O monitoramento de banco de dados é o trabalho mais essencial de qualquer administrador de banco de dados. Grandes organizações e empresas têm vários servidores de banco de dados localizados no mesmo data center ou em data centers geograficamente diferentes. Existem muitas ferramentas padrão para monitoramento de banco de dados. Essas ferramentas usam as exibições de gerenciamento dinâmico do SQL Server e o procedimento armazenado do sistema para preencher os dados. Usando esses DMVs, podemos criar nosso sistema automatizado personalizado para preencher o status do banco de dados e enviar o relatório por e-mail.
Neste artigo, vou demonstrar como podemos usar o procedimento armazenado do sistema e o servidor vinculado para preencher as informações de bancos de dados localizados em diferentes servidores e agendar o trabalho para enviar o relatório.
Nesta demonstração, vou realizar as seguintes tarefas:
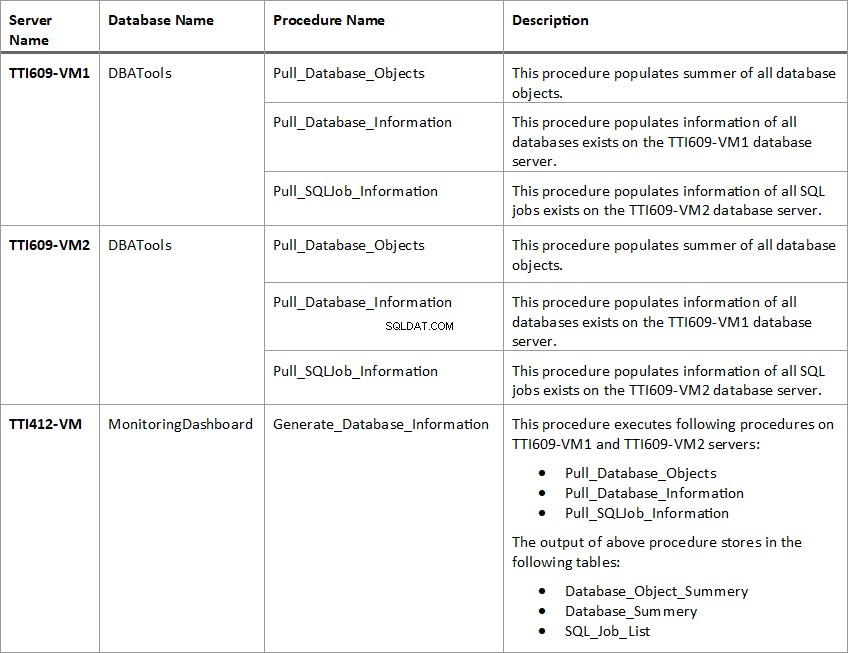
- Crie procedimentos armazenados necessários em TTI609-VM1 , TTI609-VM2, e TTI412-VM servidores para preencher informações do banco de dados, objetos de banco de dados e SQL Jobs.
- Crie um procedimento armazenado para preencher o resumo do banco de dados, o resumo do objeto do banco de dados e o resumo do trabalho SQL do TTI609-VM1 e TTI609-VM2 servidores e armazená-los em tabelas relacionadas.
- Crie um pacote SSIS que execute as seguintes tarefas:
- Executa um procedimento armazenado usando Executar tarefa de script SQL .
- Exportar dados de tabelas SQL criadas em TTI412-VM e armazená-lo na guia individual de um arquivo do Excel.
- Crie um trabalho do SQL Server para executar o pacote SSIS para preencher as informações do banco de dados e o procedimento armazenado para enviar o relatório por e-mail.
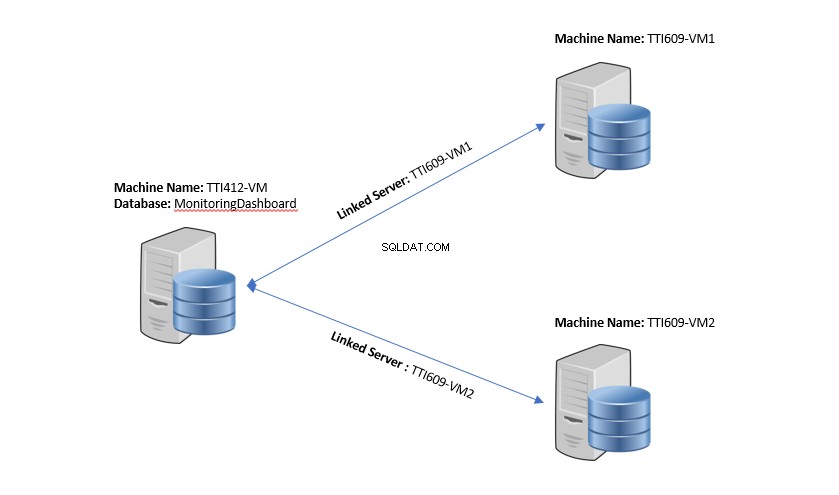
A imagem a seguir ilustra a configuração de demonstração:
Segue a lista de procedimentos armazenados:
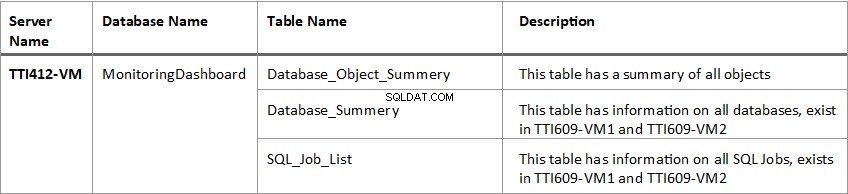
Segue a lista de Tabelas:
Crie procedimentos armazenados em ambos os servidores de banco de dados
Como mencionei, vamos preencher os dados do TTI609-VM1 e TTI609-VM2 servidores. Os procedimentos armazenados usados para preencher o banco de dados permanecerão os mesmos em ambos os servidores.
Então, em primeiro lugar, criei um banco de dados chamado DBATools em ambos os servidores. Eu criei um procedimento armazenado nesses bancos de dados. Para fazer isso, execute o seguinte código no TTI609-VM1 e TTI609-VM2 servidores:
USE [master] go /****** Object: Database [DBATools] Script Date: 10/25/2018 11:25:27 AM ******/ CREATE DATABASE [DBATools] containment = none ON PRIMARY ( NAME = N'DBATools', filename = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\DBATools.mdf' , size = 3264kb, maxsize = unlimited, filegrowth = 1024kb ) log ON ( NAME = N'DBATools_log', filename = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\DBATools_log.ldf' , size = 816kb, maxsize = 2048gb, filegrowth = 10%) go
Crie um procedimento armazenado chamado Pull_Database_Information nas DBATools base de dados. Este procedimento armazenado preenche as seguintes informações de todos os bancos de dados existentes em ambos os servidores de banco de dados.
- Nome do banco de dados.
- Nível de compatibilidade do banco de dados.
- Estado do banco de dados (ONLINE/OFFLINE/RESTORING/SUSPEND).
- Modelo de recuperação de banco de dados (SIMPLE / FULL / BULK-LOGGED).
- Tamanho do banco de dados em MB.
- Tamanho total do arquivo de dados.
- Tamanho do arquivo de dados usado.
- Tamanho total do arquivo de registro.
- Tamanho do arquivo de registro usado.
Execute o seguinte código no DBATools banco de dados de ambos os servidores de banco de dados para criar o procedimento armazenado:
USE DBAtools
go
CREATE PROCEDURE Pull_Database_Information
AS
BEGIN
IF Object_id('tempdb.dbo.#DBSize') IS NOT NULL
DROP TABLE #dbsize
CREATE TABLE #dbsize
(
database_id INT PRIMARY KEY,
data_file_used_size DECIMAL(18, 2),
log_file_used_size DECIMAL(18, 2)
)
DECLARE @SQLCommand NVARCHAR(max)
SELECT @SQLCommand = Stuff((SELECT ' USE [' + d.NAME + '] INSERT INTO #DBSize (database_id, data_file_used_size, log_File_used_size) SELECT DB_ID() , SUM(CASE WHEN [type] = 0 THEN space_used END) , SUM(CASE WHEN [type] = 1 THEN space_used END) FROM ( SELECT s.[type], space_used = SUM(FILEPROPERTY(s.name, ''SpaceUsed'') * 8. / 1024) FROM sys.database_files s GROUP BY s.[type] ) t;'
FROM sys.databases d
WHERE d.[state] = 0
FOR xml path(''), type).value('.',
'NVARCHAR(MAX)'),
1, 2,
'')
EXEC sys.Sp_executesql
@SQLCommand
SELECT d.database_id AS 'Database ID',
d.NAME AS 'Database Name',
d.state_desc AS 'Database State',
d.recovery_model_desc AS 'Recovery Model',
t.total_db_size AS 'Database Size',
t.data_file_size AS 'Data File Size',
s.data_file_used_size AS 'Data File Used',
t.log_file_size AS 'Log file size',
s.log_file_used_size AS 'Log File Used'
FROM (SELECT database_id,
log_file_size = Cast(Sum(CASE
WHEN [type] = 1 THEN size
END) * 8. / 1024 AS DECIMAL(18, 2)
),
data_file_size = Cast(Sum(CASE
WHEN [type] = 0 THEN size
END) * 8. / 1024 AS
DECIMAL(18, 2))
,
total_DB_size = Cast(
Sum(size) * 8. / 1024 AS DECIMAL(18, 2))
FROM sys.master_files
GROUP BY database_id) t
JOIN sys.databases d
ON d.database_id = t.database_id
LEFT JOIN #dbsize s
ON d.database_id = s.database_id
ORDER BY t.total_db_size DESC
END Em segundo lugar, crie procedimentos armazenados chamados Pull_Database_Objects nas DBATools base de dados. Esse procedimento armazenado itera por todos os bancos de dados em ambos os servidores de banco de dados e preenche a contagem de todos os objetos de banco de dados. Ele preenche as seguintes colunas:
- Nome do servidor/host.
- Nome do banco de dados.
- Tipo de objeto de banco de dados (tabela / procedimento armazenado / funções do SQL Scaler / restrições etc.)
- Número total de objetos de banco de dados.
Execute o seguinte código no DBATools banco de dados em ambos os servidores de banco de dados para criar o procedimento armazenado:
USE dbatools go CREATE PROCEDURE [Pull_database_objects] AS BEGIN CREATE TABLE #finalsummery ( id INT IDENTITY (1, 1), databasename VARCHAR(350), objecttype VARCHAR(200), totalobjects INT ) DECLARE @SQLCommand NVARCHAR(max) DECLARE @I INT=0 DECLARE @DBName VARCHAR(350) DECLARE @DBCount INT CREATE TABLE #databases ( NAME VARCHAR(350) ) INSERT INTO #databases (NAME) SELECT NAME FROM sys.databases WHERE database_id > 4 AND NAME NOT IN ( 'ReportServer', 'reportservertempdb' ) SET @DBCount=(SELECT Count(*) FROM #databases) WHILE ( @DBCount > @I ) BEGIN SET @DBName=(SELECT TOP 1 NAME FROM #databases) SET @SQLCommand=' Insert Into #FinalSummery (DatabaseName,ObjectType,TotalObjects) Select ''' + @DBName + ''', Case when Type=''TR'' then ''SQL DML trigger'' when Type=''FN'' then ''SQL scalar function'' when Type=''D'' then ''DEFAULT (constraint or stand-alone)'' when Type=''PK'' then ''PRIMARY KEY constraint'' when Type=''P'' then ''SQL Stored Procedure'' when Type=''U'' then ''Table (user-defined)'' when Type=''V'' then ''View'' when Type=''X'' then ''Extended stored procedure'' End As ObjectType, Count(Name)TotalObjects from ' + @DBName + '.sys.all_objects group by type' EXEC Sp_executesql @SQLCommand DELETE FROM #databases WHERE NAME = @DBName SET @example@sqldat.com + 1 END SELECT Host_name() AS 'Server Name', databasename, objecttype, totalobjects, Getdate() AS 'ReportDate' FROM #finalsummery WHERE objecttype IS NOT NULL DROP TABLE #finalsummery END
Crie procedimentos armazenados denominados Pull_SQLJob_Information nas DBATools base de dados. Esse procedimento armazenado itera por todo o servidor de banco de dados e preenche as informações de todos os trabalhos SQL e seus status. Ele preenche as seguintes colunas:
- Nome do servidor/host.
- Nome do trabalho SQL.
- Proprietário do trabalho SQL.
- Categoria de trabalho.
- Descrição do trabalho.
- Status do trabalho (ativado/desativado)
- Uma data de criação do emprego.
- Data de modificação da tarefa.
- Status do trabalho agendado.
- Nome da programação.
- Data e hora da última execução
- Status da última execução.
Execute o seguinte código no DBATools banco de dados em ambos os servidores de banco de dados para criar o procedimento armazenado:
CREATE PROCEDURE Pull_sqljob_information AS BEGIN SELECT Host_name() AS 'Server Name', a.NAME AS 'Job Name', d.NAME AS Owner, b.NAME AS Category, a.description AS Description, CASE a.enabled WHEN 1 THEN 'Yes' WHEN 0 THEN 'No' END AS 'IsEnabled', a.date_created AS CreatedDate, a.date_modified AS ModifiedDate, CASE WHEN f.schedule_uid IS NULL THEN 'No' ELSE 'Yes' END AS 'Scheduled?', f.NAME AS JobScheduleName, Max(Cast( Stuff(Stuff(Cast(g.run_date AS VARCHAR), 7, 0, '-'), 5, 0, '-') + ' ' + Stuff(Stuff(Replace(Str(g.run_time, 6, 0), ' ', '0'), 5, 0, ':'), 3, 0, ':') AS DATETIME)) AS [LastRun], CASE g.run_status WHEN 0 THEN 'Failed' WHEN 1 THEN 'Success' WHEN 2 THEN 'Retry' WHEN 3 THEN 'Canceled' WHEN 4 THEN 'In progress' END AS Status FROM msdb.dbo.sysjobs AS a INNER JOIN msdb.dbo.sysjobhistory g ON a.job_id = g.job_id LEFT JOIN msdb.dbo.syscategories AS b ON a.category_id = b.category_id LEFT JOIN msdb.dbo.sysjobsteps AS c ON a.job_id = c.job_id AND a.start_step_id = c.step_id LEFT JOIN msdb.sys.database_principals AS d ON a.owner_sid = d.sid LEFT JOIN msdb.dbo.sysjobschedules AS e ON a.job_id = e.job_id LEFT JOIN msdb.dbo.sysschedules AS f ON e.schedule_id = f.schedule_id GROUP BY a.NAME, d.NAME, b.NAME, a.description, a.enabled, f.schedule_uid, f.NAME, a.date_created, a.date_modified, g.run_status ORDER BY a.NAME END
Criar procedimentos armazenados, servidor vinculado e tabelas no servidor central
Depois que os procedimentos forem criados no TTI609-VM1 e TTI609-VM2 servidores de banco de dados, crie procedimentos e tabelas necessários no servidor central (TTI412-VM ).
Criei um banco de dados separado chamado MonitoringDashboard na TTI412-VM servidor. Execute o código a seguir para criar um banco de dados no servidor central.
USE [master] go /****** Object: Database [MonitoringDashboard] Script Date: 10/25/2018 2:44:09 PM ******/ CREATE DATABASE [MonitoringDashboard] containment = none ON PRIMARY ( NAME = N'MonitoringDashboard', filename = N'E:\MS_SQL\SQL2017_Data\MonitoringDashboard.mdf', size = 8192kb, maxsize = unlimited, filegrowth = 65536kb ) log ON ( NAME = N'MonitoringDashboard_log', filename = N'E:\MS_SQL\SQL2017_Log\MonitoringDashboard_log.ldf', size = 8192kb, maxsize = 2048gb, filegrowth = 65536kb ) go
Depois que o banco de dados for criado, crie um procedimento armazenado que use o LINKED Server para executar um procedimento no TTI609-VM1 e TTI609-VM2 servidores de banco de dados. Execute o seguinte código no banco de dados “mestre” da TTI412-VM servidor de banco de dados para criar um servidor vinculado:
Script 1:Criar servidor vinculado TTI609-VM1
USE [master] go /****** Object: LinkedServer [TTI609-VM1] Script Date: 10/25/2018 2:49:28 PM ******/ EXEC master.dbo.Sp_addlinkedserver @server = N'TTI609-VM1', @srvproduct=N'SQL Server' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.Sp_addlinkedsrvlogin @rmtsrvname=N'TTI609-VM1', @useself=N'False', @locallogin=NULL, @rmtuser=N'sa', @rmtpassword='########' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'collation compatible', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'data access', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'dist', @optvalue=N'false' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'rpc', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'rpc out', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'connect timeout', @optvalue=N'0' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'query timeout', @optvalue=N'0' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'use remote collation', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM1', @optname=N'remote proc transaction promotion', @optvalue=N'false' go
Script 2:Criar servidor vinculado TTI609-VM2
USE [master] go /****** Object: LinkedServer [TTI609-VM2] Script Date: 10/25/2018 2:55:29 PM ******/ EXEC master.dbo.Sp_addlinkedserver @server = N'TTI609-VM2', @srvproduct=N'SQL Server' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.Sp_addlinkedsrvlogin @rmtsrvname=N'TTI609-VM2', @useself=N'False', @locallogin=NULL, @rmtuser=N'sa', @rmtpassword='########' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'collation compatible', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'data access', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'dist', @optvalue=N'false' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'rpc', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'rpc out', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'connect timeout', @optvalue=N'0' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'collation name', @optvalue=NULL go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'query timeout', @optvalue=N'0' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'use remote collation', @optvalue=N'true' go EXEC master.dbo.Sp_serveroption @server=N'TTI609-VM2', @optname=N'remote proc transaction promotion', @optvalue=N'false' go
Criar um procedimento armazenado e tabelas
Depois que o servidor vinculado for criado, precisamos criar três tabelas chamadas Database_Object_Summery , Database_Summery e SQL_Job_List no MonitoringDashboard base de dados. Essas tabelas armazenam informações preenchidas pelo Generate_Database_Information procedimento armazenado e posteriormente os dados, armazenados nessas tabelas que serão utilizadas para gerar um relatório em excel.
Execute o seguinte código para criar o SQL_Job_List tabela:
USE [MonitoringDashboard] go CREATE TABLE [dbo].[sql_job_list] ( [id] [INT] IDENTITY(1, 1) NOT NULL, [servername] [VARCHAR](250) NULL, [jobname] [VARCHAR](250) NULL, [jobowner] [VARCHAR](250) NULL, [jobcategory] [VARCHAR](250) NULL, [jobdescription] [VARCHAR](250) NULL, [jobstatus] [VARCHAR](50) NULL, [createdate] [DATETIME] NULL, [modifieddate] [DATETIME] NULL, [isscheduled] [VARCHAR](5) NULL, [schedulename] [VARCHAR](250) NULL, [reportdate] [DATETIME] NULL ) ON [PRIMARY] go ALTER TABLE [dbo].[sql_job_list] ADD DEFAULT (Getdate()) FOR [ReportDate] go
Execute o seguinte código para criar os lst_dbservers tabela:
USE [MonitoringDashboard] go CREATE TABLE [dbo].[lst_dbservers] ( [id] [INT] IDENTITY(1, 1) NOT NULL, [servername] [VARCHAR](50) NOT NULL, [addeddate] [DATETIME] NOT NULL, PRIMARY KEY CLUSTERED ( [id] ASC )WITH (pad_index = OFF, statistics_norecompute = OFF, ignore_dup_key = OFF, allow_row_locks = on, allow_page_locks = on) ON [PRIMARY], UNIQUE NONCLUSTERED ( [servername] ASC )WITH (pad_index = OFF, statistics_norecompute = OFF, ignore_dup_key = OFF, allow_row_locks = on, allow_page_locks = on) ON [PRIMARY] ) ON [PRIMARY] go ALTER TABLE [dbo].[lst_dbservers] ADD DEFAULT (Getdate()) FOR [AddedDate] go
Execute o seguinte código para criar o Database_Summery tabela:
USE [MonitoringDashboard] go CREATE TABLE [dbo].[database_summery] ( [id] [INT] IDENTITY(1, 1) NOT NULL, [servername] [VARCHAR](150) NULL, [databaseid] [INT] NULL, [databasename] [VARCHAR](250) NULL, [databasestatus] [VARCHAR](50) NULL, [recoverymodel] [VARCHAR](50) NULL, [compatibilitylevel] [INT] NULL, [databasecreatedate] [DATE] NULL, [databasecreatedby] [VARCHAR](150) NULL, [dbsize] [NUMERIC](10, 2) NULL, [datafilesize] [NUMERIC](10, 2) NULL, [datafileused] [NUMERIC](10, 2) NULL, [logfilesize] [NUMERIC](10, 2) NULL, [logfileused] [NUMERIC](10, 2) NULL, [reportdate] [DATETIME] NULL ) ON [PRIMARY] go ALTER TABLE [dbo].[database_summery] ADD DEFAULT (Getdate()) FOR [ReportDate] go
Execute o seguinte código para criar o Database_Object_Summery tabela:
USE [MonitoringDashboard] go CREATE TABLE [dbo].[database_object_summery] ( [id] [INT] IDENTITY(1, 1) NOT NULL, [servername] [VARCHAR](250) NULL, [databasename] [VARCHAR](250) NULL, [objecttype] [VARCHAR](50) NULL, [objectcount] [INT] NULL, [reportdate] [DATETIME] NULL ) ON [PRIMARY] go ALTER TABLE [dbo].[database_object_summery] ADD DEFAULT (Getdate()) FOR [ReportDate] go
Depois que as tabelas forem criadas, crie um procedimento armazenado chamado Generate_Database_Information no MonitoringDashboard base de dados. Usando “RPC”, ele executa procedimentos armazenados, criados no TTI609-VM1 e TTI609-VM2 servidores de banco de dados para preencher os dados.
Execute o seguinte código para criar um procedimento armazenado:
Create PROCEDURE Generate_database_information AS BEGIN /*Cleanup*/ TRUNCATE TABLE database_object_summery TRUNCATE TABLE database_summery TRUNCATE TABLE sql_job_list DECLARE @ServerCount INT DECLARE @i INT =0 DECLARE @SQLCommand_Object_Summery NVARCHAR(max) DECLARE @SQLCommand_Database_Information NVARCHAR(max) DECLARE @SQLCommand_SQL_Job_Information NVARCHAR(max) DECLARE @servername VARCHAR(100) CREATE TABLE #db_server_list ( servername VARCHAR(100) ) INSERT INTO #db_server_list (servername) SELECT servername FROM lst_dbservers SET @ServerCount= (SELECT Count(servername) FROM #db_server_list) WHILE ( @ServerCount > @i ) BEGIN SET @servername=(SELECT TOP 1 servername FROM #db_server_list) SET @SQLCommand_Object_Summery = 'insert into Database_Object_Summery (ServerName,DatabaseName,ObjectType,ObjectCount,ReportDate) exec [' + @servername + '].DBATools.dbo.[Pull_Database_Objects]' SET @SQLCommand_Database_Information = 'insert into Database_Summery (ServerName,DatabaseID,DatabaseName,DatabaseStatus,Recoverymodel,CompatibilityLevel,DatabaseCreateDate,DatabaseCreatedBy,DBSize,DataFileSize,DataFileUsed,LogFileSize,LogFileUsed) exec [' + @servername + '].DBATools.dbo.[Pull_Database_Information]' SET @SQLCommand_SQL_Job_Information = 'insert into SQL_Job_List (ServerName,JobName,JobOwner,Jobcategory,JobDescription,JobStatus,CreateDate,ModifiedDate,IsScheduled,ScheduleName) exec [' + @servername + '].DBATools.dbo.[Pull_SQLJob_Information]' EXEC Sp_executesql @SQLCommand_Object_Summery EXEC Sp_executesql @SQLCommand_Database_Information EXEC Sp_executesql @SQLCommand_SQL_Job_Information DELETE FROM #db_server_list WHERE servername = @servername SET @example@sqldat.com + 1 END END
Depois que o procedimento for criado, crie um pacote SSIS para exportar os dados para um arquivo do Excel.
Criar pacote SSIS para exportar dados em arquivo excel
Em meus artigos anteriores, expliquei as etapas para configurar as tarefas de fluxo de dados, conexões OLEDB e conexões do Excel, portanto, pulo esta parte.
Para exportar dados para um arquivo do Excel, abra as ferramentas de dados do SQL Server e crie um novo projeto SSIS chamado Export_Database_Information.
Depois que o projeto for criado, arraste e solte Execute SQL Task para o Fluxo de controle janela e renomeie-a como Preencher dados de servidores . Veja a seguinte imagem:
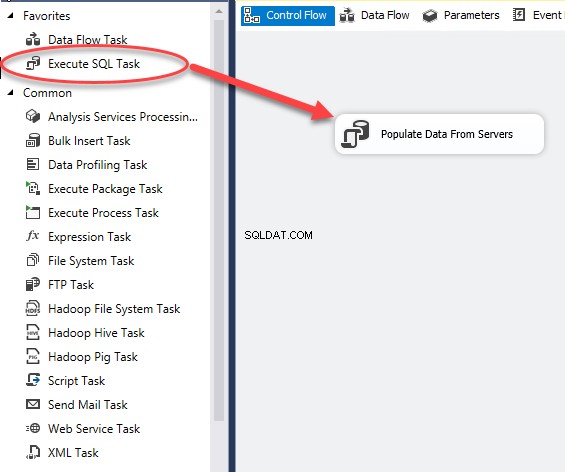
Clique duas vezes em Executar tarefa SQL (Preencher dados do servidor). O Editor de tarefas de execução SQL caixa de diálogo é aberta para configurar a conexão SQL. Veja a seguinte imagem:
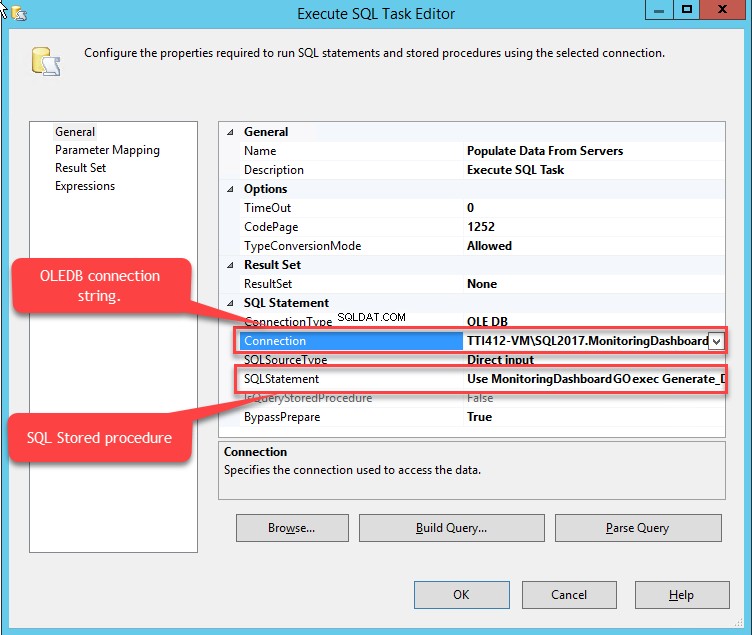
Na Conexão arquivado, selecione o OLEDB string de conexão e na Instrução SQL campo, forneça a seguinte consulta:
USE monitoringdashboard go EXEC Generate_database_information
Clique em OK para fechar a caixa de diálogo.
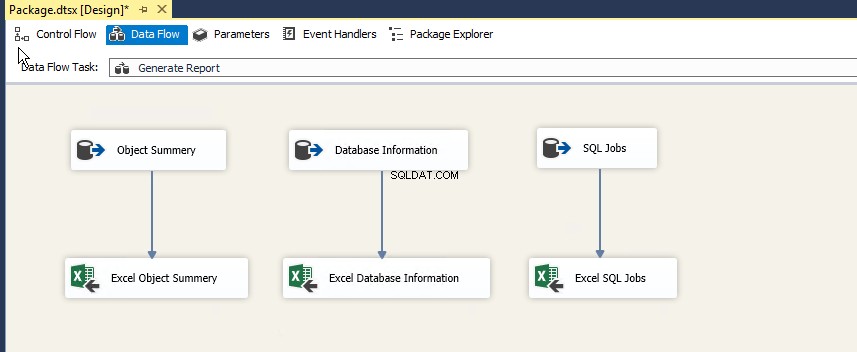
No Fluxo de controle tela, arraste e solte a tarefa de fluxo de dados da caixa de ferramentas do SSIS e renomeie-a como Gerar relatório. Veja a seguinte imagem:
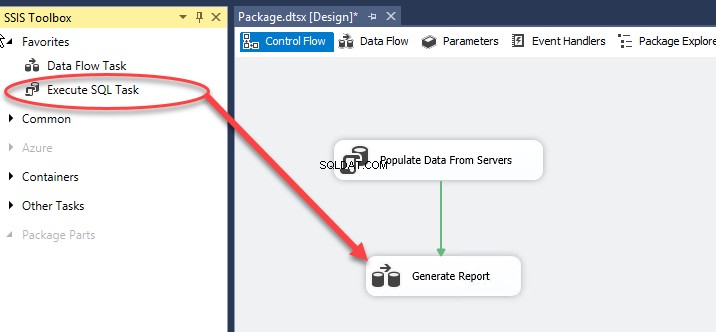
Clique duas vezes para abrir o fluxo de dados janela.
Como mencionei anteriormente, o Generate_Database_Information O procedimento insere a saída dos servidores de banco de dados nas seguintes tabelas:
- Database_Object_Summery
- Database_Summery
- SQL_Job_List
Eu criei um arquivo do Excel que tem três planilhas. As tabelas a seguir mostram o mapeamento das tabelas SQL e planilha do Excel.

No Fluxo de dados janela, arraste e solte três fontes ADO.Net e três destinos Excel. Veja a seguinte imagem:
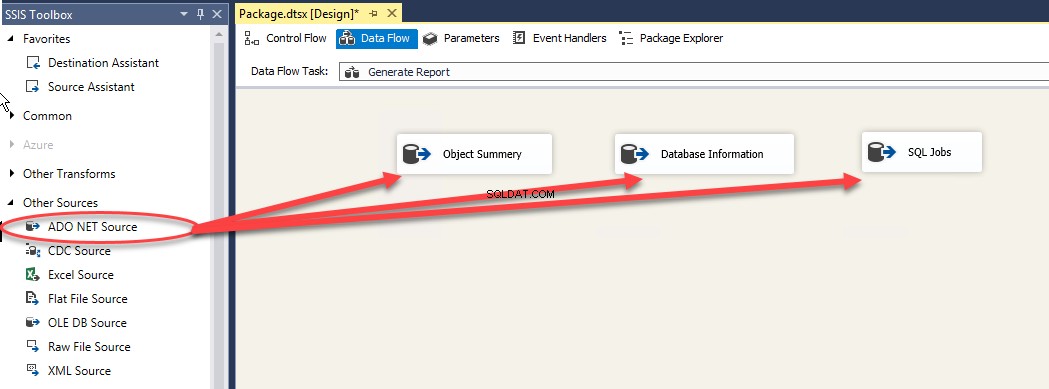
Clique duas vezes em Resumo do objeto y (Origem ADO.NET) em Origem ADO.NET Editor.
- Selecione TTI412-VM\SQL2017MonitoringDashboard do gerenciador de conexões ADO.NET caixa suspensa.
- Selecione Tabela ou Visualização do modo de acesso a dados caixa suspensa.
- Selecione Database_Object_Summery de Nome da tabela ou visualização caixa suspensa.
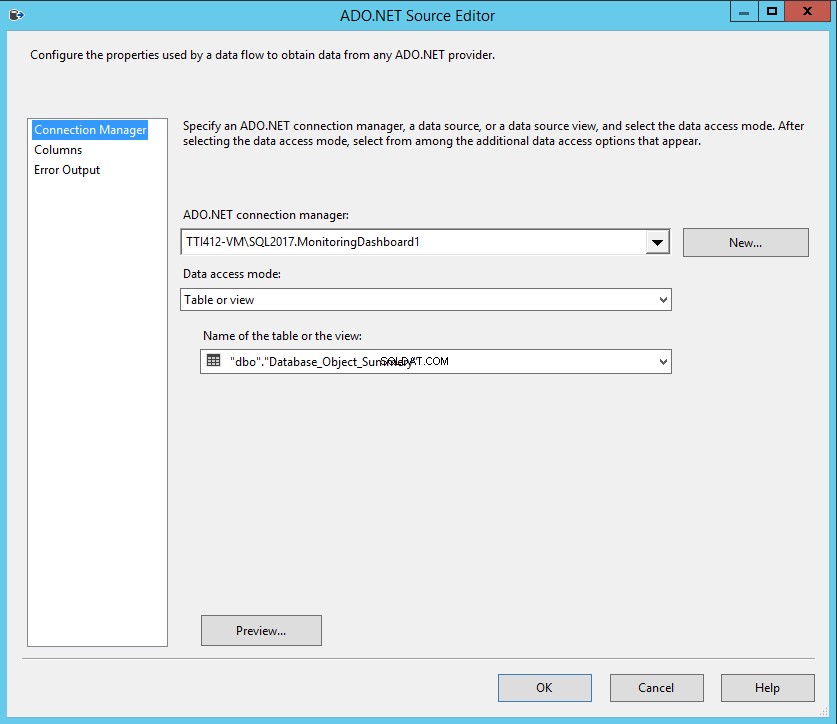
Clique duas vezes em Informações do banco de dados (Fonte ADO.NET) no Editor de origem ADO.NET .
- Selecione “TTI412-VM\SQL2017MonitoringDashboard ” do gerenciador de conexões ADO.NET caixa suspensa.
- Selecione Tabela ou Visualização do modo de acesso a dados caixa suspensa.
- Selecione “Database_Summery ” do Nome da tabela ou visualização caixa suspensa.
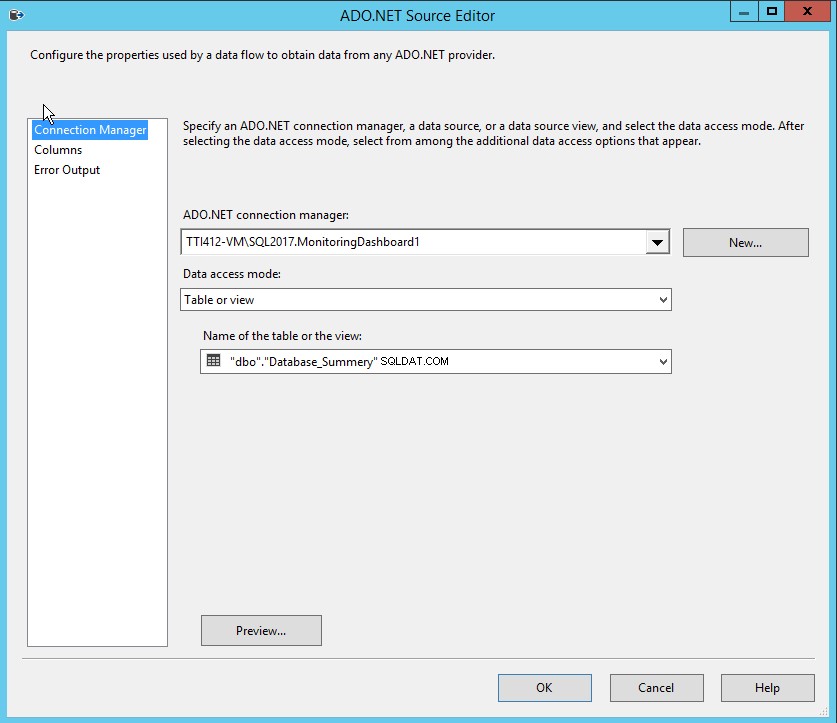
Clique duas vezes em Trabalhos SQL (Fonte ADO.NET) no Editor de origem ADO.NET .
- Selecione TTI412-VM\SQL2017MonitoringDashboard no gerenciador de conexões ADO.NET.
- Selecione Tabela ou Visualização a partir do modo de acesso a dados caixa suspensa.
- Selecione SQL_Job_List no Nome da tabela ou visualização caixa suspensa.
Agora, arraste e solte três destinos do Excel da SSIS Toolbox. Veja a seguinte imagem:
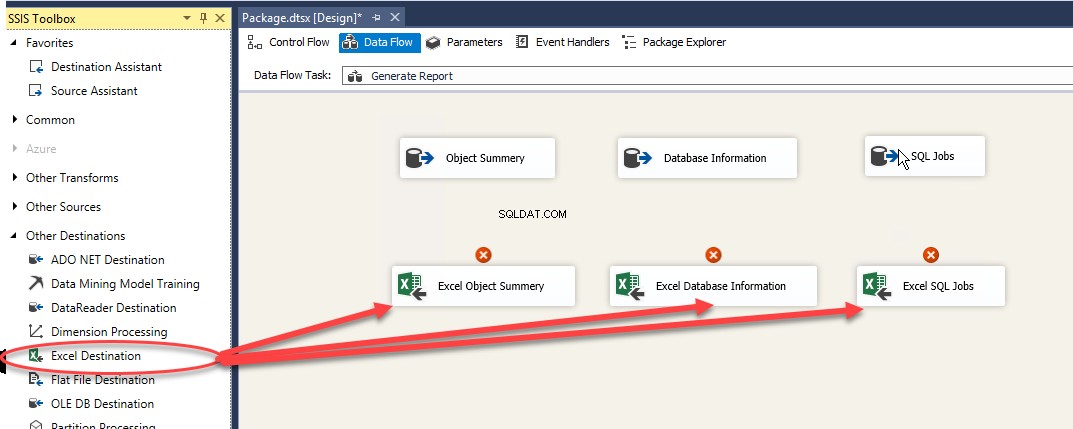
Depois que os destinos forem copiados, arraste a seta azul abaixo da origem ADO.Net e solte-a no destino Excel. Faça o mesmo para todos. Veja a seguinte imagem:
Clique duas vezes em Resumo do objeto do Excel (Origem ADO.NET) no Editor de destino do Excel .
- Selecione Gerenciador de conexões do Excel do gerenciador de conexões do Excel caixa suspensa.
- Selecione Ative ou Visualize do modo de acesso a dados caixa suspensa.
- Selecione Objeto Summery$ do Nome da planilha do Excel caixa suspensa.
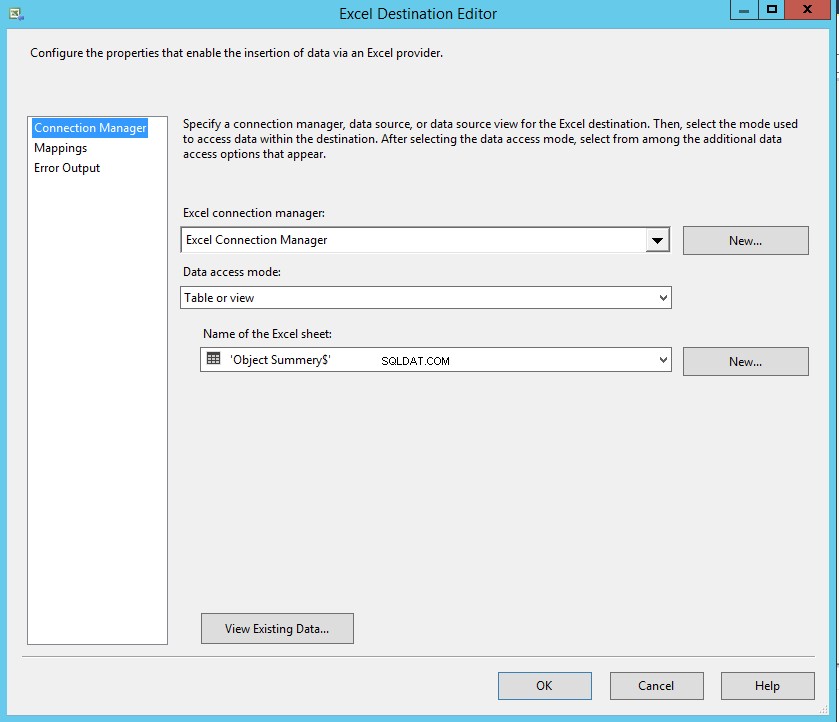
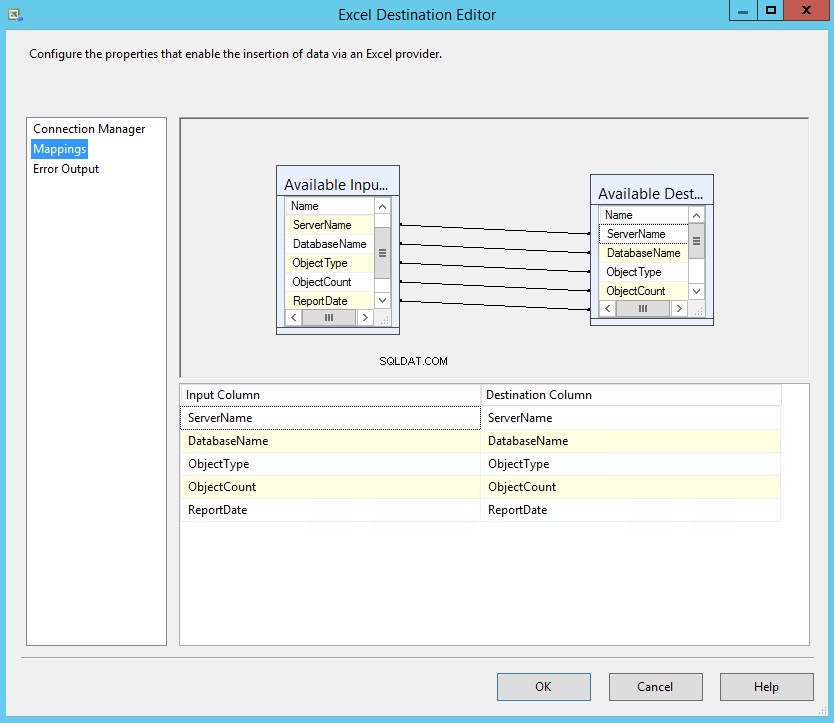
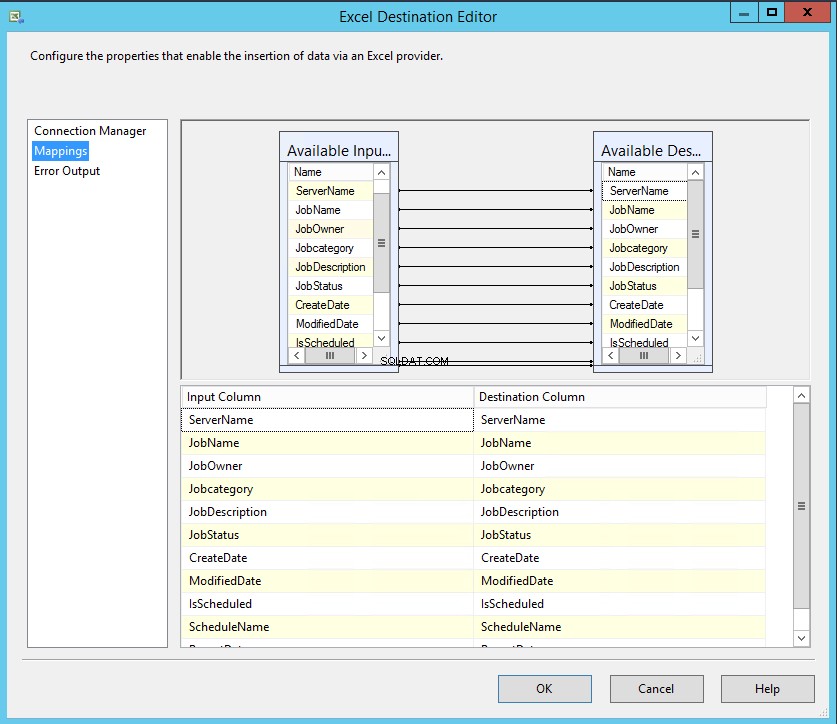
Como mencionei, os nomes das colunas da tabela SQL e as colunas do Excel são os mesmos, portanto, o mapeamento será feito automaticamente. Clique em Mapeamento para mapear as colunas. Veja a seguinte imagem:
Clique duas vezes em Informações do banco de dados do Excel (Destino do Excel) no Editor de Destino do Excel .
- Selecione Gerenciador de conexões do Excel do gerenciador de conexões do Excel caixa suspensa.
- Selecione Ative ou Visualize do modo de acesso a dados caixa suspensa.
- Selecione Informações do banco de dados$ do Nome da planilha do Excel caixa suspensa.
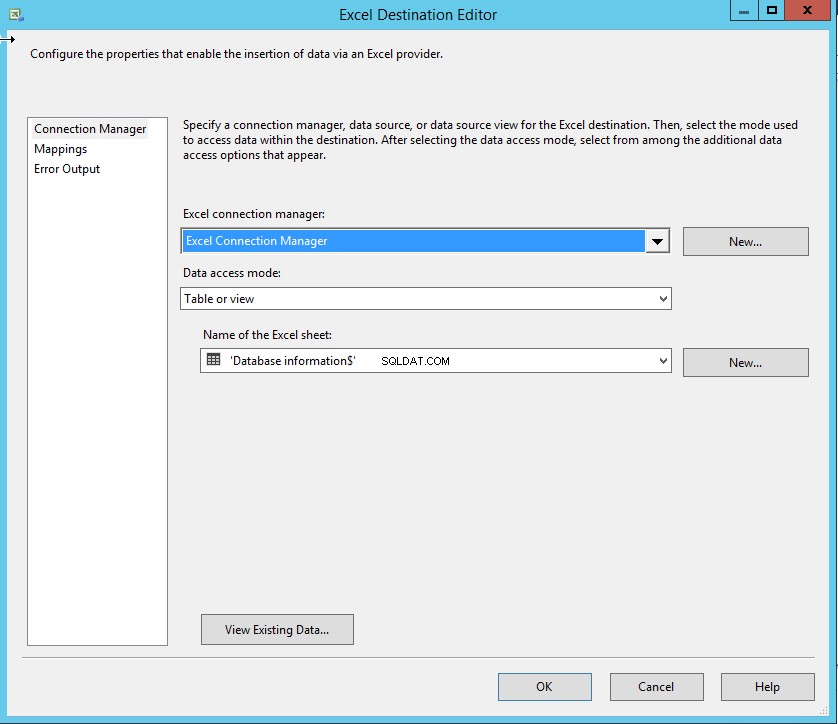
Como mencionei, os nomes das colunas da tabela SQL e as colunas do Excel são os mesmos, portanto, o mapeamento será feito automaticamente. Clique em Mapeamento para mapear as colunas. Veja a seguinte imagem:
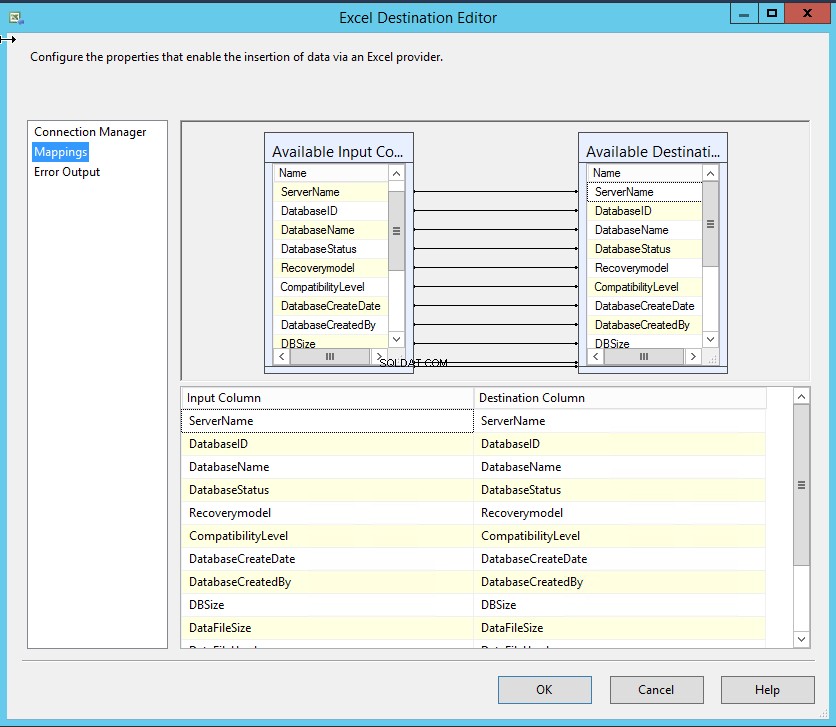
Clique duas vezes em Trabalhos SQL do Excel (Destino do Excel) no Editor de Destino do Excel .
- Selecione Gerenciador de conexões do Excel do gerenciador de conexões do Excel caixa suspensa.
- Selecione Ative ou Visualize do modo de acesso a dados caixa suspensa.
- Selecione "SQL Jobs$" no nome da planilha do Excel caixa suspensa.
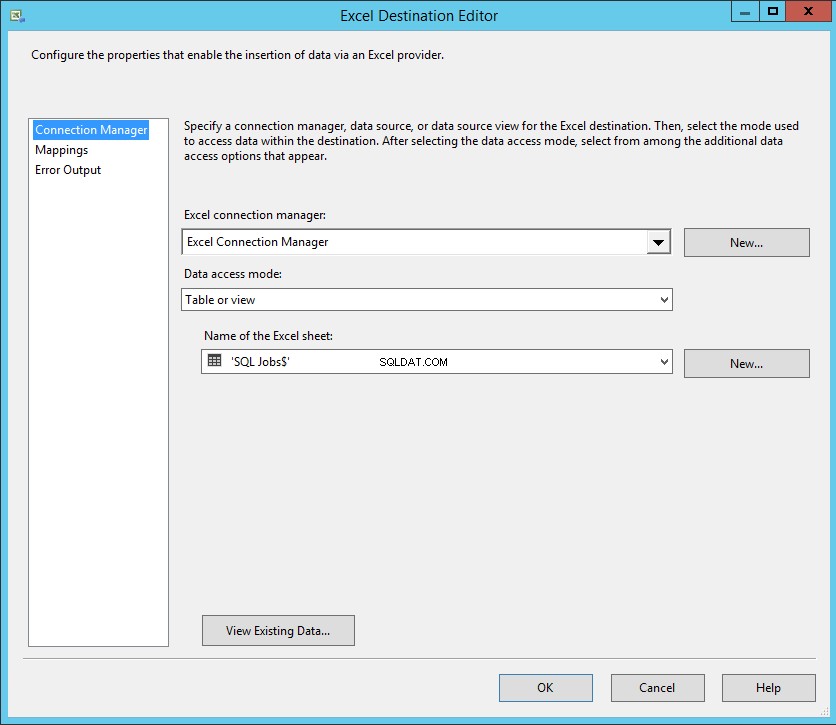
Como mencionei, os nomes das colunas da tabela SQL e as colunas do Excel são os mesmos, portanto, o mapeamento será feito automaticamente. Clique em Mapeamento para mapear as colunas. Veja a seguinte imagem:
Crie um trabalho SQL para enviar por e-mail o relatório do banco de dados
Depois que o pacote for criado, crie um trabalho SQL para realizar as seguintes atividades:
- Execute o pacote SSIS para preencher dados de todos os servidores.
- Envie o relatório do banco de dados por e-mail para a equipe necessária.
No SQL Job, precisamos criar duas etapas. A primeira etapa executará o pacote SSIS e a segunda etapa executará o procedimento para enviar um email.
Para criar um trabalho SQL, abra SSMS>> SQL Server Agent>> Clique com o botão direito do mouse em Novo trabalho SQL .
No Novo Emprego assistente, selecione a Etapa opção e clique em Não W. Na Etapa de Novo Trabalho caixa de diálogo, na Etapa nome caixa de texto, forneça o nome desejado, selecione Pacote de serviços de integração do SQL Server do Tipo caixa suspensa. Forneça um local do pacote SSIS no Texto do pacote caixa. Veja a seguinte imagem:
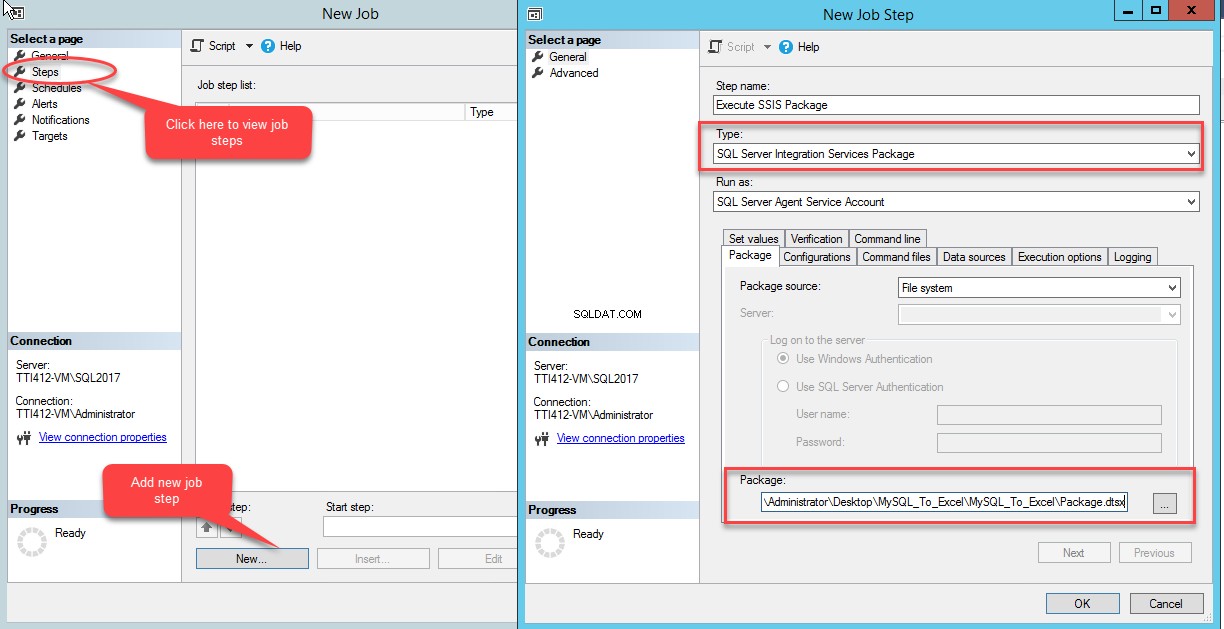
Clique em OK para fechar Nova etapa de trabalho .
Crie outra etapa de trabalho que executará um procedimento armazenado para enviar o relatório por e-mail. Ele usa um procedimento do sistema para enviar um e-mail. O pacote SSIS copia as informações do banco de dados em um local específico, portanto, forneça o caminho completo do arquivo excel no parâmetro @file_attachments de sp_send_dbmail procedimento armazenado.
Para criar o procedimento armazenado, execute o seguinte código no DBATools banco de dados do Servidor Central:
CREATE PROCEDURE Send_database_report AS BEGIN DECLARE @ProfileName VARCHAR(150) SET @ProfileName = (SELECT NAME FROM msdb..sysmail_profile WHERE profile_id = 7) DECLARE @lsMessage NVARCHAR(max) SET @lsMessage = '<p style="font-family:Arial; font-size:10pt"> Hello Support, Please find attached database summery report. ' + '</p>' EXEC msdb.dbo.Sp_send_dbmail @recipients='example@sqldat.com', @example@sqldat.com, @subject='Database Summery Report', @file_attachments= 'C:\Users\Administrator\Desktop\Database_Information.xlsx', @copy_recipients='', @blind_copy_recipients='', @body_format='HTML', @example@sqldat.com END
Once the procedure is created, add a new SQL Job step. Click New . In the New Job Step dialog box, provide a Job Step name, and select Transact-SQL script (T-SQL) from the Type drop-down box. In the Command Text box, write the following code:
USE DBAtools Go EXEC Send_database_report
See the following image:
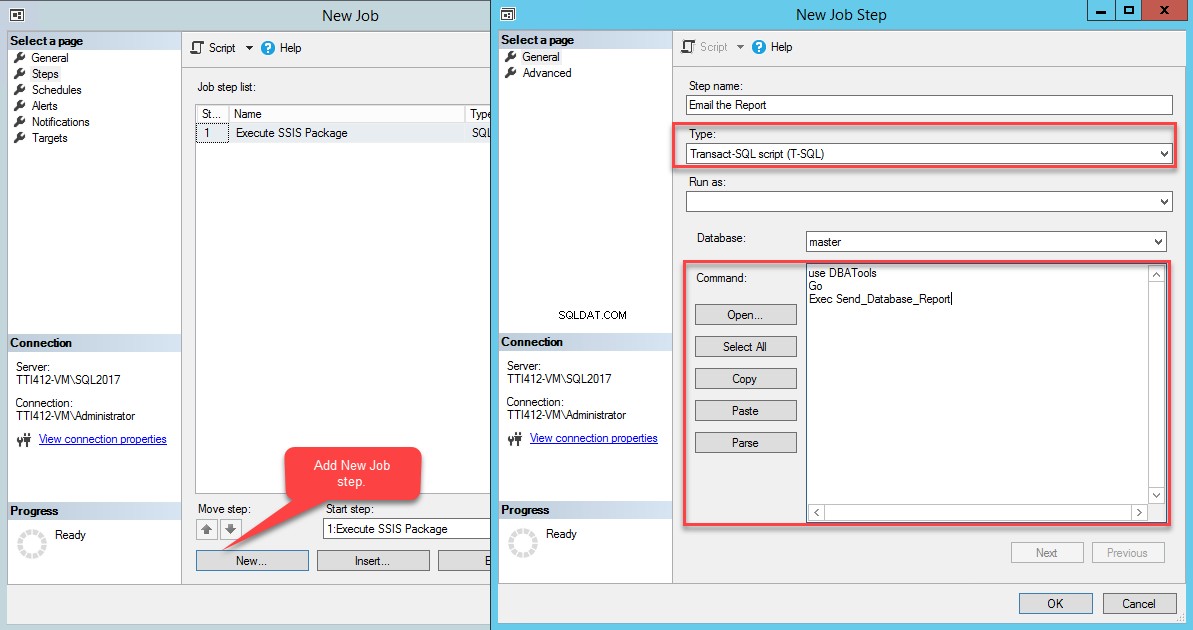
Click OK to close the wizard. Now to configure Job Schedule , select Schedules on the New Job janela. Click New to add a schedule.
In the New Job Schedule dialog box, provide the desired name in the Name text box, choose frequency and time. See the following image:
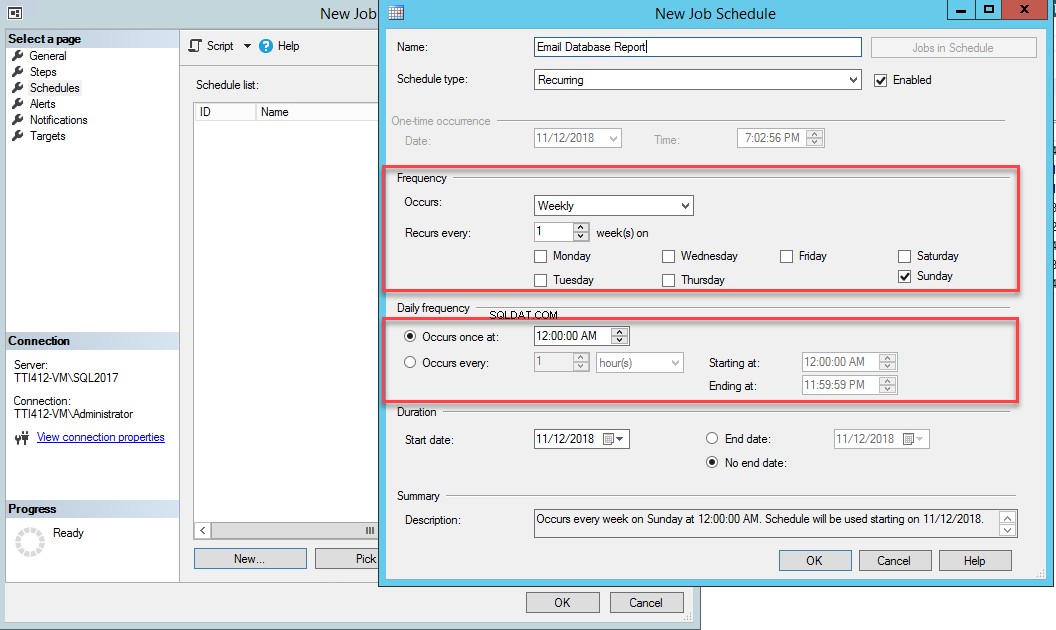
Close OK to close the New Job Schedule and in the New Job window, click on OK to close the dialog box.
Now, to test the SQL Job, right-click the Email Database Report SQL job and click Start Job at Step .
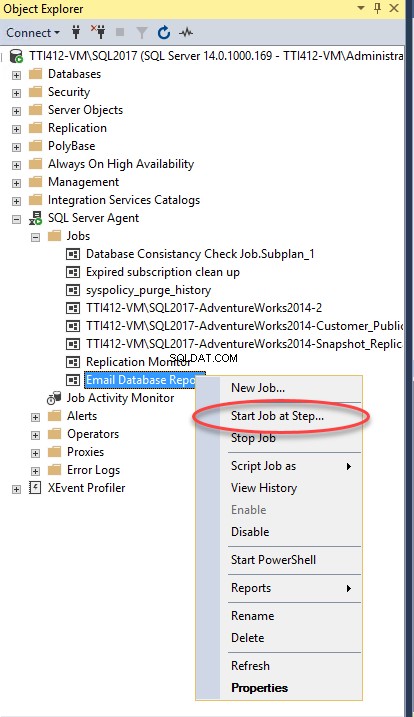
In the result of successful completion of the SQL Job, you will receive an email with the database report. See the following image:
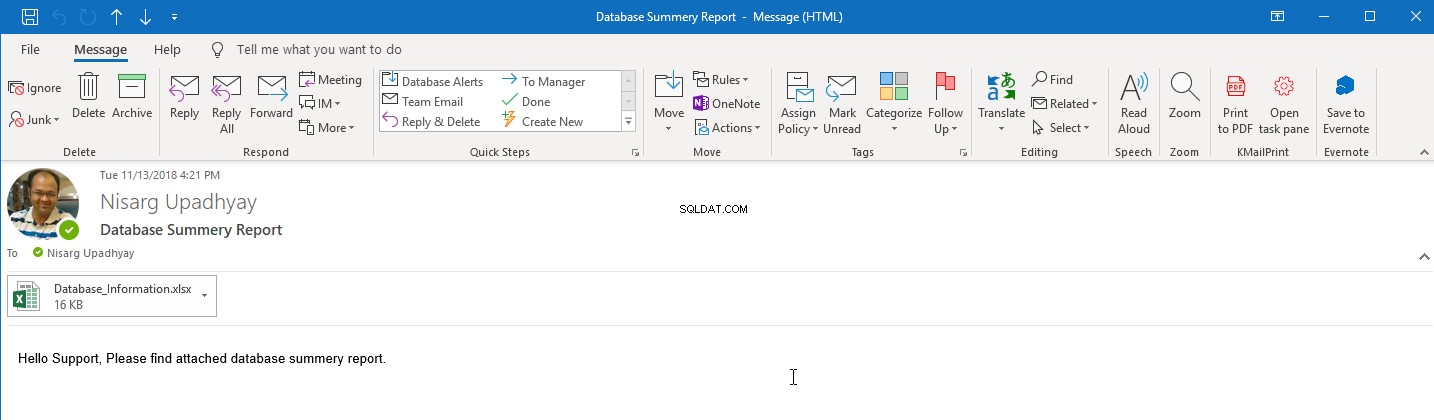
Summary
In this article I have covered as follows:
- How to populate information of the databases located on remote DB server.
- Create an SSIS package to populate database information and export it to excel file
- Create a multi-step SQL job to generate the report by executing an SSIS package and email the report.