Qualquer programador lhe dirá que escrever código multi-thread seguro pode ser difícil. Requer muito cuidado e uma boa compreensão das questões técnicas envolvidas. Como uma pessoa de banco de dados, você pode pensar que esses tipos de dificuldades e complicações não se aplicam ao escrever T-SQL. Portanto, pode ser um pouco chocante perceber que o código T-SQL também é vulnerável ao tipo de condições de corrida e outros riscos de integridade de dados mais comumente associados à programação multithread. Isso é verdade se estamos falando de uma única instrução T-SQL ou de um grupo de instruções contidas em uma transação explícita.
No centro da questão está o fato de que os sistemas de banco de dados permitem que várias transações sejam executadas ao mesmo tempo. Este é um estado de coisas bem conhecido (e muito desejável), mas uma grande quantidade de código T-SQL de produção ainda assume silenciosamente que os dados subjacentes não mudam durante a execução de uma transação ou uma única instrução DML como
SELECT , INSERT , UPDATE , DELETE , ou MERGE . Mesmo quando o autor do código está ciente dos possíveis efeitos de alterações simultâneas de dados, o uso de transações explícitas é muitas vezes considerado para fornecer mais proteção do que realmente justificado. Essas suposições e equívocos podem ser sutis e certamente são capazes de enganar até mesmo praticantes de banco de dados experientes.
Agora, há casos em que essas questões não importarão muito no sentido prático. Por exemplo, o banco de dados pode ser somente leitura ou pode haver alguma outra garantia genuína que ninguém mais alterará os dados subjacentes enquanto estivermos trabalhando com eles. Da mesma forma, a operação em questão pode não requerer resultados que são exatamente correto; nossos consumidores de dados podem ficar perfeitamente satisfeitos com um resultado aproximado (mesmo um que não represente o estado comprometido do banco de dados em qualquer ponto no tempo).
Problemas de simultaneidade
A questão da interferência entre tarefas executadas simultaneamente é um problema familiar para desenvolvedores de aplicativos que trabalham em linguagens de programação como C# ou Java. As soluções são muitas e variadas, mas geralmente envolvem o uso de operações atômicas ou obter um recurso mutuamente exclusivo (como um bloqueio ) enquanto uma operação sensível está em andamento. Onde as precauções adequadas não são tomadas, os resultados prováveis são dados corrompidos, um erro ou talvez até mesmo uma falha completa.
Muitos dos mesmos conceitos (por exemplo, operações atômicas e bloqueios) existem no mundo do banco de dados, mas infelizmente eles geralmente têm diferenças cruciais de significado . A maioria das pessoas de banco de dados está ciente das propriedades ACID das transações de banco de dados, onde o A significa atomic . O SQL Server também usa bloqueios (e outros dispositivos de exclusão mútua internamente). Nenhum desses termos significa exatamente o que um programador experiente de C# ou Java esperaria razoavelmente, e muitos profissionais de banco de dados também têm uma compreensão confusa desses tópicos (como uma pesquisa rápida usando seu mecanismo de pesquisa favorito atestará).
Para reiterar, às vezes essas questões não serão uma preocupação prática. Se você escrever uma consulta para contar o número de pedidos ativos em um sistema de banco de dados, quão importante é se a contagem estiver um pouco errada? Ou se reflete o estado do banco de dados em algum outro momento?
É comum que sistemas reais façam um trade-off entre simultaneidade e consistência (mesmo que o projetista não estivesse consciente disso no momento – informado trade-offs são talvez um animal mais raro). Sistemas reais geralmente funcionam bem o suficiente , com quaisquer anomalias de curta duração ou consideradas sem importância. Um usuário que vê um estado inconsistente em uma página da Web geralmente resolve o problema atualizando a página. Se o problema for relatado, provavelmente será fechado como Não Reprodutível. Não estou dizendo que este é um estado de coisas desejável, apenas reconhecendo que isso acontece.
No entanto, é tremendamente útil entender as questões de simultaneidade em um nível fundamental. Estar ciente deles nos permite escrever corretamente (ou informados correto o suficiente) T-SQL conforme as circunstâncias exigem. Mais importante, isso nos permite evitar escrever T-SQL que possa comprometer a integridade lógica de nossos dados.
Mas o SQL Server oferece garantias ACID!
Sim, mas eles nem sempre são o que você esperaria e não protegem tudo. Na maioria das vezes, os humanos leem muito mais em ACID do que se justifica.
Os componentes mais frequentemente incompreendidos do acrônimo ACID são as palavras Atômica, Consistente e Isolada – chegaremos a elas em um momento. O outro, Durável , é intuitivo o suficiente, desde que você se lembre de que se aplica apenas a persistente (recuperável) usuário dados.
Com tudo isso dito, o SQL Server 2014 começa a confundir um pouco os limites da propriedade Durable com a introdução da durabilidade atrasada geral e durabilidade somente do esquema OLTP na memória. Menciono-os apenas para completar, não discutiremos mais esses novos recursos. Vamos passar para as propriedades ACID mais problemáticas:
A Propriedade Atômica
Muitas linguagens de programação fornecem operações atômicas que pode ser usado para proteger contra condições de corrida e outros efeitos de simultaneidade indesejáveis, onde vários threads de execução podem acessar ou modificar estruturas de dados compartilhadas. Para o desenvolvedor de aplicativos, uma operação atômica vem com uma garantia explícita de isolamento completo dos efeitos de outro processamento simultâneo em um programa multithread.
Uma situação análoga surge no mundo do banco de dados, onde várias consultas T-SQL acessam e modificam simultaneamente dados compartilhados (ou seja, o banco de dados) de diferentes threads. Observe que não estamos falando de consultas paralelas aqui; consultas de thread único comuns são agendadas rotineiramente para serem executadas simultaneamente no SQL Server em threads de trabalho separados.
Infelizmente, a propriedade atômica das transações SQL garante apenas que as modificações de dados realizadas em uma transação sucesso ou falha como uma unidade . Nada mais do que isso. Certamente não há garantia de isolamento completo dos efeitos de outros processamentos simultâneos. Observe também de passagem que a propriedade de transação atômica não diz nada sobre quaisquer garantias sobre leitura dados.
Declarações únicas
Também não há nada de especial em uma declaração única no SQL Server. Onde uma transação contendo explícito (
BEGIN TRAN...COMMIT TRAN ) não existir, uma única instrução DML ainda será executada em uma transação de confirmação automática. As mesmas garantias ACID se aplicam a uma única declaração, e as mesmas limitações também. Em particular, uma única instrução vem sem garantias especiais de que os dados não serão alterados enquanto estiverem em andamento. Considere a seguinte consulta do brinquedo AdventureWorks:
SELECT
TH.TransactionID,
TH.ProductID,
TH.ReferenceOrderID,
TH.ReferenceOrderLineID,
TH.TransactionDate,
TH.TransactionType,
TH.Quantity,
TH.ActualCost
FROM Production.TransactionHistory AS TH
WHERE TH.ReferenceOrderID =
(
SELECT TOP (1)
TH2.ReferenceOrderID
FROM Production.TransactionHistory AS TH2
WHERE TH2.TransactionType = N'P'
ORDER BY
TH2.Quantity DESC,
TH2.ReferenceOrderID ASC
); A consulta destina-se a exibir informações sobre o pedido classificado em primeiro lugar por quantidade. O plano de execução é o seguinte:
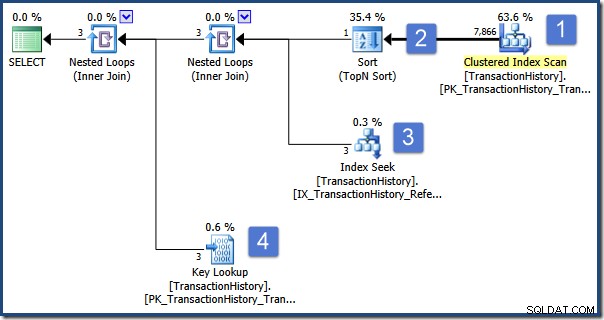
As principais operações deste plano são:
- Verifique a tabela para encontrar linhas com o tipo de transação necessário
- Encontre o ID do pedido que classifica mais alto de acordo com a especificação na subconsulta
- Encontre as linhas (na mesma tabela) com o ID do pedido selecionado usando um índice não clusterizado
- Procure os dados restantes da coluna usando o índice clusterizado
Agora imagine que um usuário simultâneo modifique o Order 495, alterando seu Tipo de Transação de P para W, e confirme essa alteração no banco de dados. Por sorte, essa modificação ocorre enquanto nossa consulta está realizando a operação de classificação (etapa 2).
Quando a classificação é concluída, a busca de índice na etapa 3 encontra as linhas com o ID do pedido selecionado (que é 495) e a pesquisa de chave na etapa 4 busca as colunas restantes da tabela base (onde o tipo de transação agora é W) .
Essa sequência de eventos significa que nossa consulta produz um resultado aparentemente impossível:

Em vez de encontrar pedidos com o tipo de transação P conforme a consulta especificada, os resultados mostram o tipo de transação W.
A causa raiz é clara:nossa consulta assumiu implicitamente que os dados não poderiam ser alterados enquanto nossa consulta de instrução única estava em andamento. A janela de oportunidade neste caso foi relativamente grande devido à classificação de bloqueio, mas o mesmo tipo de condição de corrida pode ocorrer em qualquer estágio da execução da consulta, em geral. Naturalmente, os riscos geralmente são maiores com níveis maiores de modificações simultâneas, tabelas maiores e onde os operadores de bloqueio aparecem no plano de consulta.
Outro mito persistente na mesma área geral é que
MERGE é preferível ao INSERT separado , UPDATE e DELETE porque a instrução única MERGE é atômico. Isso é um absurdo, claro. Voltaremos a esse tipo de raciocínio mais adiante na série. A mensagem geral neste ponto é que, a menos que etapas explícitas sejam tomadas para garantir o contrário, as linhas de dados e as entradas de índice podem mudar, mover a posição ou desaparecer completamente a qualquer momento durante o processo de execução. É bom ter em mente uma imagem mental de mudanças constantes e aleatórias no banco de dados ao escrever consultas T-SQL.
A propriedade de consistência
A segunda palavra da sigla ACID também tem uma gama de interpretações possíveis. Em um banco de dados SQL Server, Consistência significa somente que uma transação deixa o banco de dados em um estado que não viola nenhuma restrição ativa. É importante avaliar completamente o quão limitada é essa declaração:As únicas garantias ACID de integridade de dados e consistência lógica são aquelas fornecidas por restrições ativas.
O SQL Server fornece uma gama limitada de restrições para impor a integridade lógica, incluindo
PRIMARY KEY , FOREIGN KEY , CHECK , UNIQUE e NOT NULL . Todos eles são garantidos para serem satisfeitos no momento em que uma transação é confirmada. Além disso, o SQL Server garante a segurança física integridade do banco de dados em todos os momentos, é claro. As restrições internas nem sempre são suficientes para impor todas as regras de integridade de negócios e de dados que gostaríamos. Certamente é possível ser criativo com as facilidades padrão, mas elas rapidamente se tornam complexas e podem resultar no armazenamento de dados duplicados.
Como consequência, a maioria dos bancos de dados reais contém pelo menos algumas rotinas T-SQL escritas para impor regras adicionais, por exemplo, em procedimentos armazenados e gatilhos. A responsabilidade por garantir que este código funcione corretamente é inteiramente do autor – a propriedade Consistency não fornece proteções específicas.
Para enfatizar o ponto, as pseudo-restrições escritas em T-SQL devem ser executadas corretamente, não importa quais modificações simultâneas possam estar ocorrendo. Um desenvolvedor de aplicativos pode proteger uma operação confidencial como essa com uma instrução de bloqueio. A coisa mais próxima que os programadores T-SQL têm desse recurso para procedimento armazenado em risco e código de gatilho é o
sp_getapplock comparativamente raramente usado procedimento armazenado do sistema. Isso não quer dizer que seja a única opção, ou mesmo preferida, apenas que existe e pode ser a escolha certa em algumas circunstâncias. A propriedade de isolamento
Esta é facilmente a mais incompreendida das propriedades da transação ACID.
Em princípio, um completamente isolado transação é executada como a única tarefa em execução no banco de dados durante seu tempo de vida. Outras transações só podem ser iniciadas quando a transação atual for completamente concluída (ou seja, confirmada ou revertida). Executada dessa maneira, uma transação seria realmente uma operação atômica , no sentido estrito que uma pessoa que não usa banco de dados atribuiria à frase.
Na prática, as transações de banco de dados operam com um grau de isolamento especificado pelo nível de isolamento de transação atualmente efetivo (que se aplica igualmente a instruções independentes, lembre-se). Este compromisso (o grau de isolamento) é a consequência prática dos trade-offs entre simultaneidade e correção mencionados anteriormente. Um sistema que literalmente processasse transações uma a uma, sem sobreposição no tempo, forneceria isolamento completo, mas a taxa de transferência geral do sistema provavelmente seria ruim.
Próxima vez
A próxima parte desta série continuará o exame de problemas de simultaneidade, propriedades ACID e isolamento de transações com uma análise detalhada do nível de isolamento serializável, outro exemplo de algo que pode não significar o que você acha que significa.
[ Veja o índice para toda a série ]