Kevin Kline (@kekline) e eu recentemente realizamos um webinar de ajuste de consulta (bem, um de uma série, na verdade), e uma das coisas que surgiram é a tendência das pessoas de criar qualquer índice ausente que o SQL Server diz que será uma coisa boa™ . Eles podem aprender sobre esses índices ausentes no Orientador de Otimização do Mecanismo de Banco de Dados (DTA), os DMVs de índice ausentes ou um plano de execução exibido no Management Studio ou no Plan Explorer (todos os quais apenas retransmitem informações exatamente do mesmo local):
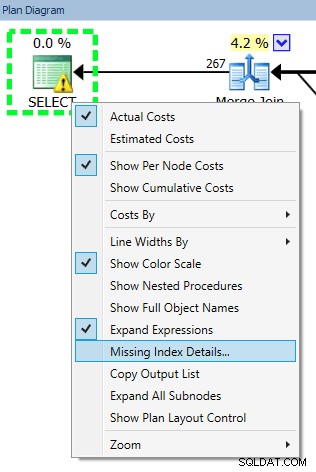
O problema com a criação cega desse índice é que o SQL Server decidiu que ele é útil para uma consulta específica (ou um punhado de consultas), mas ignora total e unilateralmente o restante da carga de trabalho. Como todos sabemos, os índices não são "gratuitos" – você paga pelos índices tanto no armazenamento bruto quanto pela manutenção necessária nas operações DML. Faz pouco sentido, em uma carga de trabalho de gravação pesada, adicionar um índice que ajude a tornar uma única consulta um pouco mais eficiente, especialmente se essa consulta não for executada com frequência. Nesses casos, pode ser muito importante entender sua carga de trabalho geral e encontrar um bom equilíbrio entre tornar suas consultas eficientes e não pagar muito por isso em termos de manutenção de índice.
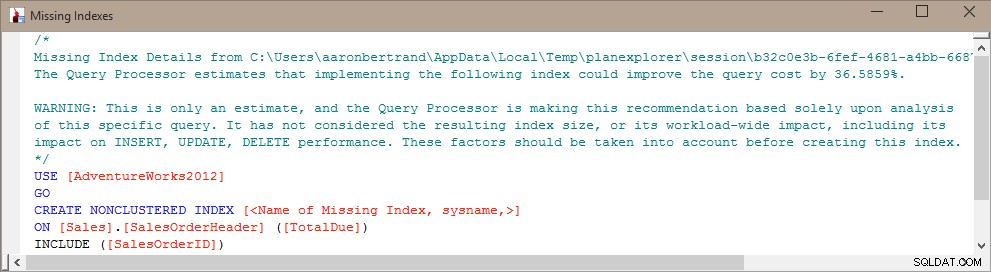
Portanto, uma ideia que tive foi "combinar" informações dos DMVs de índice ausentes, o DMV de estatísticas de uso do índice e informações sobre planos de consulta, para determinar que tipo de saldo existe atualmente e como a adição do índice pode se sair em geral.
Índices ausentes
Primeiro, podemos dar uma olhada nos índices ausentes que o SQL Server sugere atualmente:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Isso mostra a(s) tabela(s) e coluna(s) que seriam úteis em um índice, quantas compilações/busca/varreduras teriam sido usadas e quando o último evento desse tipo aconteceu para cada índice potencial. Você também pode incluir colunas como
s.avg_total_user_cost e s.avg_user_impact se você quiser usar esses números para priorizar. Planejar operações
Em seguida, vamos dar uma olhada nas operações usadas em todos os planos que armazenamos em cache em relação aos objetos que foram identificados por nossos índices ausentes.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Um amigo do dba.SE, Mikael Eriksson, sugeriu as duas consultas a seguir que, em um sistema maior, terão um desempenho muito melhor do que a consulta XML / UNION que montei acima, então você pode experimentar com elas primeiro. Seu comentário final foi que ele "não surpreendentemente descobriu que menos XML é uma coisa boa para o desempenho. :)" De fato.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc; Agora no
#planops table você tem vários valores para plan_handle para que você possa investigar cada um dos planos individuais em jogo contra os objetos que foram identificados como carentes de algum índice útil. Não vamos usá-lo para isso agora, mas você pode facilmente fazer uma referência cruzada com:SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Agora você pode clicar em qualquer um dos planos de saída para ver o que eles estão fazendo atualmente em relação aos seus objetos. Observe que alguns dos planos serão repetidos, pois um plano pode ter vários operadores que fazem referência a diferentes índices na mesma tabela.
Estatísticas de uso do índice
Em seguida, vamos dar uma olhada nas estatísticas de uso do índice, para que possamos ver quanta atividade real está sendo executada atualmente em nossas tabelas candidatas (e, principalmente, atualizações).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Não se assuste se muito poucos ou nenhum plano no cache mostrar atualizações para um índice específico, mesmo que as estatísticas de uso do índice mostrem que esses índices foram atualizados. Isso significa apenas que os planos de atualização não estão atualmente em cache, o que pode ser por vários motivos - por exemplo, pode ser uma carga de trabalho de leitura muito pesada e eles foram ultrapassados ou são todos únicos use e
optimize for ad hoc workloads está ativado. Juntando tudo
A consulta a seguir mostrará, para cada índice ausente sugerido, o número de leituras que um índice pode ter auxiliado, o número de gravações e leituras que foram capturadas atualmente em relação aos índices existentes, a proporção deles, o número de planos associados a esse objeto e o número total de contagens de uso para esses planos:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio]; Se sua taxa de gravação:leitura para esses índices já for> 1 (ou> 10!), acho que dá motivo para pausar antes de criar cegamente um índice que só poderia aumentar essa proporção. O número de
potential_read_ops mostrado, no entanto, pode compensar isso à medida que o número se torna maior. Se o potential_read_ops número é muito pequeno, você provavelmente vai querer ignorar a recomendação completamente antes mesmo de se preocupar em investigar as outras métricas – então você pode adicionar um WHERE cláusula para filtrar algumas dessas recomendações. Algumas notas:
- Essas são operações de leitura e gravação, não leituras e gravações medidas individualmente de 8 mil páginas.
- A proporção e as comparações são em grande parte educativas; pode muito bem ser o caso de 10.000.000 de operações de gravação afetarem uma única linha, enquanto 10 operações de leitura poderiam ter tido um impacto substancialmente maior. Isso é apenas uma diretriz aproximada e pressupõe que as operações de leitura e gravação tenham o mesmo peso.
- Você também pode usar pequenas variações em algumas dessas consultas para descobrir – fora os índices ausentes que o SQL Server está recomendando – quantos de seus índices atuais são um desperdício. Há muitas ideias sobre isso online, incluindo esta postagem de Paul Randal (@PaulRandal).
Espero que dê algumas idéias para obter mais informações sobre o comportamento do seu sistema antes de decidir adicionar um índice que alguma ferramenta lhe disse para criar. Eu poderia ter criado isso como uma consulta massiva, mas acho que as partes individuais lhe darão alguns buracos de coelho para investigar, se desejar.
Outras notas
Você também pode estender isso para capturar métricas de tamanho atual, a largura da tabela e o número de linhas atuais (assim como quaisquer previsões sobre crescimento futuro); isso pode lhe dar uma boa ideia de quanto espaço um novo índice irá ocupar, o que pode ser uma preocupação dependendo do seu ambiente. Posso tratar disso em um post futuro.
Claro, você deve ter em mente que essas métricas são tão úteis quanto o seu tempo de atividade determina. Os DMVs são limpos após uma reinicialização (e às vezes em outros cenários menos perturbadores), portanto, se você acha que essas informações serão úteis por um longo período de tempo, tirar instantâneos periódicos pode ser algo que você deseja considerar.