Ao ajustar o
postgresql.conf , você deve ter notado que há uma opção chamada full_page_writes . O comentário ao lado dele diz algo sobre gravações parciais de página, e as pessoas geralmente o deixam definido como on – o que é uma coisa boa, como explicarei mais adiante neste post. No entanto, é útil entender o que as gravações de página inteira fazem, porque o impacto no desempenho pode ser bastante significativo. Ao contrário do meu post anterior sobre ajuste de ponto de verificação, este não é um guia de como ajustar o servidor. Não há muito que você possa ajustar, na verdade, mas mostrarei como algumas decisões no nível do aplicativo (por exemplo, escolha de tipos de dados) podem interagir com gravações de página inteira.
Gravações Parciais/Páginas Rasgadas
Então, sobre o que são escritos de página inteira? Como o comentário em
postgresql.conf diz que é uma maneira de se recuperar de gravações de páginas parciais – o PostgreSQL usa páginas de 8kB (por padrão), mas outras partes da pilha usam tamanhos de blocos diferentes. Os sistemas de arquivos Linux normalmente usam páginas de 4kB (é possível usar páginas menores, mas 4kB é o máximo em x86), e no nível de hardware as unidades antigas usavam setores de 512B, enquanto os novos dispositivos geralmente gravam dados em pedaços maiores (geralmente 4kB ou até 8kB) . Assim, quando o PostgreSQL escreve a página de 8kB, as outras camadas da pilha de armazenamento podem dividi-la em partes menores, gerenciadas separadamente. Isso apresenta um problema em relação à atomicidade da gravação. A página de 8kB do PostgreSQL pode ser dividida em duas páginas de sistema de arquivos de 4kB e, em seguida, em setores de 512B. Agora, e se o servidor travar (falha de energia, bug do kernel, …)?
Mesmo que o servidor use sistema de armazenamento projetado para lidar com tais falhas (SSDs com capacitores, controladores RAID com baterias, …), o kernel já divide os dados em páginas de 4kB. Portanto, é possível que o banco de dados tenha gravado uma página de dados de 8kB, mas apenas parte disso chegou ao disco antes da falha.
Neste ponto, você provavelmente está pensando que é exatamente por isso que temos o log de transações (WAL), e você está certo! Assim, após iniciar o servidor, o banco de dados lerá WAL (desde o último checkpoint concluído) e aplicará as alterações novamente para garantir que os arquivos de dados estejam completos. Simples.
Mas há um problema - a recuperação não aplica as alterações cegamente, muitas vezes precisa ler as páginas de dados etc. O que parece um pouco autocontraditório, porque para corrigir a corrupção de dados assumimos que não há corrupção de dados.
As gravações de página inteira são uma maneira de contornar esse enigma – ao modificar uma página pela primeira vez após um ponto de verificação, a página inteira é gravada no WAL. Isso garante que, durante a recuperação, o primeiro registro WAL que tocar em uma página contenha a página inteira, eliminando a necessidade de ler a página – possivelmente quebrada – do arquivo de dados.
Gravação de amplificação
Obviamente, a consequência negativa disso é o aumento do tamanho do WAL – alterar um único byte na página de 8kB registrará o todo no WAL. A gravação de página inteira só acontece na primeira gravação após um ponto de verificação, portanto, tornar os pontos de verificação menos frequentes é uma maneira de melhorar a situação - normalmente, há uma breve "explosão" de gravações de página inteira após um ponto de verificação e, em seguida, relativamente poucas gravações de página inteira até o final de um posto de controle.
UUID x chaves BIGSERIAL
Mas há algumas interações inesperadas com decisões de design feitas no nível do aplicativo. Vamos supor que temos uma tabela simples com chave primária, seja um
BIGSERIAL ou UUID , e inserimos dados nele. Haverá uma diferença na quantidade de WAL gerada (assumindo que inserimos o mesmo número de linhas)? Parece razoável esperar que ambos os casos produzam aproximadamente a mesma quantidade de WAL, mas como os gráficos a seguir ilustram, há uma enorme diferença na prática.
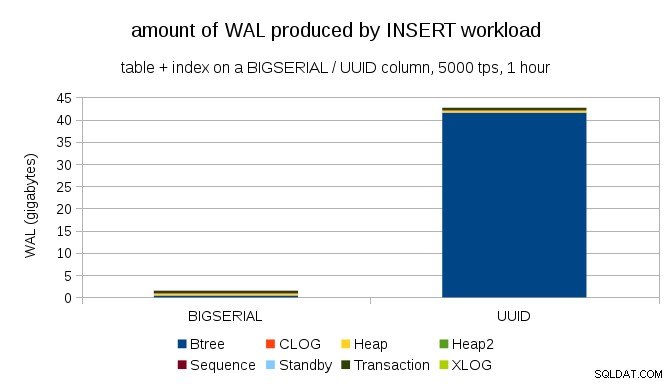
Isso mostra a quantidade de WAL produzida durante um benchmark de 1h, estrangulado para 5.000 inserções por segundo. Com
BIGSERIAL chave primária isso produz ~ 2 GB de WAL, enquanto com UUID é mais de 40GB. Essa é uma diferença bastante significativa e, claramente, a maior parte do WAL está associada ao índice que respalda a chave primária. Vamos olhar como tipos de registros WAL. 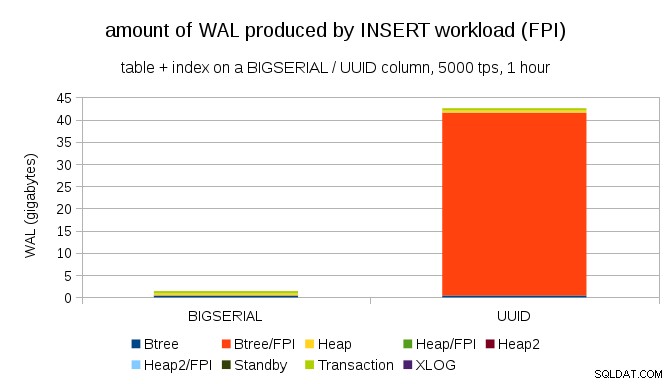
Claramente, a grande maioria dos registros são imagens de página inteira (FPI), ou seja, o resultado de gravações de página inteira. Mas por que isso está acontecendo?
Claro, isso se deve ao
UUID inerente aleatoriedade. Com BIGSERIAL new são sequenciais e, portanto, são inseridos nas mesmas páginas folha no índice btree. Como apenas a primeira modificação em uma página aciona a gravação de página inteira, apenas uma pequena fração dos registros WAL são FPIs. Com UUID é um caso completamente diferente, é claro - os valores não são sequenciais, na verdade, cada inserção provavelmente tocará uma página de folha de índice de folha completamente nova (supondo que o índice seja grande o suficiente). Não há muito que o banco de dados possa fazer – a carga de trabalho é simplesmente aleatória por natureza, acionando muitas gravações de página inteira.
Não é difícil obter amplificação de gravação semelhante, mesmo com
BIGSERIAL chaves, é claro. Requer apenas uma carga de trabalho diferente - por exemplo, com UPDATE carga de trabalho, atualizando os registros aleatoriamente com distribuição uniforme, o gráfico fica assim: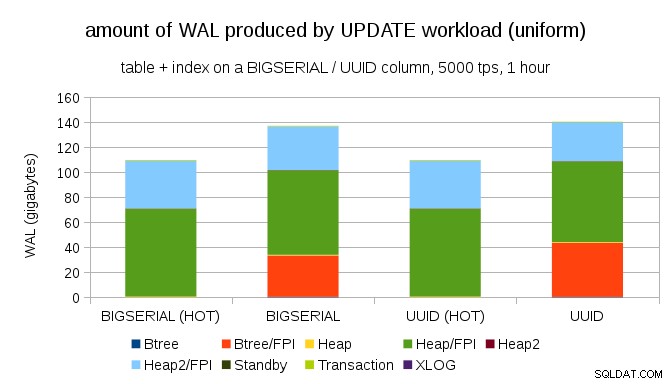
De repente, as diferenças entre os tipos de dados desaparecem – o acesso é aleatório em ambos os casos, resultando em quase exatamente a mesma quantidade de WAL produzida. Outra diferença é que a maior parte do WAL está associada a “heap”, ou seja, tabelas, e não a índices. Os casos “HOT” foram projetados para permitir a otimização HOT UPDATE (ou seja, atualizar sem ter que tocar em um índice), o que praticamente elimina todo o tráfego WAL relacionado ao índice.
Mas você pode argumentar que a maioria dos aplicativos não atualiza todo o conjunto de dados. Normalmente, apenas um pequeno subconjunto de dados está “ativo” – as pessoas acessam apenas postagens dos últimos dias em um fórum de discussão, pedidos não resolvidos em uma loja virtual etc. Como isso altera os resultados?
Felizmente, o pgbench suporta distribuições não uniformes e, por exemplo, com distribuição exponencial tocando 1% do subconjunto de dados ~ 25% do tempo, o gráfico fica assim:
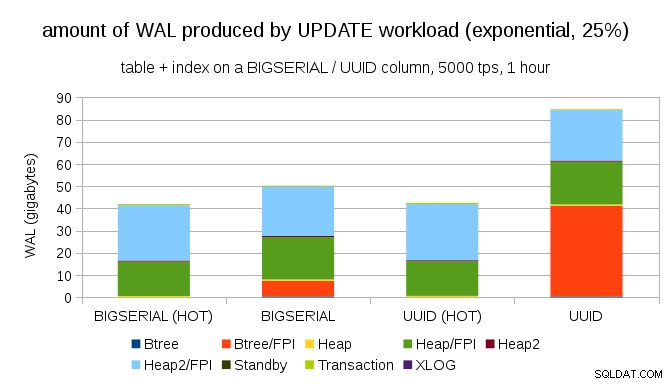
E depois de tornar a distribuição ainda mais distorcida, tocando o subconjunto de 1% ~ 75% das vezes:
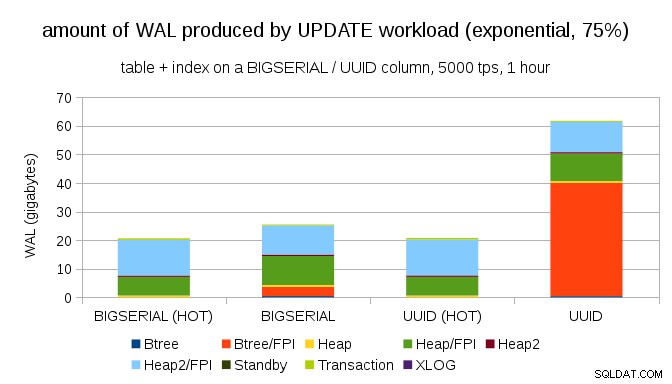
Isso mostra novamente a grande diferença que a escolha dos tipos de dados pode fazer e também a importância de ajustar as atualizações HOT.
páginas de 8kB e 4kB
Uma questão interessante é quanto tráfego WAL poderíamos economizar usando páginas menores no PostgreSQL (o que requer a compilação de um pacote personalizado). Na melhor das hipóteses, pode economizar até 50% de WAL, graças ao registro de apenas 4kB em vez de páginas de 8kB. Para a carga de trabalho com UPDATEs distribuídas uniformemente, fica assim:
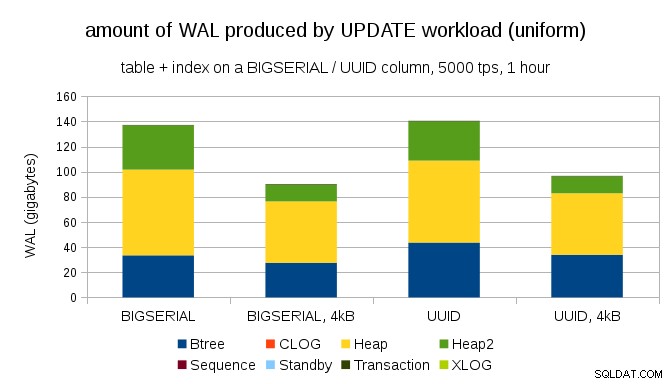
Portanto, a economia não é exatamente 50%, mas a redução de ~ 140 GB para ~ 90 GB ainda é bastante significativa.
Ainda precisamos de gravações de página inteira?
Pode parecer ridículo depois de explicar o perigo das gravações parciais, mas talvez desabilitar as gravações de página inteira possa ser uma opção viável, pelo menos em alguns casos.
Em primeiro lugar, gostaria de saber se os sistemas de arquivos Linux modernos ainda são vulneráveis a gravações parciais? O parâmetro foi introduzido no PostgreSQL 8.1 lançado em 2005, então talvez algumas das muitas melhorias no sistema de arquivos introduzidas desde então não sejam um problema. Provavelmente não universalmente para cargas de trabalho arbitrárias, mas talvez assumindo alguma condição adicional (por exemplo, usando tamanho de página de 4kB no PostgreSQL) seria suficiente? Além disso, o PostgreSQL nunca sobrescreve apenas um subconjunto da página de 8kB – a página inteira é sempre escrita.
Fiz muitos testes recentemente tentando acionar uma gravação parcial e ainda não consegui causar um único caso. Claro, isso não é realmente uma prova de que o problema não existe. Mas mesmo que ainda seja um problema, as somas de verificação de dados podem ser proteção suficiente (não corrigirá o problema, mas pelo menos informará que há uma página quebrada).
Em segundo lugar, muitos sistemas hoje em dia dependem de réplicas de replicação de streaming – em vez de esperar que o servidor reinicie após um problema de hardware (o que pode levar muito tempo) e gastar mais tempo executando a recuperação, os sistemas simplesmente alternam para um hot standby. Se o banco de dados no primário com falha for removido (e depois clonado do novo primário), as gravações parciais não serão um problema.
Mas acho que se começarmos a recomendar isso, então “não sei como os dados foram corrompidos, acabei de definir full_page_writes=off nos sistemas!” se tornaria uma das frases mais comuns antes da morte para DBAs (juntamente com o “Eu vi essa cobra no reddit, não é venenosa.”).
Resumo
Não há muito que você possa fazer para ajustar as gravações de página inteira diretamente. Para a maioria das cargas de trabalho, a maioria das gravações de página inteira ocorre logo após um ponto de verificação e desaparece até o próximo ponto de verificação. Por isso, é importante ajustar os checkpoints para que não aconteçam com muita frequência.
Algumas decisões no nível do aplicativo podem aumentar a aleatoriedade das gravações em tabelas e índices – por exemplo, os valores UUID são inerentemente aleatórios, transformando até mesmo a carga de trabalho INSERT simples em atualizações aleatórias de índice. O esquema usado nos exemplos foi bastante trivial - na prática haverá índices secundários, chaves estrangeiras etc. Mas usar chaves primárias BIGSERIAL internamente (e manter o UUID como chaves substitutas) pelo menos reduziria a amplificação de gravação.
Estou realmente interessado na discussão sobre a necessidade de gravações de página inteira nos kernels/sistemas de arquivos atuais. Infelizmente, não encontrei muitos recursos, então, se você tiver informações relevantes, me avise.