O SQL Server oferece dois métodos de coleta de dados de diagnóstico e solução de problemas sobre a carga de trabalho executada no servidor:SQL Trace e Extended Events. A partir do SQL Server 2012, a implementação do Extended Events fornece recursos de coleta de dados comparáveis ao SQL Trace e pode ser usada para comparações da sobrecarga incorrida por esses dois recursos. Neste artigo, veremos a comparação da "sobrecarga do observador" que ocorre ao usar o SQL Trace e o Extended Events em várias configurações para determinar o impacto no desempenho que a coleta de dados pode ter em nossa carga de trabalho por meio do uso de uma carga de trabalho de repetição captura e Distributed Replay.
O ambiente de teste
O ambiente de teste é composto por seis máquinas virtuais, um controlador de domínio, um servidor SQL Server 2012 Enterprise Edition e quatro servidores clientes com o serviço de cliente Distributed Replay instalado neles. Diferentes configurações de host foram testadas para este artigo e resultados semelhantes resultaram das três configurações diferentes que foram testadas com base na proporção de impacto. O servidor da edição SQL Server Enterprise está configurado com 4 vCPUs e 4 GB de RAM. Os cinco servidores restantes são configurados com 1 vCPU e 1 GB de RAM. O serviço do controlador Distributed Replay foi executado no servidor SQL Server 2012 Enterprise Edition porque requer uma licença Enterprise para usar mais de um cliente para reprodução.
Carga de trabalho de teste
A carga de trabalho de teste usada para a captura de repetição é a carga de trabalho AdventureWorks Books Online que criei no ano passado para gerar cargas de trabalho simuladas no SQL Server. Essa carga de trabalho usa as consultas de exemplo dos Manuais Online na família de bancos de dados AdventureWorks e é orientada pelo PowerShell. A carga de trabalho foi configurada em cada um dos quatro clientes de repetição e executada com quatro conexões totais com o SQL Server de cada um dos servidores cliente para gerar uma captura de rastreamento de repetição de 1 GB. O rastreamento de repetição foi criado usando o modelo TSQL_Replay do SQL Server Profiler, exportado para um script e configurado como rastreamento do lado do servidor para um arquivo. Depois que o arquivo de rastreamento de reprodução foi capturado, ele foi pré-processado para uso com o Distributed Replay e, em seguida, os dados de reprodução foram usados como a carga de trabalho de reprodução para todos os testes.
Configuração de repetição
A operação de repetição foi configurada para usar a configuração do modo de estresse para direcionar a quantidade máxima de carga em relação à instância de teste do SQL Server. Além disso, a configuração usa uma escala de tempo reduzida de pensar e conectar, que ajusta a proporção de tempo entre o início do rastreamento de reprodução e quando um evento realmente ocorreu até quando ele é reproduzido durante a operação de reprodução, para permitir que os eventos sejam reproduzidos em escala máxima. A escala de estresse para o replay também é configurada por spid. Os detalhes do arquivo de configuração para a operação de repetição foram os seguintes:
<?xml version="1.0" encoding="utf-8"?>
<Options>
<ReplayOptions>
<Server>SQL2K12-SVR1</Server>
<SequencingMode>stress</SequencingMode>
<ConnectTimeScale>1</ConnectTimeScale>
<ThinkTimeScale>1</ThinkTimeScale>
<HealthmonInterval>60</HealthmonInterval>
<QueryTimeout>3600</QueryTimeout>
<ThreadsPerClient>255</ThreadsPerClient>
<EnableConnectionPooling>Yes</EnableConnectionPooling>
<StressScaleGranularity>spid</StressScaleGranularity>
</ReplayOptions>
<OutputOptions>
<ResultTrace>
<RecordRowCount>No</RecordRowCount>
<RecordResultSet>No</RecordResultSet>
</ResultTrace>
</OutputOptions>
</Options> Durante cada uma das operações de repetição, os contadores de desempenho foram coletados em intervalos de cinco segundos para os seguintes contadores:
- Processador\% Tempo do Processador\_Total
- SQL Server\SQL Statistics\Batch Requests/s
Esses contadores serão usados para medir a carga geral do servidor e as características de taxa de transferência de cada um dos testes para comparação.
Configurações de teste
Um total de sete configurações diferentes foram testadas com o Distributed Replay:
- Linha de base
- Rastreamento do lado do servidor
- Perfil no servidor
- Perfil remotamente
- Eventos estendidos para event_file
- Eventos estendidos para ring_buffer
- Eventos estendidos para event_stream
Cada teste foi repetido três vezes para garantir que os resultados fossem consistentes em diferentes testes e para fornecer um conjunto médio de resultados para comparação. Para os testes iniciais de linha de base, nenhuma coleta de dados adicional foi configurada para a instância do SQL Server, mas as coletas de dados padrão que acompanham o SQL Server 2012 foram deixadas habilitadas:o rastreamento padrão e a sessão de evento system_health. Isso reflete a configuração geral da maioria dos SQL Servers, pois geralmente não é recomendado que a sessão padrão trace ou system_health seja desabilitada devido aos benefícios que eles oferecem aos administradores de banco de dados. Esse teste foi usado para determinar a linha de base geral para comparação com os testes em que a coleta de dados adicional estava sendo realizada. Os testes restantes são baseados no modelo TSQL_SPs que acompanha o SQL Server Profiler e coleta os seguintes eventos:
- Auditoria de segurança\Login de auditoria
- Auditoria de segurança\Logout de auditoria
- Sessões\Conexão Existente
- Procedimentos armazenados\RPC:Iniciando
- Procedimentos armazenados\SP:Concluído
- Procedimentos armazenados\SP:Iniciando
- Procedimentos armazenados\SP:StmtStarting
- TSQL\SQL:Início em lote
Este modelo foi selecionado com base na carga de trabalho usada para os testes, que são principalmente lotes SQL capturados pelo
SQL:BatchStarting evento e, em seguida, vários eventos usando os vários métodos de hierarchyid , que são capturados pelo SP:Starting , SP:StmtStarting e SP:Completed eventos. Um script de rastreamento do lado do servidor foi gerado a partir do modelo usando a funcionalidade de exportação no SQL Server Profiler, e as únicas alterações feitas no script foram definir o maxfilesize parâmetro para 500 MB, ative a substituição do arquivo de rastreamento e forneça um nome de arquivo no qual o rastreamento foi gravado. O terceiro e quarto testes usaram o SQL Server Profiler para coletar os mesmos eventos que o rastreamento do lado do servidor para medir a sobrecarga de desempenho do rastreamento usando o aplicativo Profiler. Esses testes foram executados usando o SQL Profiler localmente no SQL Server e remotamente de um cliente separado para verificar se havia uma diferença na sobrecarga ao executar o Profiler local ou remotamente.
Os testes finais usados no Extended Events coletaram os mesmos eventos e as mesmas colunas com base em uma sessão de evento criada usando meu script de conversão Trace to Extended Events para SQL Server 2012. Os testes incluíram a avaliação do event_file, ring_buffer e novo provedor de streaming no SQL Server 2012 separadamente para determinar a sobrecarga que cada destino pode impor ao desempenho do servidor. Além disso, a sessão do evento foi configurada com as opções de buffer de memória padrão, mas foi alterada para especificar
NO_EVENT_LOSS para o EVENT_RETENTION_MODE opção para que os testes event_file e ring_buffer correspondam ao comportamento do rastreamento do lado do servidor a um arquivo, o que também garante nenhuma perda de evento. Resultados
Com uma exceção, os resultados dos testes não foram surpreendentes. O teste de linha de base foi capaz de realizar a carga de trabalho de repetição em treze minutos e trinta e cinco segundos e obteve uma média de 2.345 solicitações de lote por segundo durante os testes. Com o rastreamento do lado do servidor em execução, a operação de reprodução foi concluída em 16 minutos e 40 segundos, o que representa uma degradação de 18,1% no desempenho. O Profiler Traces teve os piores desempenhos em geral e exigiu 149 minutos quando o Profiler foi executado localmente no servidor e 123 minutos e 20 segundos quando o Profiler foi executado remotamente, resultando em 90,8% e 87,6% de degradação no desempenho, respectivamente. Os testes de Eventos Estendidos foram os de melhor desempenho, levando 15 minutos e 15 segundos para o event_file e 15 minutos e 40 segundos para o destino ring_buffer, resultando em uma degradação de 10,4% e 11,6% no desempenho. Os resultados médios de todos os testes são exibidos na Tabela 1 e representados na Figura 2:
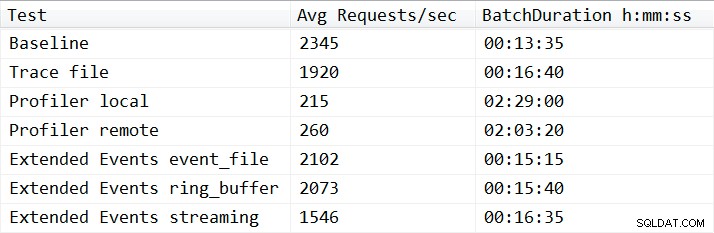
Tabela 1 – Resultados médios de todos os testes
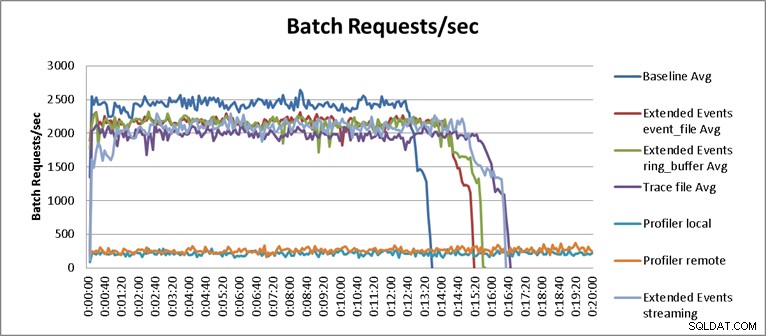
Figura 2 – Gráfico de resultados
O teste de streaming de eventos estendidos não é um resultado justo no contexto dos testes que foram executados e requer um pouco mais de explicação para entender o resultado. A partir dos resultados da tabela, podemos ver que os testes de streaming para Extended Events foram concluídos em dezesseis minutos e trinta e cinco segundos, o que equivale a 34,1% de degradação no desempenho. No entanto, se ampliarmos o gráfico e alterarmos sua escala, como mostra a Figura 3, veremos que o streaming teve um impacto muito maior no desempenho inicialmente e depois passou a funcionar de maneira semelhante aos outros testes de Eventos Estendidos :
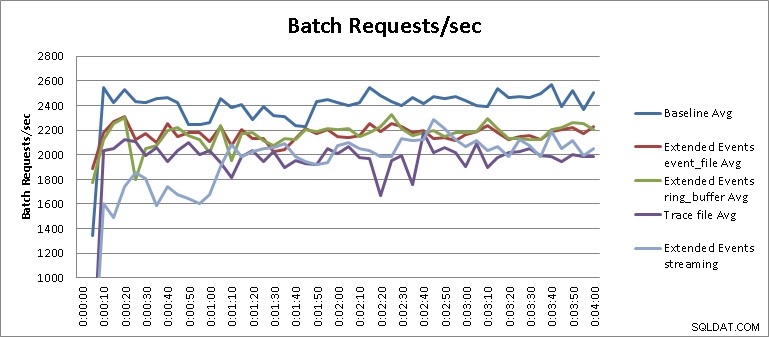
Figura 3 – Resultados ampliados
A explicação para isso é encontrada no design do novo destino de streaming de eventos estendidos no SQL Server 2012. Se os buffers de memória interna do event_stream ficarem cheios e não forem consumidos pelo aplicativo cliente com rapidez suficiente, o Mecanismo de Banco de Dados forçará uma desconexão de o event_stream para evitar um impacto grave no desempenho do servidor. Isso resulta em um erro sendo gerado no SQL Server 2012 Management Studio semelhante ao erro na Figura 4:
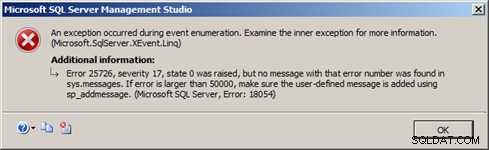
Figura 4 – event_stream desconectado pelo servidor
Ocorreu uma exceção durante a enumeração do evento. Examine a exceção interna para obter mais informações.
(Microsoft.SqlServer.XEvent.Linq)
Erro 25726, gravidade 17, estado 0 foi gerado, mas nenhuma mensagem com esse número de erro foi encontrada em sys.messages. Se o erro for maior que 50.000, verifique se a mensagem definida pelo usuário foi adicionada usando sp_addmessage.
(Microsoft SQL Server, Erro:18054)
Conclusões
Todos os métodos de coleta de dados de diagnóstico do SQL Server têm "sobrecarga do observador" associada a eles e podem afetar o desempenho de uma carga de trabalho sob carga pesada. Para sistemas executados no SQL Server 2012, os eventos estendidos fornecem a menor quantidade de sobrecarga e fornecem recursos semelhantes para eventos e colunas como o SQL Trace (alguns eventos no SQL Trace são acumulados em outros eventos em Extended Events). Caso o SQL Trace seja necessário para capturar dados de eventos – o que pode ser o caso até que ferramentas de terceiros sejam recodificados para aproveitar os dados de eventos estendidos – um rastreamento do lado do servidor para um arquivo produzirá a menor quantidade de sobrecarga de desempenho. O SQL Server Profiler é uma ferramenta a ser evitada em servidores de produção ocupados, conforme mostrado pelo aumento de dez vezes na duração e redução significativa na taxa de transferência para a reprodução.
Embora os resultados pareçam favorecer a execução remota do SQL Server Profiler quando o Profiler deve ser usado, essa conclusão não pode ser definitivamente tirada com base nos testes específicos que foram executados neste cenário. Testes adicionais e coleta de dados teriam que ser executados para determinar se os resultados do Profiler remoto eram o resultado da alternância de contexto inferior na instância do SQL Server ou se a rede entre VMs desempenhava um fator no menor impacto no desempenho da coleta remota. O objetivo nesses testes era mostrar a sobrecarga significativa que o Profiler incorre, independentemente de onde o Profiler estava sendo executado. Por fim, o fluxo de eventos ao vivo em Eventos Estendidos também tem uma alta sobrecarga quando está realmente conectado na coleta de dados, mas, conforme mostrado nos testes, o Mecanismo de Banco de Dados desconectará um fluxo ao vivo se ficar para trás nos eventos para evitar um impacto grave no desempenho do servidor.