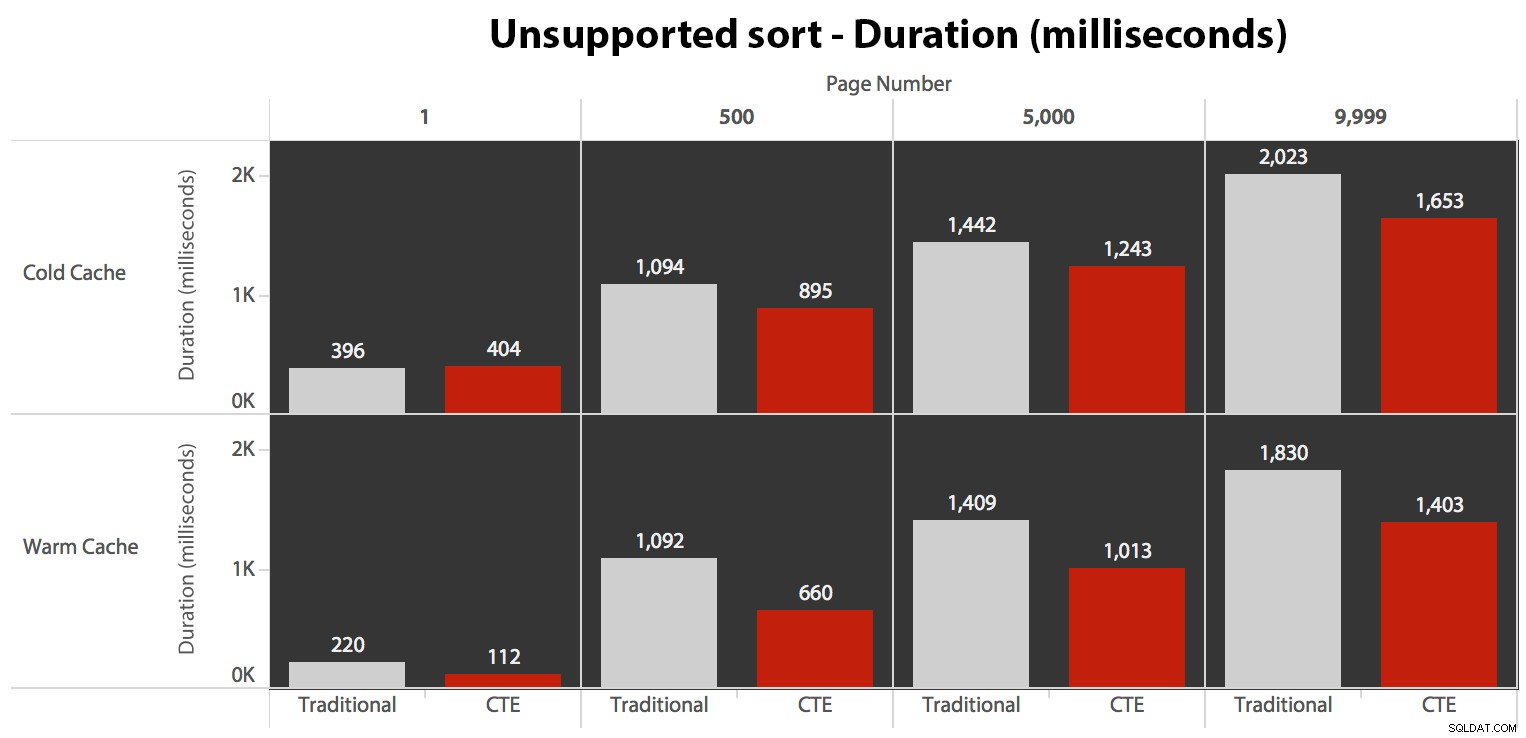
Você pode ver que não podemos obter desempenho linear aqui usando nenhum dos métodos, mas o CTE sai no topo por uma boa margem (de 16% a 65% melhor) em todos os casos, exceto na consulta de cache frio em relação ao primeiro página (onde perdeu por uns colossais 8 milissegundos). Também é interessante notar que o método tradicional não é muito ajudado por um cache quente no "meio" (páginas 500 e 5000); apenas no final do conjunto é que vale a pena mencionar alguma eficiência.
Volume mais alto
Após testes individuais de algumas execuções e tirar médias, achei que também faria sentido testar um alto volume de transações que simulariam um pouco o tráfego real em um sistema ocupado. Então, criei um trabalho com 6 etapas, uma para cada combinação de método de consulta (paginação tradicional vs. CTE) e tipo de classificação (chave de cluster, catálogo telefônico e não suportado), com uma sequência de 100 etapas para atingir os quatro números de página acima , 10 vezes cada, e 60 outros números de página escolhidos aleatoriamente (mas o mesmo para cada passo). Aqui está como eu gerei o script de criação de trabalho:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Aqui está a lista de etapas de trabalho resultante e uma das propriedades da etapa:
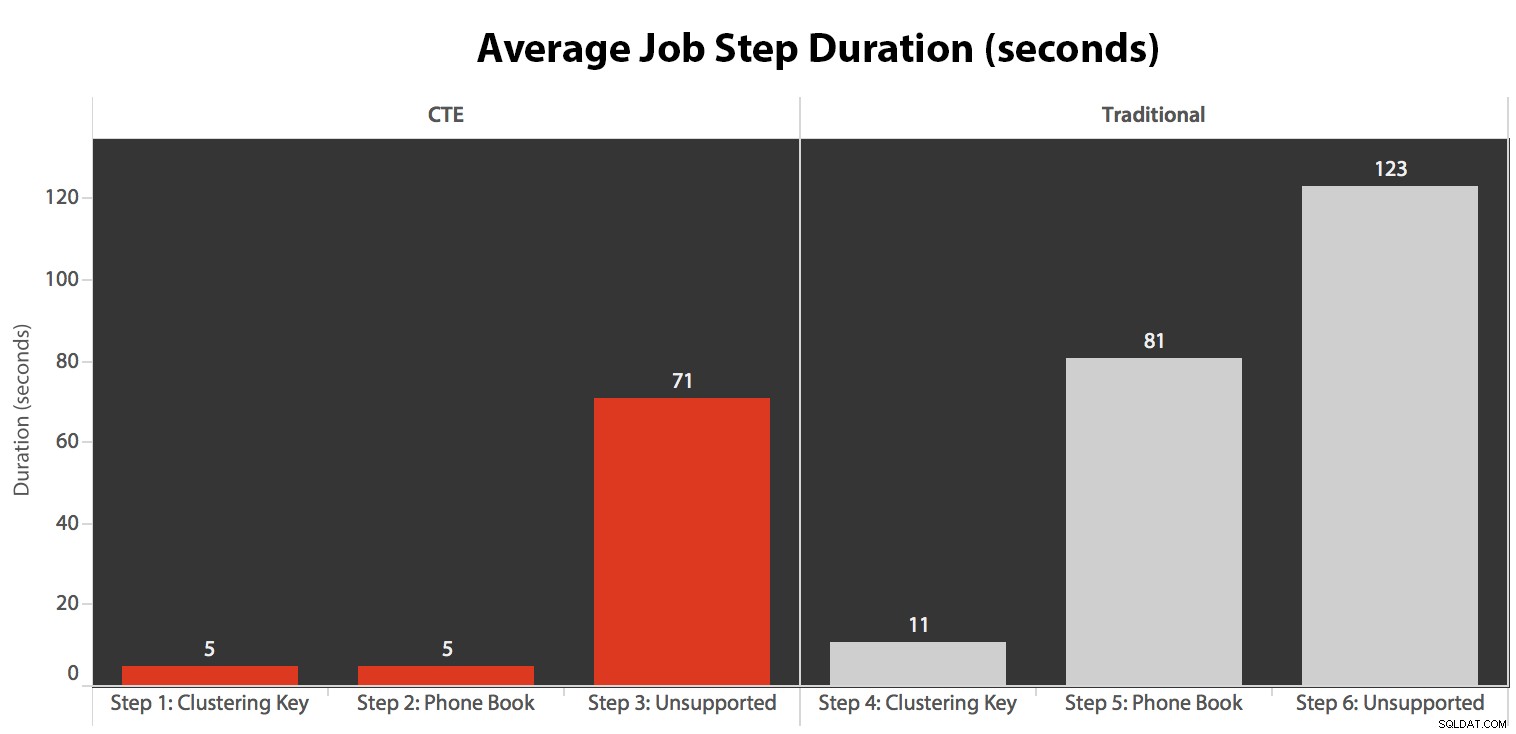
Executei o trabalho cinco vezes, depois revisei o histórico do trabalho e aqui estavam os tempos de execução médios de cada etapa:
Também correlacionei uma das execuções no calendário do SQL Sentry Event Manager…
…com o painel do SQL Sentry e marcou manualmente aproximadamente onde cada uma das seis etapas foi executada. Aqui está o gráfico de uso da CPU do lado do Windows do painel:
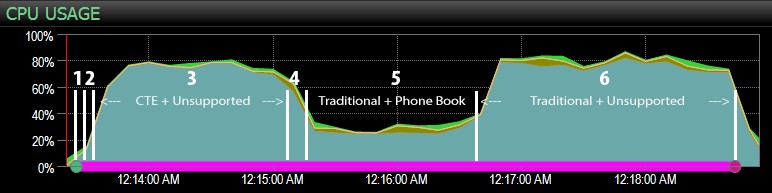
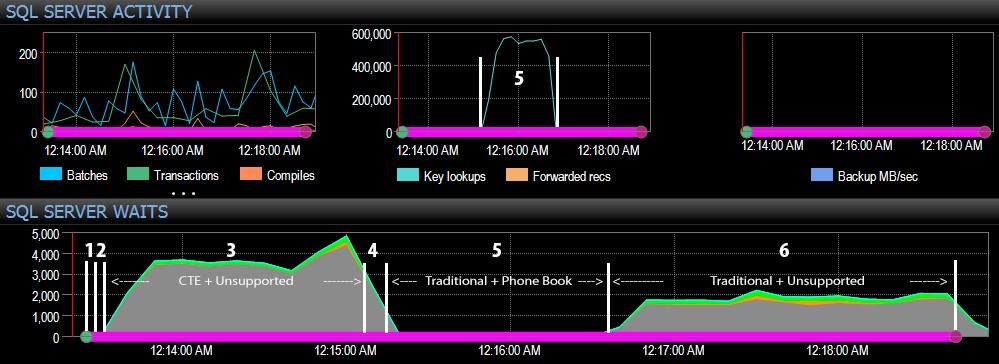
E do lado do SQL Server do painel, as métricas interessantes estavam nos gráficos Key Lookups and Waits:
As observações mais interessantes apenas de uma perspectiva puramente visual:
- A CPU está muito quente, em torno de 80%, durante a etapa 3 (CTE + sem índice de suporte) e a etapa 6 (tradicional + sem índice de suporte);
- As esperas de CXPACKET são relativamente altas durante a etapa 3 e em menor grau durante a etapa 6;
- você pode ver o grande salto nas pesquisas principais, para quase 600.000, em cerca de um minuto (correlacionando com a etapa 5 – a abordagem tradicional com um índice no estilo de lista telefônica).
Em um teste futuro – como no meu post anterior sobre GUIDs – gostaria de testar isso em um sistema onde os dados não cabem na memória (fácil de simular) e onde os discos são lentos (não tão fáceis de simular) , já que alguns desses resultados provavelmente se beneficiam de coisas que nem todo sistema de produção possui – discos rápidos e RAM suficiente. Eu também deveria expandir os testes para incluir mais variações (usando colunas finas e largas, índices finos e largos, um índice de catálogo telefônico que realmente cobre todas as colunas de saída e classificação em ambas as direções). A fluência do escopo definitivamente limitou a extensão dos meus testes para este primeiro conjunto de testes.
Como melhorar a paginação do SQL Server
A paginação nem sempre precisa ser dolorosa; O SQL Server 2012 certamente facilita a sintaxe, mas se você apenas conectar a sintaxe nativa, nem sempre verá um grande benefício. Aqui eu mostrei que uma sintaxe um pouco mais detalhada usando um CTE pode levar a um desempenho muito melhor no melhor caso, e diferenças de desempenho indiscutivelmente insignificantes no pior caso. Ao separar a localização de dados da recuperação de dados em duas etapas diferentes, podemos ver um tremendo benefício em alguns cenários, fora das esperas CXPACKET mais altas em um caso (e mesmo assim, as consultas paralelas terminaram mais rapidamente do que as outras consultas exibindo pouca ou nenhuma espera, então é improvável que eles sejam os "ruins" que o CXPACKET espera que todos avisam).
Ainda assim, mesmo o método mais rápido é lento quando não há índice de suporte. Embora você possa ficar tentado a implementar um índice para cada algoritmo de classificação possível que um usuário possa escolher, você pode considerar fornecer menos opções (já que todos sabemos que os índices não são gratuitos). Por exemplo, seu aplicativo absolutamente precisa dar suporte à classificação por sobrenome ascendente *e* sobrenome decrescente? Se eles quiserem ir diretamente aos clientes cujos sobrenomes começam com Z, eles não podem ir para a *última* página e trabalhar para trás? Essa é uma decisão de negócios e usabilidade mais do que técnica, apenas mantenha-a como uma opção antes de colocar índices em cada coluna de classificação, em ambas as direções, para obter o melhor desempenho até mesmo para as opções de classificação mais obscuras.



