Um problema de desempenho que vejo com frequência é quando os usuários precisam corresponder parte de uma string com uma consulta como a seguinte:
... WHERE SomeColumn LIKE N'%SomePortion%';
Com um curinga inicial, esse predicado é "não SARGable" - apenas uma maneira elegante de dizer que não podemos encontrar as linhas relevantes usando uma busca em um índice em
SomeColumn . Uma solução sobre a qual ficamos meio confusos é a pesquisa de texto completo; no entanto, essa é uma solução complexa e requer que o padrão de pesquisa consista em palavras completas, não use palavras de parada e assim por diante. Isso pode ajudar se estivermos procurando por linhas em que uma descrição contenha a palavra "soft" (ou outras derivadas como "softer" ou "softly"), mas não ajuda quando estivermos procurando por strings que possam estar contidas dentro de palavras (ou que não sejam palavras, como todos os SKUs de produtos que contêm "X45-B" ou todas as placas de licença que contêm a sequência "7RA").
E se o SQL Server de alguma forma soubesse sobre todas as partes possíveis de uma string? Meu processo de pensamento segue as linhas de
trigram / trigraph no PostgreSQL. O conceito básico é que o mecanismo tem a capacidade de fazer pesquisas de estilo de ponto em substrings, o que significa que você não precisa varrer a tabela inteira e analisar todos os valores completos. O exemplo específico que eles usam é a palavra
cat . Além da palavra completa, ela pode ser dividida em partes:c , ca e at (eles deixam de fora a e t por definição – nenhuma substring final pode ser menor que dois caracteres). No SQL Server, não precisamos que seja tão complexo; nós realmente precisamos apenas da metade do trigrama – se pensarmos em construir uma estrutura de dados que contenha todas as substrings de cat , precisamos apenas destes valores:- gato
- em
- t
Não precisamos de
c ou ca , porque qualquer pessoa procurando por LIKE '%ca%' poderia facilmente encontrar o valor 1 usando LIKE 'ca%' em vez de. Da mesma forma, qualquer pessoa pesquisando por LIKE '%at%' ou LIKE '%a%' poderia usar um curinga à direita apenas nesses três valores e encontrar aquele que corresponde (por exemplo, LIKE 'at%' encontrará o valor 2 e LIKE 'a%' também encontrará o valor 2, sem ter que encontrar essas substrings dentro do valor 1, que é de onde viria a verdadeira dor). Então, dado que o SQL Server não tem nada assim embutido, como podemos gerar tal trigrama?
Uma tabela de fragmentos separada
Vou parar de fazer referência a "trigrama" aqui porque isso não é realmente análogo a esse recurso no PostgreSQL. Essencialmente, o que vamos fazer é construir uma tabela separada com todos os "fragmentos" da string original. (Assim, no
cat Por exemplo, haveria uma nova tabela com essas três linhas e LIKE '%pattern%' as pesquisas seriam direcionadas para essa nova tabela como LIKE 'pattern%' predicados.) Antes de começar a mostrar como minha solução proposta funcionaria, deixe-me ser absolutamente claro que esta solução não deve ser usada em todos os casos em que
LIKE '%wildcard%' as buscas são lentas. Devido à forma como vamos "explodir" os dados de origem em fragmentos, é provável que seja limitado em praticidade a strings menores, como endereços ou nomes, em oposição a strings maiores, como descrições de produtos ou resumos de sessão. Um exemplo mais prático do que
cat é olhar para o Sales.Customer tabela no banco de dados de exemplo WideWorldImporters. Tem linhas de endereço (ambas nvarchar(60) ), com as valiosas informações de endereço na coluna DeliveryAddressLine2 (por razões desconhecidas). Alguém pode estar procurando alguém que mora em uma rua chamada Hudecova , então eles farão uma pesquisa como esta:SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
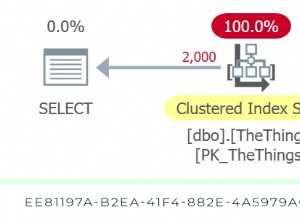
*/ Como seria de esperar, o SQL Server precisa realizar uma verificação para localizar essas duas linhas. Que deve ser simples; no entanto, devido à complexidade da tabela, essa consulta trivial gera um plano de execução muito confuso (a varredura é destacada e tem um aviso para E/S residual):
Blech. Para manter nossas vidas simples e ter certeza de que não perseguiremos um monte de pistas falsas, vamos criar uma nova tabela com um subconjunto das colunas e, para começar, apenas inseriremos essas mesmas duas linhas de cima:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
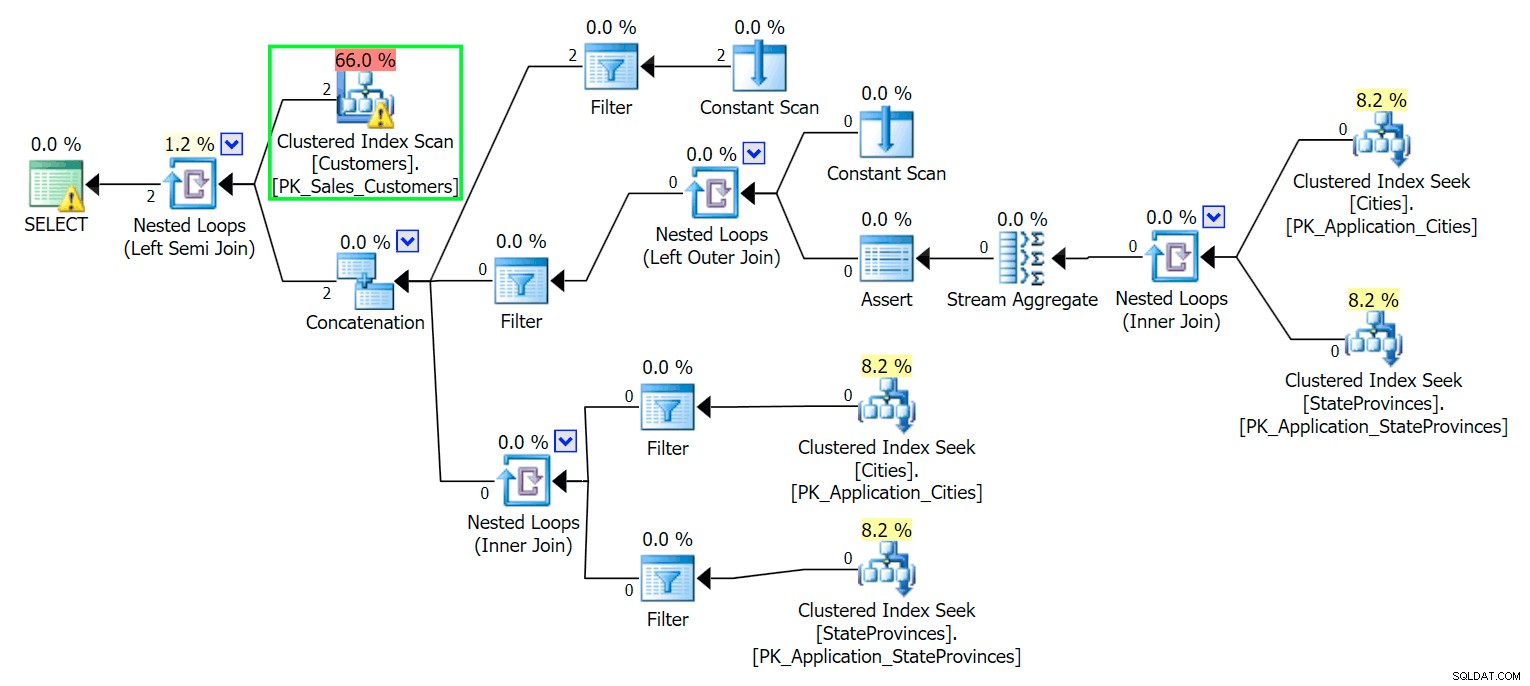
Agora, se executarmos a mesma consulta que executamos na tabela principal, obteremos algo muito mais razoável para ser visto como ponto de partida. Isso ainda será uma varredura, não importa o que façamos - se adicionarmos um índice com
DeliveryAddressLine2 como a coluna de chave principal, provavelmente obteremos uma verificação de índice, com uma pesquisa de chave dependendo se o índice cobre as colunas na consulta. Como está, obtemos uma varredura de índice clusterizado: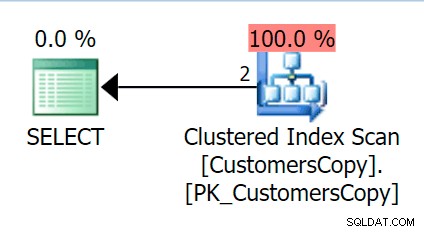
Em seguida, vamos criar uma função que irá "explodir" esses valores de endereço em fragmentos. Esperamos
1846 Hudecova Crescent , por exemplo, para ter o seguinte conjunto de fragmentos:- 1846 Hudecova Crescent
- 846 Hudecova Crescent
- 46 Hudecova Crescent
- 6 Hudecova Crescent
- Hudecova Crescent
- Hudecova Crescent
- udecova crescente
- decova crescente
- ecova crescente
- Cova Crescente
- Ova Crescente
- vai crescente
- um crescente
- Crescente
- Crescente
- rescente
- escente
- cheiro
- centavos
- ent
- n
- t
É bastante trivial escrever uma função que produzirá essa saída – precisamos apenas de um CTE recursivo que possa ser usado para percorrer cada caractere ao longo do comprimento da entrada:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Agora, vamos criar uma tabela que armazenará todos os fragmentos de endereço e a qual Cliente eles pertencem:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Então podemos preenchê-lo assim:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Para nossos dois valores, isso insere 42 linhas (um endereço tem 20 caracteres e o outro tem 22). Agora nossa consulta se torna:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Aqui está um plano muito melhor - dois índices clusterizados *procura* e uma junção de loops aninhados:
Também podemos fazer isso de outra maneira, usando
EXISTS :SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Aqui está esse plano, que parece ser mais caro – ele escolhe escanear a tabela CustomersCopy. Veremos em breve por que essa é a melhor abordagem de consulta:
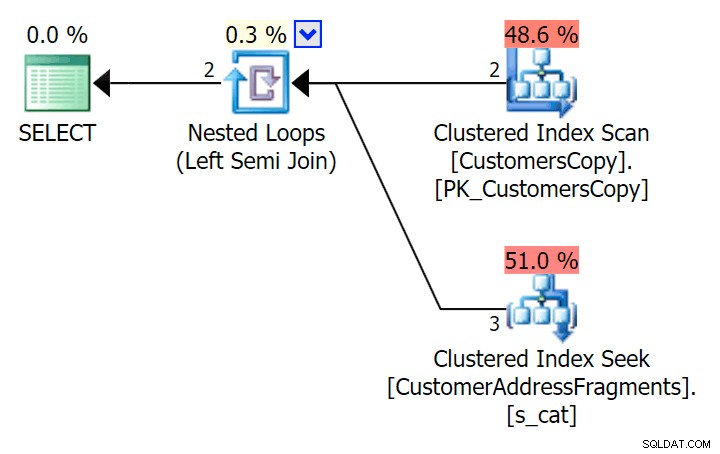
Agora, neste enorme conjunto de dados de 42 linhas, as diferenças vistas na duração e E/S são tão minúsculas que são irrelevantes (e, de fato, nesse tamanho pequeno, a varredura na tabela base parece mais barata em termos de I/O). O que os outros dois planos que usam a tabela de fragmentos):

E se preenchêssemos essas tabelas com muito mais dados? Minha cópia de
Sales.Customers tem 663 linhas, então se cruzarmos isso contra si mesmo, chegaríamos perto de 440.000 linhas. Então, vamos misturar 400K e gerar uma tabela muito maior:TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Agora, para comparar os planos de desempenho e execução com uma variedade de parâmetros de pesquisa possíveis, testei as três consultas acima com estes predicados:
| Consulta | Predicados | ||||
|---|---|---|---|---|---|
| ONDE DeliveryLineAddress2 GOSTA… | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| JOIN … WHERE Fragment LIKE … | N'Hudecova%' | N'cova%' | Nova%' | N'va%' | |
| ONDE EXISTE (… ONDE Fragmento LIKE…) | |||||
À medida que removemos letras do padrão de pesquisa, eu esperaria ver mais saídas de linhas e talvez diferentes estratégias escolhidas pelo otimizador. Vamos ver como foi para cada padrão:
Hudecova%
Para esse padrão, a varredura ainda era a mesma para a condição LIKE; no entanto, com mais dados, o custo é muito maior. As buscas na tabela de fragmentos realmente compensam nessa contagem de linhas (1.206), mesmo com estimativas muito baixas. O plano EXISTS adiciona uma classificação distinta, que você esperaria adicionar ao custo, embora neste caso acabe fazendo menos leituras:

 Planeje o JOIN para a tabela de fragmentos
Planeje o JOIN para a tabela de fragmentos 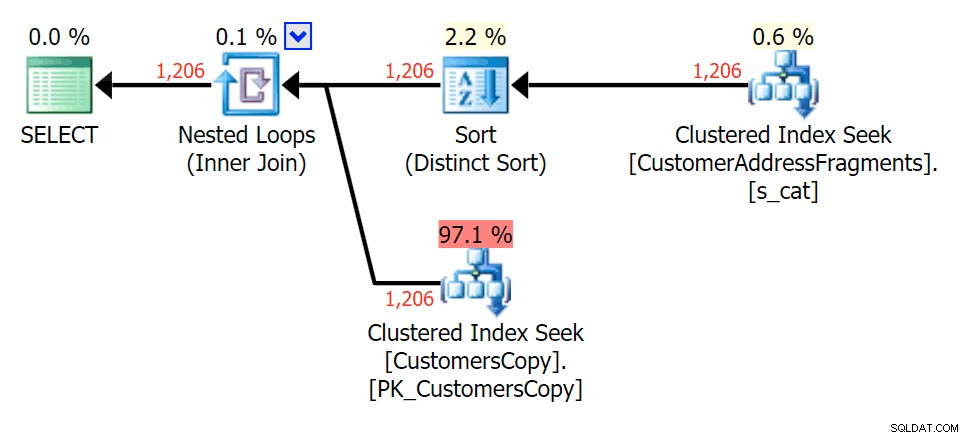 Planejar o EXISTS em relação à tabela de fragmentos
Planejar o EXISTS em relação à tabela de fragmentos cova%
À medida que retiramos algumas letras do nosso predicado, vemos as leituras na verdade um pouco mais altas do que com a varredura de índice clusterizado original, e agora sobre -estimar as linhas. Mesmo assim, nossa duração permanece significativamente menor com ambas as consultas de fragmento; a diferença desta vez é mais sutil - ambos têm tipos (apenas EXISTS é distinto):

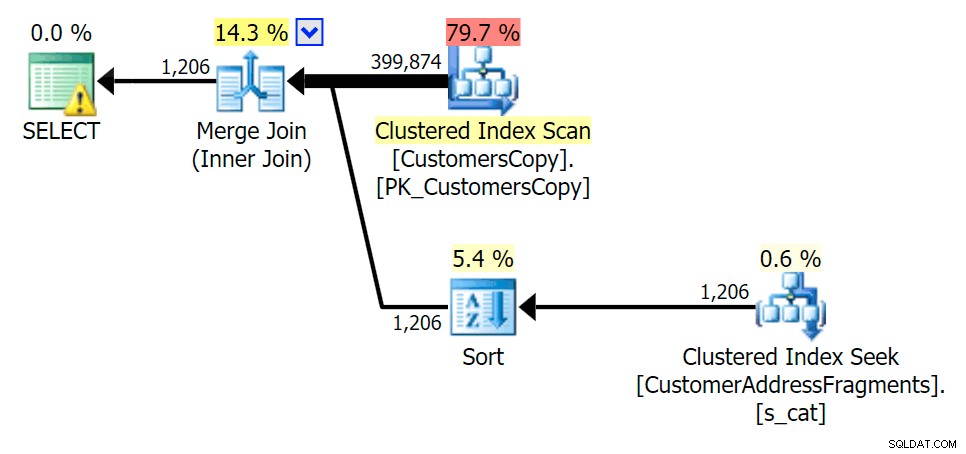 Planejar o JOIN para a tabela de fragmentos
Planejar o JOIN para a tabela de fragmentos 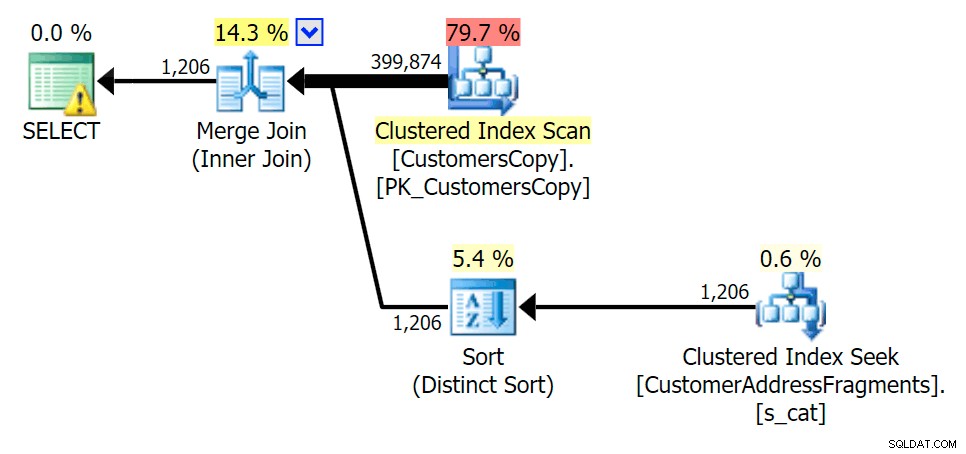 Planejar o EXISTS em relação à tabela de fragmentos
Planejar o EXISTS em relação à tabela de fragmentos % de óvulos
Tirar uma letra adicional não mudou muito; embora valha a pena notar o quanto as linhas estimadas e reais saltam aqui – o que significa que isso pode ser um padrão de substring comum. A consulta LIKE original ainda é um pouco mais lenta que as consultas de fragmento.

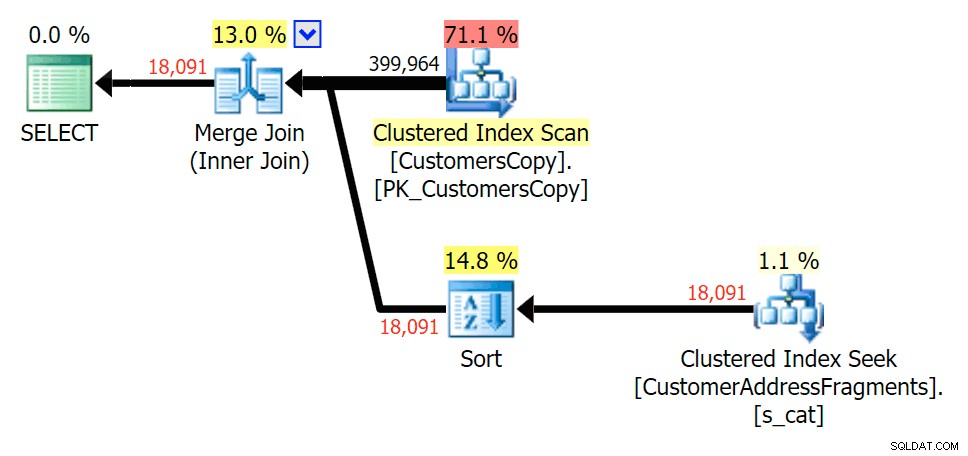 Planeje o JOIN para a tabela de fragmentos
Planeje o JOIN para a tabela de fragmentos 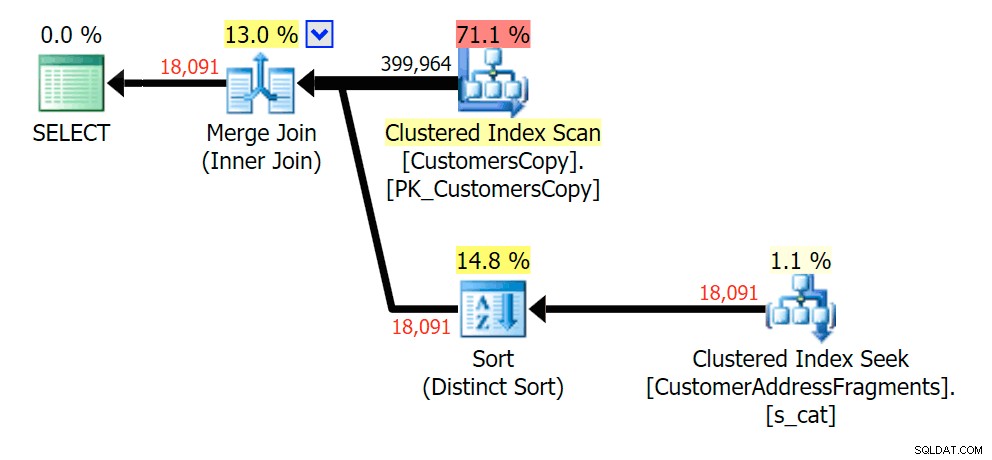 Planejar o EXISTS em relação à tabela de fragmentos
Planejar o EXISTS em relação à tabela de fragmentos va%
Com duas letras, isso introduz nossa primeira discrepância. Observe que o JOIN produz mais linhas do que a consulta original ou EXISTS. Por que seria isso?

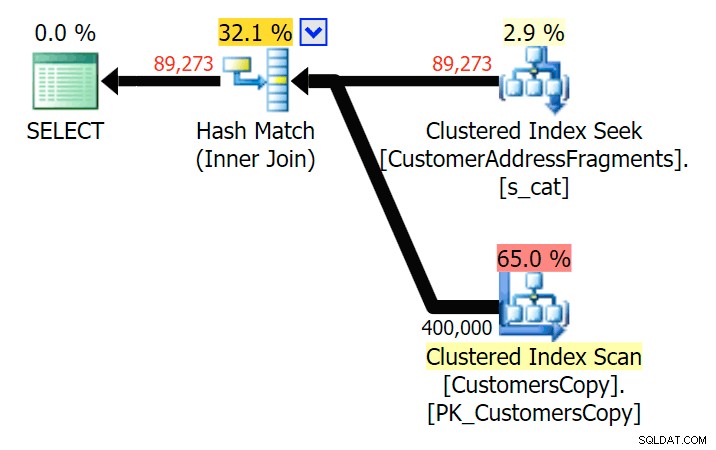 Planeje o JOIN para a tabela de fragmentos
Planeje o JOIN para a tabela de fragmentos 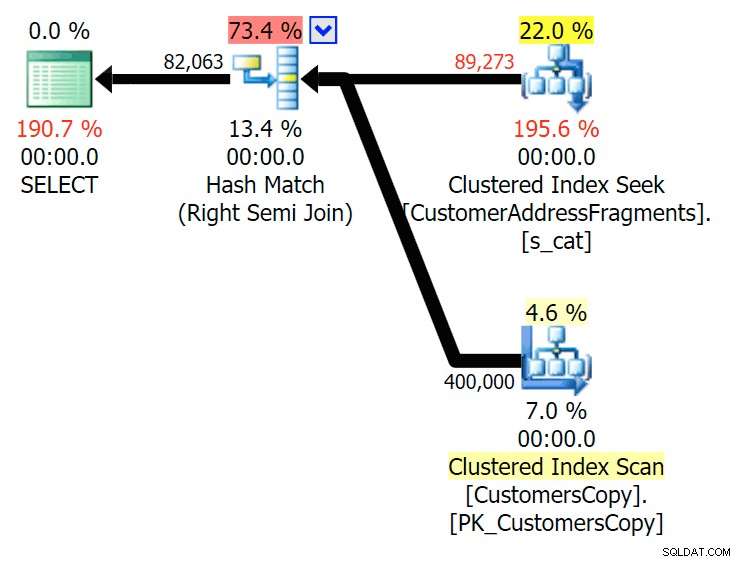 Planeje o EXISTS em relação à tabela de fragmentos Não precisamos procurar muito. Lembre-se de que há um fragmento começando de cada caractere sucessivo no endereço original, o que significa algo como
Planeje o EXISTS em relação à tabela de fragmentos Não precisamos procurar muito. Lembre-se de que há um fragmento começando de cada caractere sucessivo no endereço original, o que significa algo como 899 Valentova Road terá duas linhas na tabela de fragmentos que começam com va (diferenciação de maiúsculas e minúsculas à parte). Então você vai combinar em ambos Fragment = N'Valentova Road' e Fragment = N'va Road' . Vou poupar a pesquisa e fornecer um único exemplo de muitos:SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Isso explica prontamente por que o JOIN produz mais linhas; se você quiser corresponder à saída da consulta LIKE original, você deve usar EXISTS. O fato de que os resultados corretos geralmente também podem ser obtidos de maneira menos intensiva em recursos é apenas um bônus. (Eu ficaria nervoso se as pessoas escolhessem o JOIN se essa fosse a opção repetidamente mais eficiente – você deve sempre favorecer os resultados corretos em vez de se preocupar com o desempenho.)
Resumo
É claro que neste caso específico – com uma coluna de endereço de
nvarchar(60) e um comprimento máximo de 26 caracteres – dividir cada endereço em fragmentos pode trazer algum alívio para pesquisas de "carácter curinga líder" que de outra forma seriam caras. O melhor retorno parece acontecer quando o padrão de busca é maior e, como resultado, mais exclusivo. Também demonstrei por que EXISTS é melhor em cenários em que várias correspondências são possíveis - com um JOIN, você obterá uma saída redundante, a menos que adicione alguma lógica de "maior n por grupo". Advertências
Serei o primeiro a admitir que esta solução é imperfeita, incompleta e não totalmente desenvolvida:
- Você precisará manter a tabela de fragmentos sincronizada com a tabela base usando gatilhos – o mais simples seria para inserções e atualizações, excluir todas as linhas para esses clientes e reinseri-las, e para exclusões, obviamente, remover as linhas dos fragmentos tabela.
- Como mencionado, esta solução funcionou melhor para esse tamanho de dados específico e pode não funcionar tão bem para outros comprimentos de string. Isso justificaria mais testes para garantir que seja apropriado para o tamanho da coluna, o comprimento médio do valor e o comprimento típico do parâmetro de pesquisa.
- Como teremos muitas cópias de fragmentos como "Crescent" e "Street" (não importa todos os nomes de ruas e números de casas iguais ou semelhantes), poderíamos normalizá-lo ainda mais armazenando cada fragmento único em uma tabela de fragmentos, e, em seguida, outra tabela que atua como uma tabela de junção muitos-para-muitos. Isso seria muito mais complicado de configurar, e não tenho certeza se haveria muito a ganhar.
- Ainda não investiguei completamente a compactação de página, parece que – pelo menos em teoria – isso poderia trazer algum benefício. Também tenho a sensação de que uma implementação de columnstore também pode ser benéfica em alguns casos.
De qualquer forma, tudo o que foi dito, eu só queria compartilhá-lo como uma ideia em desenvolvimento e solicitar qualquer feedback sobre sua praticidade para casos de uso específicos. Posso entrar em mais detalhes para um post futuro se você puder me informar quais aspectos desta solução lhe interessam.