Você pensa em algo quando cria um novo banco de dados? Acho que a maioria de vocês diria que não, já que todos usamos parâmetros padrão, embora estejam longe de serem ideais. No entanto, existem várias configurações de disco e elas realmente ajudam a aumentar a confiabilidade e o desempenho do sistema.
Não falaremos da importância do sistema de arquivos NTFS para a confiabilidade dos dados, embora esse sistema de arquivos permita que o MS SQL Server use o disco da maneira mais eficaz.
Se você está com poucos recursos e algo começa a funcionar lentamente, a primeira coisa que vem à mente é atualizar. Mas a atualização não é necessária em todos os casos. Você pode se safar com o ajuste, embora isso não deva ser feito quando o servidor começar a ficar lento, mas no estágio de design e instalação.
A otimização é um processo complexo e muitas vezes está relacionado não apenas a um determinado programa (no nosso caso, a um determinado banco de dados), mas também ao sistema operacional e ao hardware. Embora falaremos principalmente sobre bancos de dados, não podemos ignorar as coisas externas.
Arquitetura de dados
O SQL Server armazena, lê e grava dados por blocos de 8 KB cada. Esses blocos são chamados de páginas. Um banco de dados pode armazenar 128 páginas por megabyte (1 megabyte ou 1048576 bytes divididos por 8 kilobytes ou 8192 bytes). Todas as páginas são armazenadas em uma extensão. Uma extensão são as últimas 8 páginas sequenciais ou 64 KB. Assim, 1 megabyte armazena 16 extensões.
Páginas e extensões são a base da estrutura do banco de dados físico do SQL Server. O MS SQL Server usa vários tipos de página, alguns deles rastreiam o espaço alocado, alguns contêm dados e índices do usuário. As páginas que rastreiam o espaço alocado contêm os dados densamente compactados. Ele permite que o MS SQL Server os armazene efetivamente na memória para facilitar a leitura.
O SQL Server usa dois tipos de extensões:
- Extensões que armazenam páginas de dois a muitos objetos são chamadas de extensões mistas. Cada tabela começa como uma extensão mista. Você usa extensão mista principalmente para as páginas que armazenam espaço e contêm pequenos objetos.
- As extensões que têm todas as 8 páginas alocadas para um objeto são chamadas de extensões uniformes. Eles são usados quando uma tabela ou índice requer mais de 64 KB.
A primeira extensão para cada arquivo é uniforme e contém páginas do cabeçalho do arquivo, as próximas extensões contêm 3 páginas alocadas cada. O servidor aloca essas extensões mistas quando você cria um arquivo de dados básico e usa essas páginas para suas tarefas internas. A página de cabeçalho do arquivo contém atributos de arquivo, como o nome do banco de dados armazenado no arquivo, grupo de arquivos, tamanho mínimo, tamanho do incremento. Esta é a primeira página de cada arquivo (página 0).
Plano de execução de consulta no SQL Query Analyzer
Espaço livre na página (PFS ) em uma página alocada que contém informações sobre o espaço livre disponível no arquivo. Essas informações são armazenadas na página 1. Cada uma dessas páginas pode se estender até 8.000 páginas contíguas, o que equivale a aproximadamente 64 Mb de dados.
O log de transações coleta todas as informações sobre as alterações que ocorrem no servidor para restaurar um banco de dados no momento do erro do sistema e garantir a integridade dos dados.
Observe que todos os números são múltiplos de 8 ou 16. Isso ocorre porque o controlador de disco rígido lê dados desse tamanho com mais facilidade. Os dados são lidos do disco por páginas, ou seja, por 8 kilobytes, o que é um valor bastante ideal.
Proteção de página
A partir do MS SQL Server 2005, o servidor de banco de dados apresenta uma nova opção – o controle de dados em nível de página. Se o AGE_VERIFY_CHECKSUM estiver habilitado (é habilitado por padrão), o servidor controlará as somas de verificação das páginas. Se olharmos no manual para este parâmetro, veremos que a soma de verificação permite rastrear os erros de entrada/saída que o SO não consegue rastrear. Que tipo de erros são eles? Parece que são problemas internos do servidor de banco de dados.
A verificação de integridade de dados nunca falha, por isso é melhor habilitá-la. Para isso, precisamos executar o seguinte comando:
ALTER DATABASE имя базы SET PAGE_VERIFY
Se houver um erro na página, o servidor nos notificará sobre isso. Mas como podemos corrigi-lo rapidamente? Existe uma opção para restaurar dados no nível da página para isso.
Plano de execução gráfica
Crescimento do arquivo
Quando criamos um banco de dados, somos solicitados a selecionar o tamanho inicial e o método de incremento. Quando estamos com falta de espaço atual, o servidor o estende em correspondência com o método de incremento predefinido.
Existem três métodos de incremento para arquivos:
- Crescimento em megabytes.
- Crescimento percentual.
- Crescimento manual.
Os dois primeiros métodos são executados automaticamente, mas são recomendados apenas para bancos de dados de teste, pois um administrador não tem controle sobre o tamanho do arquivo.
Se um arquivo é incrementado em uma certa quantidade de megabytes, em algum momento, a velocidade de inserção de dados pode aumentar e o crescimento do arquivo pode se tornar muito frequente, e isso é um custo extra. O crescimento de arquivos em porcentagens também não é lucrativo. Recomenda-se usar um crescimento de arquivo de 10% e isso é bom para bancos de dados pequenos e médios. Mas quando atingir 1000 gigabytes, serão necessários 100 gigabytes em cada crescimento. Isso levará a um desperdício sem sentido de espaço em disco.
Sempre controle as alterações no tamanho dos arquivos e logs de transações. Ele permitirá que você use os recursos do disco da maneira mais eficaz.
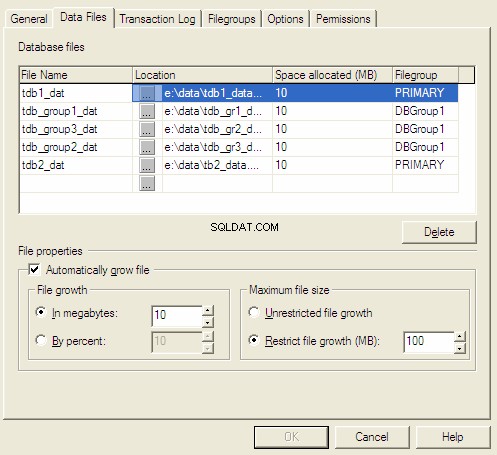
Propriedades do banco de dados MS SQL Server
Compressão de dados
O disco rígido continua sendo um ponto sensível de um computador. O desempenho dos processadores cresce vertiginosamente, enquanto os discos rígidos não podem oferecer algo novo. Para salvar o número de operações de entrada/saída e reduzir os dados armazenados no disco rígido, você pode usar discos com compactação. Apenas esses discos são bons para armazenar grupos de arquivos somente leitura. Talvez seja porque a compactação é necessária para gravações e exige custos adicionais do processador.
A compactação de dados e o estado somente leitura são bons para os dados de arquivamento. Por exemplo, os dados contábeis dos últimos anos não são necessários para a gravação e podem ocupar muito espaço. Ao colocar dados na seção de arquivamento do disco, você economizará muito espaço.
Discos para confiabilidade
O método a seguir permite aumentar a confiabilidade e o desempenho ao mesmo tempo e, novamente, está relacionado aos discos rígidos. Bem, aí está, a mecânica não é apenas a mais lenta, mas a menos confiável. Quanto à confiabilidade, não coletei as estatísticas, mas tanto em casa quanto no trabalho, lido principalmente com discos rígidos.
Portanto, para aumentar o desempenho e a confiabilidade, você pode simplesmente usar dois ou mais discos rígidos em vez de um. Será ainda melhor se eles forem conectados a controladores separados. Você pode armazenar o banco de dados em um disco e os logs de transações em outro. Se houver um terceiro disco, ele pode armazenar o sistema.
Armazenar dados e um log em discos separados permite aumentar muito a confiabilidade. Suponha que você tenha tudo em um disco e ele fique inativo. O que fazer? Você pode chegar a uma empresa que vai tentar recuperar tudo ou tentar fazer o mesmo por conta própria, mas a chance de recuperação está longe de ser 100%. Além disso, o retorno do servidor ao trabalho pode levar um volume considerável de tempo. A recuperação rápida só pode ser feita até o momento da última cópia de backup. O resto é questionável.
E agora, suponha que você tenha dados e um log de transações em discos diferentes. Se o disco com o log desligar, os dados ainda estarão lá. A única coisa é que você não pode adicionar novos dados, mas se você criar um novo log, poderá continuar trabalhando.
Se o disco com dados desligar, ainda podemos reservar o log de transações para evitar a menor perda de dados. Depois disso, recuperamos os dados do backup completo (deve ser feito sempre antes, um bom administrador faz isso pelo menos uma vez por dia) e adicionamos as alterações da cópia de backup do log.
Discos para desempenho
Se os dados e um log estiverem localizados em discos separados, isso significa não apenas segurança, mas também aumento de desempenho. O fato é que o servidor de banco de dados pode gravar dados simultaneamente no arquivo de log e de dados.
Podemos ir além e alocar um disco rígido para o log de transações e vários discos rígidos para dados. O servidor trabalha com dados com mais frequência, por isso requer vários armazenamentos com os quais você pode trabalhar ao mesmo tempo. E se esses storages estiverem conectados a controladores diferentes, o trabalho simultâneo é garantido.
A variante mais rápida e confiável é usar RAID . No entanto, nem todos os RAID é confiável e rápido ao mesmo tempo. Para os grupos de arquivos, é recomendável escolher RAID10 , pois contém recursos bem balanceados, mas dependendo dos dados do banco de dados, você pode escolher outra variante.
Você pode usar uma solução de software ou hardware como RAID . Uma solução de software é mais barata, mas requer recursos extras de CPU. E um processador não tem recursos sobressalentes. É por isso que é melhor usar soluções de hardware onde um chip dedicado é responsável pelo RAID .
Índices
Todo mundo sabe que os índices ajudam a aumentar a velocidade de busca de dados. A maioria de nós entende que os índices afetam negativamente a inserção e atualização de dados, portanto, quanto mais índices você tiver, mais difícil será para o servidor mantê-los. Com isso, muitos nem pensam que os índices exigem manutenção. As páginas do banco de dados que contêm dados de índice podem transbordar e, eventualmente, ficar desequilibradas.
Sim, podemos ignorar vários parâmetros e simplesmente recriar índices uma vez por mês, o que é semelhante à manutenção. O SQL Server inclui dois parâmetros que impedem que os índices desatualizem meia hora após sua criação:FILLFACTOR e PAD_INDEX .
Você pode usar a opção FILLFACTOR para otimizar o desempenho das operações de inserção e atualização que contêm um índice clusterizado ou não clusterizado. Os dados de índice podem ser armazenados em muitas páginas de dados. Como mencionei acima, cada página consiste em 8 KB. Quando uma página de índice está cheia, o servidor cria uma nova página e divide a página para a inserção de dados em duas.
O servidor requer tempo para a divisão da página e criação de uma nova página. Para otimizar a divisão da página, use o FILLFACTOR opção para determinar a porcentagem de espaço livre em todas as folhas da página de índice. Quanto maior o espaço em disco das páginas em nível de folha, menos frequentemente você terá que dividir as páginas de índice. Com isso, a árvore de índice será muito grande e seu desvio levará mais tempo.
O PAD_INDEX opção indica a porcentagem de preenchimento das páginas não folha. Você pode usar PAD_INDEX somente quando o FILLFACTOR opção é especificada, pois o valor percentual de PAD_INDEX depende da porcentagem especificada em FILLFACTOR .
Estatísticas
As estatísticas permitem que o servidor tome a decisão certa entre o uso do índice e a verificação completa da tabela. Suponha que você tenha uma lista de funcionários de uma fundição. Tal lista será composta por aproximadamente 90% dos homens.
Agora, suponha que precisamos encontrar todas as mulheres. Como não há muitos deles, a opção mais eficaz será usar o índice. Mas se precisarmos encontrar todos os homens, a eficiência do índice diminui. O número de registros selecionados é muito grande e ignorar a árvore de índice para cada um deles será uma sobrecarga. É muito mais fácil varrer toda a tabela inteira – a execução será muito mais rápida, pois o servidor precisará ler todas as folhas de baixo nível do índice uma vez sem a necessidade de várias leituras de todos os níveis.
O SQL Server coleta estatísticas lendo todos os valores de campo ou com um modelo para criação da lista de valores classificada e distribuída uniformemente. O SQL Server detecta dinamicamente a porcentagem de linhas que devem ser testadas com base no número de linhas na tabela. Ao coletar estatísticas, o otimizador de consulta executará uma varredura completa ou modelos de linha.
Para que as estatísticas funcionem, elas devem ser criadas. Em caso de atualização massiva de dados, as estatísticas podem conter dados incorretos e o servidor tomará uma decisão errada. Mas tudo pode ser corrigido – você precisa monitorar as estatísticas. Para obter informações mais detalhadas, consulte os livros sobre Transact-SQL ou MS SQL Server.
Resumo
As configurações padrão não permitem usar todo o potencial do hardware e funcionam com toda a variedade de servidores. A responsabilidade pelas configurações é dos administradores. O fato de os produtos da Microsoft terem programas de instalação simples, utilitários de administração gráfica e capacidade de trabalhar offline não significa que esta seja uma variante ideal.
Não consideramos essas opções de ajuste de banco de dados como aceleração de hardware. Se todas as opções de ajuste estiverem esgotadas, é melhor pensar na atualização, pois a aceleração de hardware afeta negativamente a confiabilidade do sistema.
O mais importante é que qualquer otimização do servidor de banco de dados ou qualquer atualização não ajudará se as consultas não forem otimizadas.