Agora, nossa comunidade de análise de big data começou a usar o Apache Spark a todo vapor para processamento de big data. O processamento pode ser feito para consultas ad-hoc, consultas pré-construídas, processamento de gráficos, aprendizado de máquina e até mesmo para streaming de dados.
Portanto, a compreensão do envio de trabalhos do Spark é muito vital para a comunidade. Estenda para o prazer de compartilhar com você os aprendizados das etapas envolvidas no envio de trabalho do Apache Spark.
Basicamente tem duas etapas,

Envio de trabalho
O trabalho do Spark é enviado automaticamente quando uma ação como count () é executada em um RDD.
RunJob() internamente para ser chamado no SparkContext e, em seguida, chamar o agendador que é executado como parte do derivador.
O agendador é composto de 2 partes – Agendador DAG e Agendador de Tarefas.
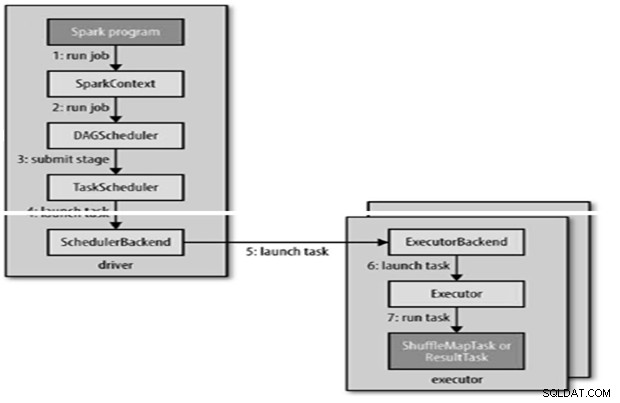
Construção de DAG
Existem dois tipos de construções de DAG,

- O trabalho simples do Spark é aquele que não precisa de embaralhamento e, portanto, tem apenas um único estágio composto por tarefas de resultado, como o trabalho somente mapa no MapReduce
- O trabalho complexo do Spark envolve operações de agrupamento e requer um ou mais estágios de embaralhamento.
- O agendador de DAG do Spark transforma o trabalho em dois estágios.
- O agendador DAG é responsável por dividir um estágio em tarefas para envio ao agendador de tarefas.
- Cada tarefa recebe uma preferência de posicionamento do agendador do DAG para permitir que o agendador de tarefas aproveite a localidade dos dados.
- As etapas dos filhos só são enviadas quando os pais são concluídos com êxito.
Agendamento de tarefas
- O Agendador de Tarefas enviará um conjunto de tarefas; ele usa sua lista de executores que estão sendo executados para o aplicativo e constrói um mapeamento de tarefas para executores que leva em consideração as preferências de posicionamento.
- O Agendador de Tarefas atribui a executores que possuem núcleos livres, cada tarefa recebe um núcleo por padrão. Ele pode ser alterado pelo parâmetro spark.task.cpus.
- O Spark usa o Akka, que é uma plataforma baseada em atores para criar aplicativos distribuídos orientados a eventos altamente escaláveis.
- O Spark não usa o Hadoop RPC para chamadas remotas.
Execução de tarefas
Um executor executa uma tarefa da seguinte forma,
- Ele garante que o JAR e as dependências de arquivo para a tarefa estejam atualizados.
- Desserializa o código da tarefa.
- O código da tarefa é executado.
- A tarefa retorna os resultados ao driver, que os reúne em um resultado final para retornar ao usuário.
Referência
- Guia definitivo do Hadoop
- Comunidade de código aberto do Analytics e Big Data
Este artigo apareceu originalmente aqui. Republicado com permissão. Envie suas reclamações de direitos autorais aqui.