Se você usar o particionamento de tabela com uma ou mais partições armazenadas em um grupo de arquivos somente leitura, as instruções SQL update e delete poderão falhar com um erro. Obviamente, esse é o comportamento esperado se qualquer uma das modificações exigir a gravação em um grupo de arquivos somente leitura; no entanto, também é possível encontrar essa condição de erro em que as alterações são restritas a grupos de arquivos marcados como leitura-gravação.
Banco de dados de amostra
Para demonstrar o problema, criaremos um banco de dados simples com um único grupo de arquivos personalizado que marcaremos posteriormente como somente leitura. Observe que você precisará adicionar o caminho do nome do arquivo para se adequar à sua instância de teste.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Função e esquema de partição
Agora criaremos uma função e um esquema de particionamento básico que direcionará linhas com dados antes de 1º de janeiro de 2000 para a partição somente leitura. Os dados posteriores serão mantidos no grupo de arquivos primário de leitura e gravação:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); A especificação de intervalo direito significa que as linhas com o valor limite de 1º de janeiro de 2000 estarão na partição de leitura-gravação.
Tabela e índices particionados
Agora podemos criar nossa tabela de teste:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); A tabela tem uma chave primária clusterizada na coluna datetime e também é particionada nessa coluna. Existem índices não clusterizados nas outras duas colunas inteiras, que são particionadas da mesma maneira (os índices são alinhados com a tabela base).
Dados de amostra
Por fim, adicionamos algumas linhas de dados de exemplo e tornamos a partição de dados anterior a 2000 somente leitura:
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY; Você pode usar as seguintes instruções de atualização de teste para confirmar que os dados na partição somente leitura não podem ser modificados, enquanto os dados com um
dt valor em ou após 1º de janeiro de 2000 pode ser escrito para:-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; Uma falha inesperada
Temos duas linhas:uma somente leitura (1999-12-31); e uma leitura-escrita (2000-01-01):

Agora tente a seguinte consulta. Ele identifica a mesma linha gravável "2000-01-01" que acabamos de atualizar com sucesso, mas usa um predicado de cláusula where diferente:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
O plano estimado (pré-execução) é:

Os quatro (!) Compute Scalars não são importantes para esta discussão. Eles são usados para determinar se o índice não clusterizado precisa ser mantido para cada linha que chega ao operador Clustered Index Update.
O mais interessante é que esta declaração de atualização falha com um erro semelhante a:
Msg 652, Level 16, State 1
O índice "PK_dbo_Test__c1_dt" para a tabela "dbo.Test" (RowsetId 72057594039042048) reside em um grupo de arquivos somente leitura ("ReadOnlyFileGroup"), que não pode ser modificado.
Não eliminação de partição
Se você já trabalhou com particionamento antes, pode estar pensando que a 'eliminação de partição' pode ser o motivo. A lógica seria algo assim:
Nas instruções anteriores, um valor literal para a coluna de particionamento era fornecido na cláusula where, para que o SQL Server pudesse determinar imediatamente quais partições acessar. Ao alterar a cláusula where para não fazer mais referência à coluna de particionamento, forçamos o SQL Server a acessar todas as partições usando uma Verificação de índice clusterizado.
Isso é tudo verdade, em geral, mas não é a razão pela qual a instrução de atualização falha aqui.
O comportamento esperado é que o SQL Server seja capaz de ler de todas e quaisquer partições durante a execução da consulta. Uma operação de modificação de dados deve apenas falhar se o mecanismo de execução realmente tentar modificar uma linha armazenada em um grupo de arquivos somente leitura.
Para ilustrar, vamos fazer uma pequena alteração na consulta anterior:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; A cláusula where é exatamente a mesma de antes. A única diferença é que agora estamos (deliberadamente) definindo a coluna de particionamento igual a si mesma. Isso não alterará o valor armazenado nessa coluna, mas afetará o resultado. A atualização agora é bem-sucedida (embora com um plano de execução mais complexo):

O otimizador introduziu novos operadores Split, Sort e Collapse e adicionou o maquinário necessário para manter cada índice não clusterizado potencialmente afetado separadamente (usando uma estratégia ampla ou por índice).
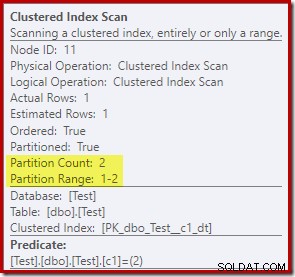
As propriedades do Clustered Index Scan mostram que ambas as partições da tabela foram acessados ao ler:
Por outro lado, a atualização do índice clusterizado mostra que apenas a partição de leitura e gravação foi acessada para gravação:
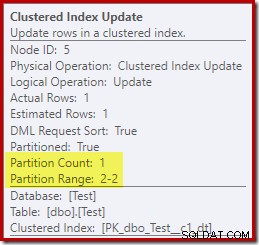
Cada um dos operadores Nonclustered Index Update mostra informações semelhantes:apenas a partição gravável (#2) foi modificada em tempo de execução, portanto, nenhum erro ocorreu.
O motivo revelado
O novo plano tem sucesso não porque os índices não clusterizados são mantidos separadamente; nem é (diretamente) devido à combinação Split-Sort-Collapse necessária para evitar erros transitórios de chave duplicada no índice exclusivo.
O motivo real é algo que mencionei brevemente em meu artigo anterior, "Otimizando consultas de atualização" – uma otimização interna conhecida como Compartilhamento de conjunto de linhas . Quando isso é usado, a atualização de índice clusterizado compartilha o mesmo conjunto de linhas do mecanismo de armazenamento subjacente como uma verificação de índice clusterizado, busca ou pesquisa de chave no lado de leitura do plano.
Com a otimização de Compartilhamento de Conjunto de Linhas, o SQL Server verifica grupos de arquivos off-line ou somente leitura ao ler. Nos planos em que a Atualização do Índice Clusterizado usa um conjunto de linhas separado, a verificação off-line/somente leitura é executada apenas para cada linha no iterador de atualização (ou exclusão).
Soluções não documentadas
Vamos tirar as coisas divertidas, nerds, mas impraticáveis, primeiro.
A otimização do conjunto de linhas compartilhado só pode ser aplicada quando a rota do índice clusterizado busca, varredura ou pesquisa de chave é um pipeline . Não são permitidos operadores de bloqueio ou semibloqueio. Dito de outra forma, cada linha deve ser capaz de ir da fonte de leitura para o destino de gravação antes que a próxima linha seja lida.
Como lembrete, aqui estão os dados de amostra, a instrução e o plano de execução para o falhou atualize novamente:
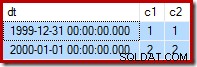
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Proteção de Halloween
Uma maneira de introduzir um operador de bloqueio no plano é exigir a Proteção de Halloween (HP) explícita para esta atualização. Separar a leitura da gravação com um operador de bloqueio impedirá que a otimização de compartilhamento do conjunto de linhas seja usada (sem pipeline). O sinalizador de rastreamento 8692 não documentado e sem suporte (somente sistema de teste!) adiciona um Eager Table Spool para HP explícito:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
O plano de execução real (disponível porque o erro não é mais lançado) é:

A combinação Sort in the Split-Sort-Collapse vista na atualização bem-sucedida anterior fornece o bloqueio necessário para desabilitar o compartilhamento do conjunto de linhas nessa instância.
O sinalizador de rastreamento de compartilhamento anti-rowset
Há outro sinalizador de rastreamento não documentado que desativa a otimização de compartilhamento do conjunto de linhas. Isso tem a vantagem de não introduzir um operador de bloqueio potencialmente caro. Ele não pode ser usado na prática, é claro (a menos que você entre em contato com o Suporte da Microsoft e obtenha algo por escrito recomendando que você o habilite, suponho). No entanto, para fins de entretenimento, aqui está o sinalizador de rastreamento 8746 em ação:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
O plano de execução real para essa instrução é:

Sinta-se à vontade para experimentar valores diferentes (aqueles que realmente alteram os valores armazenados, se desejar) para se convencer da diferença aqui. Conforme mencionado na minha postagem anterior, você também pode usar o sinalizador de rastreamento não documentado 8666 para expor a propriedade de compartilhamento do conjunto de linhas no plano de execução.
Se você quiser ver o erro de compartilhamento do conjunto de linhas com uma instrução delete, basta substituir as cláusulas update e set por uma delete, enquanto usa a mesma cláusula where.
Soluções alternativas compatíveis
Há várias maneiras possíveis de garantir que o compartilhamento de conjunto de linhas não seja aplicado em consultas do mundo real sem usar sinalizadores de rastreamento. Agora que você sabe que o problema principal requer um plano de leitura e gravação de índice clusterizado compartilhado e em pipeline, você provavelmente pode criar o seu próprio. Mesmo assim, há alguns exemplos que valem a pena ser vistos aqui.
Índice forçado/índice de cobertura
Uma ideia natural é forçar o lado de leitura do plano a usar um índice não clusterizado em vez do índice clusterizado. Não podemos adicionar uma dica de índice diretamente à consulta de teste conforme escrito, mas o alias da tabela permite isso:
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Isso pode parecer a solução que o otimizador de consulta deveria ter escolhido em primeiro lugar, já que temos um índice não clusterizado na coluna de predicado da cláusula where c1. O plano de execução mostra por que o otimizador escolheu como escolheu:
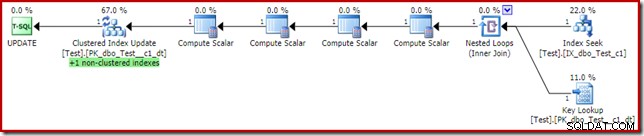
O custo do Key Lookup é suficiente para convencer o otimizador a usar o índice clusterizado para leitura. A pesquisa é necessária para buscar o valor atual da coluna c2, para que os Compute Scalars possam decidir se o índice não clusterizado precisa ser mantido.
Adicionar a coluna c2 ao índice não clusterizado (chave ou inclusão) evitaria o problema. O otimizador escolheria o índice que agora cobre em vez do índice clusterizado.
Dito isto, nem sempre é possível antecipar quais colunas serão necessárias, ou incluir todas elas mesmo que o conjunto seja conhecido. Lembre-se, a coluna é necessária porque c2 está na cláusula set da declaração de atualização. Se as consultas forem ad-hoc (por exemplo, enviadas por usuários ou geradas por uma ferramenta), cada índice não clusterizado precisaria incluir todas as colunas para tornar essa opção robusta.
Uma coisa interessante sobre o plano com o Key Lookup acima é que ele não gerar um erro. Isso ocorre apesar da pesquisa de chave e atualização de índice clusterizado usando um conjunto de linhas compartilhado. A razão é que o Index Seek não clusterizado localiza a linha com c1 =2 antes o Key Lookup toca o índice clusterizado. A verificação do conjunto de linhas compartilhado para grupos de arquivos off-line/somente leitura ainda é executada na pesquisa, mas não toca na partição somente leitura, portanto, nenhum erro é gerado. Como um ponto de interesse final (relacionado), observe que o Index Seek toca as duas partições, mas o Key Lookup atinge apenas uma.
Excluindo a partição somente leitura
Uma solução trivial é contar com a eliminação de partições para que o lado de leitura do plano nunca toque a partição somente leitura. Isso pode ser feito com um predicado explícito, por exemplo, qualquer um destes:
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Quando for impossível, ou inconveniente, alterar cada consulta para adicionar um predicado de eliminação de partição, outras soluções, como a atualização por meio de uma exibição, podem ser adequadas. Por exemplo:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; Uma desvantagem de usar uma exibição é que uma atualização ou exclusão que visa a parte somente leitura da tabela base será bem-sucedida sem nenhuma linha afetada, em vez de falhar com um erro. Um gatilho em vez de na tabela ou visualização pode ser uma solução alternativa para isso em algumas situações, mas também pode apresentar mais problemas... mas eu discordo.
Como mencionado anteriormente, existem muitas soluções com suporte em potencial. O objetivo deste artigo é mostrar como o compartilhamento do conjunto de linhas causou o erro de atualização inesperado.



