Observação:esta postagem foi publicada originalmente apenas em nosso eBook, Técnicas de alto desempenho para SQL Server, Volume 3. Você pode descobrir mais sobre nossos eBooks aqui.
Um requisito que vejo ocasionalmente é ter uma consulta retornada com pedidos agrupados por cliente, mostrando o total máximo devido visto para qualquer pedido até o momento (um "máximo em execução"). Então imagine essas linhas de amostra:
| ID do pedido de vendas | ID do cliente | Data do pedido | Total vencido |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37,55 |
| 23 | 1 | 2014-01-02 | 45,29 |
| 31 | 2 | 2014-01-03 | 24,56 |
| 32 | 2 | 2014-01-04 | 89,84 |
| 37 | 1 | 2014-01-05 | 32,56 |
| 44 | 2 | 2014-01-06 | 45,54 |
| 55 | 1 | 2014-01-07 | 99,24 |
| 62 | 2 | 2014-01-08 | 12,55 |
Algumas linhas de dados de amostra
Os resultados desejados dos requisitos declarados são os seguintes – em termos simples, classifique os pedidos de cada cliente por data e liste cada pedido. Se esse for o valor TotalDue mais alto para todos os pedidos vistos até essa data, imprima o total desse pedido, caso contrário, imprima o valor TotalDue mais alto de todos os pedidos anteriores:
| ID do pedido de vendas | ID do cliente | Data do pedido | Total vencido | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45,29 | 45,29 |
| 23 | 1 | 2014-01-05 | 32,56 | 45,29 |
| 31 | 1 | 2014-01-07 | 99,24 | 99,24 |
| 32 | 2 | 2014-01-01 | 37,55 | 37,55 |
| 37 | 2 | 2014-01-03 | 24,56 | 37,55 |
| 44 | 2 | 2014-01-04 | 89,84 | 89,84 |
| 55 | 2 | 2014-01-06 | 45,54 | 89,84 |
| 62 | 2 | 2014-01-08 | 12,55 | 89,84 |
Exemplo de resultados desejados
Muitas pessoas instintivamente gostariam de usar um cursor ou loop while para fazer isso, mas existem várias abordagens que não envolvem essas construções.
Subconsulta correlacionada
Essa abordagem parece ser a abordagem mais simples e direta para o problema, mas foi comprovado repetidamente que não é dimensionado, pois as leituras crescem exponencialmente à medida que a tabela aumenta:
SELECT /* Subconsulta correlacionada */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =(SELECT MAX(TotalDue) FROM Sales.SalesOrderHeader WHERE CustomerID =h.CustomerID AND SalesOrderID <=h.SalesOrderID) FROM Sales.SalesOrderHeader AS h ORDER BY CustomerID, SalesOrderID;
Aqui está o plano contra o AdventureWorks2014, usando o SQL Sentry Plan Explorer:
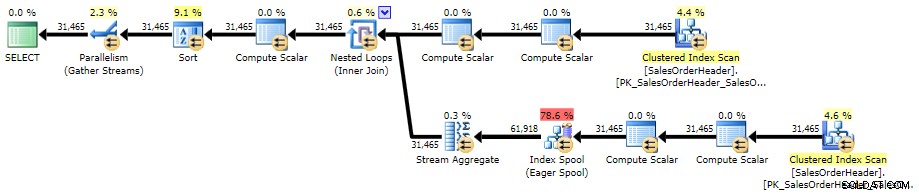 Plano de execução para subconsulta correlacionada (clique para ampliar)
Plano de execução para subconsulta correlacionada (clique para ampliar) Auto-referência CROSS APPLY
Essa abordagem é quase idêntica à abordagem da Subconsulta Correlacionada, em termos de sintaxe, formato do plano e desempenho em escala.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDueFROM Sales.SalesOrderHeader AS hCROSS APPLY( SELECT MaxTotalDue =MAX(TotalDue) FROM Sales.SalesOrderHeader AS i WHERE i.CustomerID =h.CustomerID AND i.SalesOrderID <=h.SalesOrderID) AS xORDER BY h.CustomerID, h.SalesOrderID;
O plano é bastante semelhante ao plano de subconsulta correlacionado, a única diferença é a localização de uma classificação:
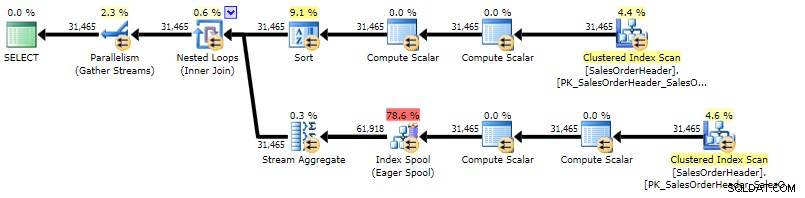 Plano de execução para CROSS APPLY (clique para ampliar)
Plano de execução para CROSS APPLY (clique para ampliar) CTE recursiva
Nos bastidores, isso usa loops, mas até que realmente o executemos, podemos fingir que não (embora seja facilmente o código mais complicado que eu gostaria de escrever para resolver esse problema específico):
;WITH /* CTE Recursive */ cte AS ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue FROM ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =TotalDue, rn =ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID) FROM Sales.SalesOrderHeader ) AS x WHERE rn =1 UNION ALL SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue, MaxTotalDue =CASE WHEN r.TotalDue> cte.MaxTotalDue THEN r.TotalDue ELSE cte .MaxTotalDue END FROM cte CROSS APPLY ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, rn =ROW_NUMBER() OVER (PARTIÇÃO POR CustomerID ORDER POR SalesOrderID) FROM Sales.SalesOrderHeader AS h WHERE h.CustomerID =cte.CustomerID AND h.SalesOrderID> cte.SalesOrderID ) AS r WHERE r.rn =1)SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDueFROM cteORDER BY CustomerID, SalesOrderIDOPTION (MAXRECURSION 0);
Você pode ver imediatamente que o plano é mais complexo que os dois anteriores, o que não é surpreendente, dada a consulta mais complexa:
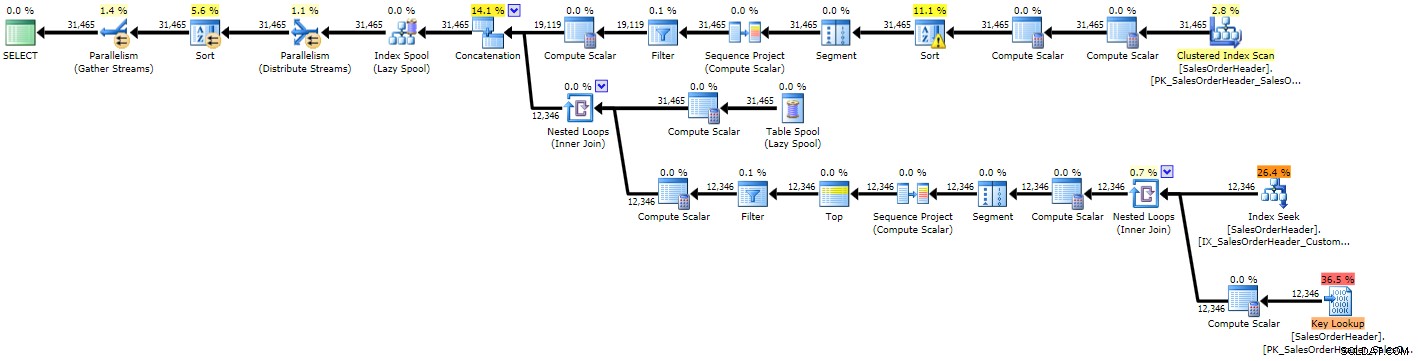 Plano de execução para CTE recursivo (clique para ampliar)
Plano de execução para CTE recursivo (clique para ampliar) Devido a algumas estimativas ruins, vemos uma busca de índice com uma pesquisa de chave que provavelmente deveria ter sido substituída por uma única varredura, e também obtemos uma operação de classificação que precisa ser derramada no tempdb (você pode ver isso na dica de ferramenta se você passar o mouse sobre o operador de classificação com o ícone de aviso):

MAX() ACIMA (FILAS NÃO LIMITADAS)
Esta é uma solução disponível apenas no SQL Server 2012 e superior, pois usa extensões recém-introduzidas para funções de janela.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =MAX(TotalDue) OVER ( PARTITION BY CustomerID ORDER BY SalesOrderID ROWS UNBOUNDED PRECEDING )FROM Sales.SalesOrderHeaderORDER BY CustomerID, SalesOrderID;
O plano mostra exatamente por que ele escala melhor do que todos os outros; ele tem apenas uma operação de varredura de índice clusterizado, em oposição a duas (ou a má escolha de uma varredura e uma busca + pesquisa no caso do CTE recursivo):
Plano de execução para MAX() OVER() (clique para ampliar)
Comparação de desempenho
Os planos certamente nos levam a acreditar que o novoMAX() OVER()capacidade no SQL Server 2012 é um verdadeiro vencedor, mas que tal métricas de tempo de execução tangíveis? Veja como as execuções foram comparadas:

As duas primeiras consultas foram quase idênticas; enquanto neste caso oCROSS APPLYfoi melhor em termos de duração geral por uma pequena margem, a subconsulta correlacionada às vezes a supera um pouco. O CTE recursivo é substancialmente mais lento a cada vez, e você pode ver os fatores que contribuem para isso – ou seja, as estimativas ruins, a grande quantidade de leituras, a pesquisa de chave e a operação de classificação adicional. E como demonstrei antes com totais em execução, a solução SQL Server 2012 é melhor em quase todos os aspectos.
Conclusão
Se você estiver no SQL Server 2012 ou superior, você definitivamente quer se familiarizar com todas as extensões para as funções de janela introduzidas pela primeira vez no SQL Server 2005 – elas podem lhe dar alguns aumentos de desempenho bastante sérios ao revisitar o código que ainda está em execução " do jeito antigo." Se você quiser saber mais sobre alguns desses novos recursos, recomendo o livro de Itzik Ben-Gan, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Se você ainda não está no SQL Server 2012, pelo menos neste teste, você pode escolher entreCROSS APPLYe a subconsulta correlacionada. Como sempre, você deve testar vários métodos em relação aos seus dados em seu hardware.