Com a introdução do Banco de Dados SQL do Azure e a adição de mais funcionalidades na v12, os administradores de banco de dados estão começando a ver suas organizações mais interessadas em mover bancos de dados para essa plataforma.
Recentemente, comecei a mergulhar mais no Banco de Dados SQL do Azure para ver o que é drasticamente diferente do suporte à versão box em datacenters em todo o mundo e no Banco de Dados SQL do Azure. Em meu artigo anterior, "Ajuste:um bom lugar para começar", abordei minha abordagem para começar a ajustar o SQL Server. Decidi revisar isso no Banco de Dados SQL do Azure para descobrir as principais diferenças.
Em meu artigo original, comecei com configurações comuns em nível de instância que vejo ignoradas ou deixadas como padrão, bem como itens de manutenção. Isso inclui memória, maxdop, limite de custo para paralelismo, habilitação de otimização para cargas de trabalho ad hoc e configuração de tempdb. Com o Banco de Dados SQL do Azure, você não é responsável pela instância e não pode modificar essas configurações. O Banco de Dados SQL do Azure é uma Plataforma como Serviço (PaaS), o que significa que a Microsoft gerencia a instância para você; você é simplesmente um inquilino com seu banco de dados ou bancos de dados.
No entanto, você é responsável pela manutenção, portanto, precisa atualizar as estatísticas e lidar com a fragmentação do índice, como faz para o produto box. Para essas tarefas, descobri que a maioria dos clientes gerencia esses processos com uma VM do Azure dedicada executando o SQL Server e usando o SQL Server Agent com trabalhos agendados.
Seguindo as etapas do meu artigo, as próximas áreas que começo a investigar são estatísticas de arquivo e espera e consultas de alto custo. Se você está se perguntando se esse aspecto do seu trabalho como dba de produção com bancos de dados locais mudará ao trabalhar com o Banco de Dados SQL do Azure, a resposta é não realmente . As estatísticas de arquivo e espera ainda estão lá, mas temos que abordá-las de uma maneira um pouco diferente. Se você está acostumado a usar os scripts de Paul Randal para estatísticas de arquivos e estatísticas de espera (ou as consultas para estatísticas de arquivos por um período de tempo e estatísticas de espera por um período de tempo), então você terá que fazer algumas alterações para esses scripts para trabalhar com o Banco de Dados SQL do Azure.
Quando tentei pela primeira vez o script de estatísticas de arquivo de Paul, ele falhou devido ao Banco de Dados SQL do Azure não oferecer suporte a
sys.master_files :Msg 208, Level 16, State 1
Nome de objeto inválido 'sys.master_files'.
Consegui modificar o script para usar
sys.databases na junção para obter o nome do banco de dados e remover a parte do script para obter os nomes de arquivos individuais, pois estaremos lidando apenas com um único arquivo de dados e log. Você pode ver as alterações que tive que fazer na imagem a seguir: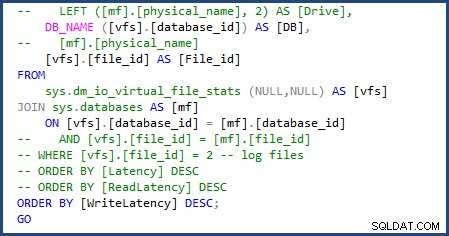
Quando executei o script file-stats-over-a-period-of-time depois, fazendo a mesma alteração em
sys.databases e removendo as referências a file_id na junção, ele falhou devido ao Banco de Dados SQL do Azure v12 não dar suporte a tabelas ##temp globais. Depois de alterar todas as tabelas ##temp globais para local, tive outro problema com o script incapaz de descartar as tabelas temporárias existentes que foram usadas, porque as tabelas #temp locais não podem ser referenciadas diretamente pelo nome da maneira que as tabelas ##temp globais podem, mas isso foi fácil de superar alterando essas verificações para
OBJECT_ID('tempdb..#SQLskillsStats1') . Fiz a mesma alteração para a segunda tabela temporária e atualizei o bloco de código no início e no final do script. Eu tive que fazer mais uma alteração e remover
[mf].[type_desc] e LEFT ([mf].[physical_name], 2) AS [Drive] uma vez que são dependentes de sys.master_files . O script foi então concluído e pronto para uso com o Banco de Dados SQL do Azure. Eu uso o arquivo-stats-over-a-period-of-time regularmente ao solucionar problemas de desempenho. Os dados cumulativos têm seu propósito, mas estou mais interessado em segmentos específicos de tempo em que as cargas de trabalho do usuário estão sendo executadas.
Com estatísticas de arquivo, estamos preocupados com nossa latência por arquivo de banco de dados e como podemos ajustar para ajudar a reduzir a E/S geral. A abordagem é a mesma do SQL Server, onde você precisa ajustar suas consultas corretamente e ter os índices corretos. Se a carga de trabalho for muito grande, você precisará migrar para uma camada de banco de dados DTU de desempenho mais rápido. Para mim, isso é ótimo:você apenas joga hardware nele; mas não é realmente hardware no sentido tradicional. Com o Banco de Dados SQL do Azure, você pode começar com um nível mais barato e dimensionar à medida que seus negócios e demandas de E/S crescem – basicamente, apenas mudando um botão.
Tentar encontrar o melhor método para obter estatísticas de espera foi mais fácil. O script padrão que muitos de nós usamos ainda funciona, mas está puxando as estatísticas de espera para o contêiner no qual seu banco de dados está sendo executado. Essas esperas ainda se aplicam ao seu sistema, mas podem incluir esperas incorridas por outros bancos de dados no mesmo contêiner. O Banco de Dados SQL do Azure contém um novo DMV,
sys.dm_db_wait_stats , que filtra para o banco de dados atual. Se você é como eu e usa principalmente o script de estatísticas de espera de Paul que omite todas as esperas benignas, basta alterar sys.dm_os_wait_stats para sys.dm_db_wait_stats . A mesma mudança também funciona para o script waits-over-a-period-of-time, mas você também precisa fazer a mudança de variáveis globais para locais. Quando se trata de encontrar consultas de alto custo, um dos meus scripts favoritos para executar encontra os planos de execução mais usados. Na minha experiência, ajustar uma consulta que é chamada 100.000 vezes por dia geralmente é uma vitória maior do que ajustar uma consulta que tem a E/S mais alta, mas é executada apenas uma vez por semana. A consulta a seguir é o que eu uso para encontrar os planos mais usados:
SELECT usecounts , cacheobjtype , objtype , [text]FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)WHERE usecounts> 1 AND objtype IN ( N'Adhoc', N'Prepared' )ORDER BY usecounts DESC;
Ao usar essa consulta em demonstrações, sempre libero o cache do meu plano para redefinir os valores. Quando tentei executarDBCC FREEPROCCACHEno Banco de Dados SQL do Azure, recebi o seguinte erro:
Acontece queDBCC FREEPROCCACHEnão tem suporte no Banco de Dados SQL do Azure. Isso foi preocupante para mim, e se eu estiver em produção e tiver alguns planos ruins e quiser limpar o cache de procedimentos como posso com a versão em caixa. Uma pequena pesquisa do Google/Bing me levou a encontrar o artigo da Microsoft, "Entendendo o Cache de Procedimento no SQL Azure", que afirma:
Atualmente, o SQL Azure não oferece suporte a DBCC FREEPROCCACHE (Transact-SQL), portanto, você não pode remover manualmente um plano de execução do cache. No entanto, se você fizer alterações na tabela ou visualização referenciada pela consulta (ALTER TABLE e ALTER VIEW), o plano será removido do cache.
Ao discutir isso com Kimberly Tripp depois de não ver o comportamento descrito, ele não libera o plano do cache, mas invalida o plano (e, em seguida, o plano acabará ficando fora do cache). Embora isso seja útil em certas situações, não era isso que eu precisava. Para minha demonstração, eu queria redefinir os contadores em sys.dm_exec_cached_plans. Gerar um novo plano não me daria os resultados desejados. Entrei em contato com minha equipe e Glenn Berry me disse para tentar o seguinte script:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
Este comando funcionou; Consegui limpar o cache de procedimento para o banco de dados específico. Configurações com escopo de banco de dados é um novo recurso adicionado no SQL Server 2016 RC0; Glenn escreveu sobre isso aqui:Usando ALTER DATABASE SCOPED CONFIGURATION no SQL Server 2016.
Estou animado para mover vários dos meus próprios bancos de dados para o Banco de Dados SQL do Azure e continuar aprendendo sobre os novos recursos e opções de escalabilidade. Também estou ansioso para trabalhar com o SentryOne DB Sentry, uma adição recente à plataforma SentryOne. Estou mais interessado em experimentar o painel de uso da DTU, que Mike Wood descreveu em seu post recente.