O desempenho é extremamente importante em muitos produtos de consumo, como comércio eletrônico, sistemas de pagamento, jogos, aplicativos de transporte e assim por diante. Embora os bancos de dados sejam otimizados internamente por meio de vários mecanismos para atender aos seus requisitos de desempenho no mundo moderno, muito também depende do desenvolvedor do aplicativo — afinal, apenas um desenvolvedor sabe quais consultas o aplicativo deve realizar.
Os desenvolvedores que lidam com bancos de dados relacionais usaram ou pelo menos ouviram falar sobre indexação, e é um conceito muito comum no mundo dos bancos de dados. No entanto, a parte mais importante é entender o que indexar e como a indexação aumentará o tempo de resposta da consulta. Para fazer isso, você precisa entender como consultará suas tabelas de banco de dados. Um índice adequado pode ser criado somente quando você sabe exatamente como são seus padrões de consulta e acesso a dados.
Em terminologia simples, um índice mapeia as chaves de pesquisa para os dados correspondentes no disco usando diferentes estruturas de dados na memória e no disco. O índice é usado para acelerar a pesquisa reduzindo o número de registros a serem pesquisados.
Principalmente um índice é criado nas colunas especificadas no
WHERE cláusula de uma consulta à medida que o banco de dados recupera e filtra dados das tabelas com base nessas colunas. Se você não criar um índice, o banco de dados verifica todas as linhas, filtra as linhas correspondentes e retorna o resultado. Com milhões de registros, essa operação de verificação pode levar muitos segundos e esse alto tempo de resposta torna as APIs e os aplicativos mais lentos e inutilizáveis. Vejamos um exemplo — Usaremos o MySQL com um mecanismo de banco de dados InnoDB padrão, embora os conceitos explicados neste artigo sejam mais ou menos os mesmos em outros servidores de banco de dados, como Oracle, MSSQL etc.
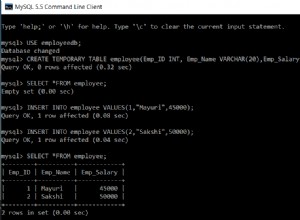
Crie uma tabela chamada
index_demo com o seguinte esquema:CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Como verificamos se estamos usando o mecanismo InnoDB?
Execute o comando abaixo:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;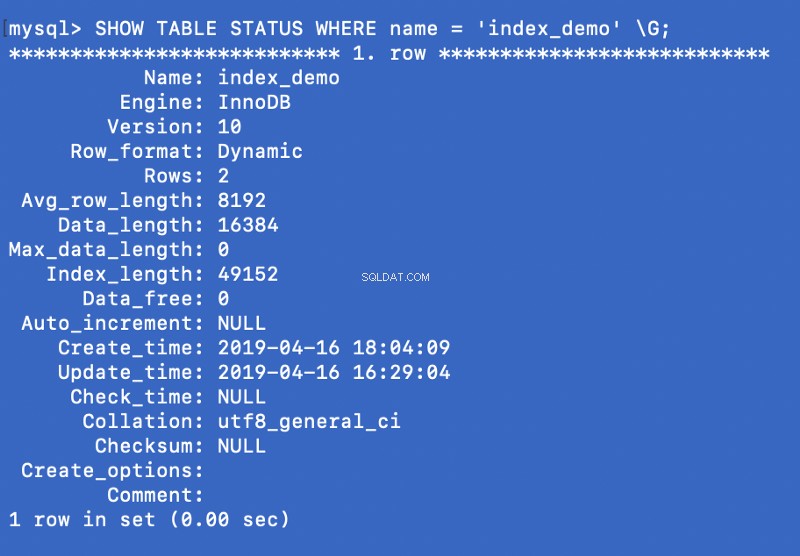
O
Engine A coluna na captura de tela acima representa o mecanismo usado para criar a tabela. Aqui InnoDB é usado. Agora insira alguns dados aleatórios na tabela, minha tabela com 5 linhas se parece com o seguinte:
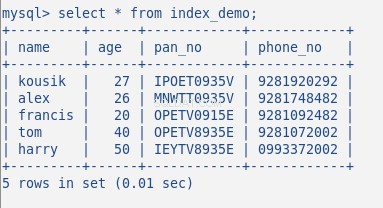
Eu não criei nenhum índice até agora nesta tabela. Vamos verificar isso pelo comando:
SHOW INDEX . Retorna 0 resultados. 
Neste momento, se executarmos um simples
SELECT consulta, como não há índice definido pelo usuário, a consulta varrerá toda a tabela para descobrir o resultado:EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN mostra como o mecanismo de consulta planeja executar a consulta. Na captura de tela acima, você pode ver que as rows coluna retorna 5 &possible_keys retorna null . possible_keys representa quais são todos os índices disponíveis que podem ser usados nesta consulta. A key coluna representa qual índice será realmente usado de todos os índices possíveis nesta consulta. Chave primária:
A consulta acima é muito ineficiente. Vamos otimizar esta consulta. Faremos o
phone_no coluna a PRIMARY KEY assumindo que não podem existir dois usuários em nosso sistema com o mesmo número de telefone. Leve o seguinte em consideração ao criar uma chave primária:- Uma chave primária deve fazer parte de muitas consultas vitais em seu aplicativo.
- Chave primária é uma restrição que identifica exclusivamente cada linha em uma tabela. Se várias colunas fizerem parte da chave primária, essa combinação deverá ser exclusiva para cada linha.
- A chave primária deve ser não nula. Nunca torne os campos nulos sua chave primária. Pelos padrões ANSI SQL, as chaves primárias devem ser comparáveis entre si, e você definitivamente deve ser capaz de dizer se o valor da coluna da chave primária para uma determinada linha é maior, menor ou igual ao mesmo da outra linha. Desde
NULLsignifica um valor indefinido nos padrões SQL, você não pode comparar deterministicamenteNULLcom qualquer outro valor, então logicamenteNULLnão é permitido. - O tipo de chave primária ideal deve ser um número como
INTouBIGINTporque as comparações de inteiros são mais rápidas, portanto, percorrer o índice será muito rápido.
Muitas vezes definimos um
id campo como AUTO INCREMENT em tabelas e use isso como chave primária, mas a escolha de uma chave primária depende dos desenvolvedores. E se você não criar nenhuma chave primária?
Não é obrigatório criar uma chave primária você mesmo. Se você não definiu nenhuma chave primária, o InnoDB cria uma implicitamente para você porque o InnoDB por design deve ter uma chave primária em cada tabela. Assim, uma vez que você cria uma chave primária posteriormente para essa tabela, o InnoDB exclui a chave primária previamente definida automaticamente.
Como não temos nenhuma chave primária definida até agora, vamos ver o que o InnoDB por padrão criou para nós:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED mostra todos os índices que não são utilizáveis pelo usuário, mas gerenciados completamente pelo MySQL. Aqui vemos que o MySQL definiu um índice composto (discutiremos índices compostos mais tarde) em
DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR , &todas as colunas definidas na tabela. Na ausência de uma chave primária definida pelo usuário, esse índice é usado para localizar registros exclusivamente. Qual é a diferença entre chave e índice?
Embora os termos
key &index são usados alternadamente, key significa uma restrição imposta ao comportamento da coluna. Nesse caso, a restrição é que a chave primária é um campo não nulo que identifica exclusivamente cada linha. Por outro lado, index é uma estrutura de dados especial que facilita a pesquisa de dados na tabela. Vamos agora criar o índice primário em
phone_no &examine o índice criado:ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;Observe que
CREATE INDEX não pode ser usado para criar um índice primário, mas ALTER TABLE é usado. 
Na captura de tela acima, vemos que um índice primário é criado na coluna
phone_no . As colunas das imagens a seguir são descritas da seguinte forma:Table :a tabela na qual o índice é criado. Non_unique :Se o valor for 1, o índice não é único, se o valor for 0, o índice é único. Key_name :O nome do índice criado. O nome do índice primário é sempre PRIMARY no MySQL, independentemente de você ter fornecido algum nome de índice ou não ao criar o índice. Seq_in_index :o número de sequência da coluna no índice. Se várias colunas fizerem parte do índice, o número de sequência será atribuído com base em como as colunas foram ordenadas durante o tempo de criação do índice. O número de sequência começa em 1. Collation :como a coluna é classificada no índice. A significa ascendente, D significa decrescente, NULL significa não ordenado. Cardinality :o número estimado de valores exclusivos no índice. Mais cardinalidade significa maiores chances de que o otimizador de consulta escolha o índice para consultas. Sub_part :O prefixo do índice. É NULL se a coluna inteira estiver indexada. Caso contrário, mostra o número de bytes indexados caso a coluna esteja parcialmente indexada. Vamos definir o índice parcial mais tarde. Packed :Indica como a chave é empacotada; NULL Se não é. Null :YES se a coluna pode conter NULL valores e em branco se não tiver. Index_type :Indica qual estrutura de dados de indexação é usada para este índice. Alguns possíveis candidatos são — BTREE , HASH , RTREE , ou FULLTEXT . Comment :as informações sobre o índice não descritas em sua própria coluna. Index_comment :O comentário para o índice especificado quando você criou o índice com o COMMENT atributo. Agora vamos ver se esse índice reduz o número de linhas que serão pesquisadas por um determinado
phone_no no WHERE cláusula de uma consulta. EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
Neste instantâneo, observe que as
rows coluna retornou 1 apenas, as possible_keys &key ambos retornam PRIMARY . Portanto, significa essencialmente que usar o índice primário chamado PRIMARY (o nome é atribuído automaticamente quando você cria a chave primária), o otimizador de consulta apenas vai diretamente ao registro e o busca. É muito eficiente. É exatamente para isso que serve um índice — minimizar o escopo de pesquisa ao custo de espaço extra. Índice agrupado:
Um
clustered index é colocado com os dados no mesmo espaço de tabela ou mesmo arquivo de disco. Você pode considerar que um índice clusterizado é uma B-Tree index cujos nós folha são os blocos de dados reais no disco, já que o índice e os dados residem juntos. Esse tipo de índice organiza fisicamente os dados no disco de acordo com a ordem lógica da chave de índice. O que significa organização de dados físicos?
Fisicamente, os dados são organizados em disco em milhares ou milhões de blocos de disco/dados. Para um índice clusterizado, não é obrigatório que todos os blocos de disco sejam armazenados de forma contagiosa. Os blocos de dados físicos são movidos o tempo todo aqui e ali pelo sistema operacional sempre que necessário. Um sistema de banco de dados não tem controle absoluto sobre como o espaço físico de dados é gerenciado, mas dentro de um bloco de dados, os registros podem ser armazenados ou gerenciados na ordem lógica da chave de índice. O diagrama simplificado a seguir explica isso:
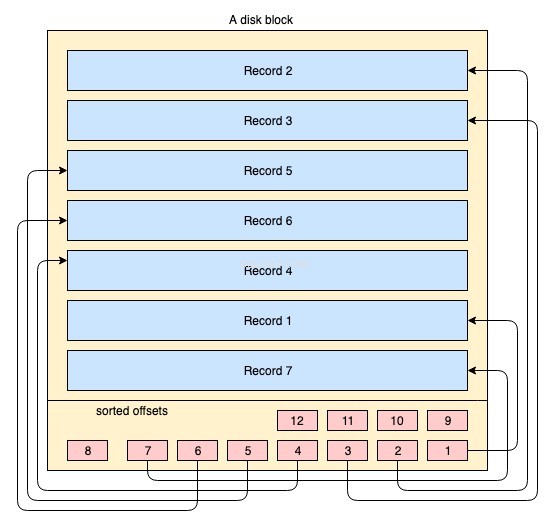
- O grande retângulo de cor amarela representa um bloco de disco/bloco de dados
- os retângulos de cor azul representam os dados armazenados como linhas dentro desse bloco
- a área do rodapé representa o índice do bloco onde residem pequenos retângulos de cor vermelha em ordem de classificação de uma chave específica. Esses pequenos blocos nada mais são do que ponteiros apontando para deslocamentos dos registros.
Os registros são armazenados no bloco de disco em qualquer ordem arbitrária. Sempre que novos registros são adicionados, eles são adicionados no próximo espaço disponível. Sempre que um registro existente é atualizado, o sistema operacional decide se esse registro ainda pode caber na mesma posição ou se uma nova posição deve ser alocada para esse registro.
Portanto, a posição dos registros é completamente tratada pelo sistema operacional e não existe nenhuma relação definida entre a ordem de dois registros. Para buscar os registros na ordem lógica da chave, as páginas do disco contêm uma seção de índice no rodapé, o índice contém uma lista de ponteiros de deslocamento na ordem da chave. Cada vez que um registro é alterado ou criado, o índice é ajustado.
Dessa forma, você realmente não precisa se preocupar em organizar o registro físico em uma determinada ordem, em vez disso, uma pequena seção de índice é mantida nessa ordem e a busca ou manutenção de registros se torna muito fácil.
Vantagem do índice clusterizado:
Essa ordenação ou colocação de dados relacionados realmente torna um índice clusterizado mais rápido. Quando os dados são obtidos do disco, o bloco completo contendo os dados é lido pelo sistema, pois nosso sistema de E/S de disco grava e lê os dados em blocos. Portanto, no caso de consultas de intervalo, é bem possível que os dados colocados sejam armazenados em buffer na memória. Digamos que você dispare a seguinte consulta:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'Um bloco de dados é buscado na memória quando a consulta é executada. Digamos que o bloco de dados contenha
phone_no no intervalo de 9010000000 para 9030000000 . Portanto, qualquer intervalo que você solicitou na consulta é apenas um subconjunto dos dados presentes no bloco. Se você agora disparar a próxima consulta para obter todos os números de telefone no intervalo, digamos de 9015000000 para 9019000000 , você não precisa buscar mais blocos do disco. Os dados completos podem ser encontrados no bloco de dados atual, portanto, clustered_index reduz o número de E/S de disco colocando os dados relacionados o máximo possível no mesmo bloco de dados. Essa E/S de disco reduzida causa melhoria no desempenho. Portanto, se você tiver uma chave primária bem pensada e suas consultas forem baseadas na chave primária, o desempenho será super rápido.
Restrições do índice clusterizado:
Como um índice clusterizado afeta a organização física dos dados, pode haver apenas um índice clusterizado por tabela.
Relação entre a chave primária e o índice clusterizado:
Você não pode criar um índice clusterizado manualmente usando o InnoDB no MySQL. MySQL escolhe para você. Mas como ele escolhe? Os seguintes trechos são da documentação do MySQL:
Quando você define umaPRIMARY KEYna sua tabela,InnoDBusa-o como o índice clusterizado. Defina uma chave primária para cada tabela que você cria. Se não houver uma coluna lógica única e não nula ou um conjunto de colunas, adicione uma nova coluna de incremento automático, cujos valores são preenchidos automaticamente.
Se você não definir umaPRIMARY KEYpara sua tabela, o MySQL localiza o primeiroUNIQUEíndice onde todas as colunas de chave sãoNOT NULLeInnoDBusa-o como o índice clusterizado.
Se a tabela não tiverPRIMARY KEYouUNIQUEadequado índice,InnoDBgera internamente um índice clusterizado oculto chamadoGEN_CLUST_INDEXem uma coluna sintética contendo valores de ID de linha. As linhas são ordenadas pelo ID queInnoDBatribui às linhas em tal tabela. O ID da linha é um campo de 6 bytes que aumenta monotonicamente à medida que novas linhas são inseridas. Assim, as linhas ordenadas pelo ID da linha estão fisicamente na ordem de inserção.
Em resumo, o mecanismo MySQL InnoDB realmente gerencia o índice primário como índice clusterizado para melhorar o desempenho, de modo que a chave primária e o registro real no disco sejam agrupados em cluster.
Estrutura da chave primária (agrupada) Índice:
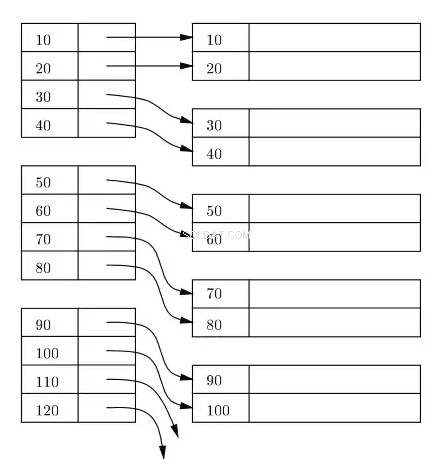
Um índice geralmente é mantido como uma árvore B+ no disco e na memória, e qualquer índice é armazenado em blocos no disco. Esses blocos são chamados de blocos de índice. As entradas no bloco de índice são sempre classificadas na chave de índice/pesquisa. O bloco de índice folha do índice contém um localizador de linha. Para o índice primário, o localizador de linha refere-se ao endereço virtual da localização física correspondente dos blocos de dados no disco onde as linhas residem sendo classificadas de acordo com a chave de índice.
No diagrama a seguir, os retângulos do lado esquerdo representam os blocos de índice de nível de folha e os retângulos do lado direito representam os blocos de dados. Logicamente, os blocos de dados parecem estar alinhados em uma ordem classificada, mas, como já descrito anteriormente, os locais físicos reais podem estar espalhados aqui e ali.
É possível criar um índice primário em uma chave não primária?
No MySQL, um índice primário é criado automaticamente, e já descrevemos acima como o MySQL escolhe o índice primário. Mas no mundo do banco de dados, na verdade, não é necessário criar um índice na coluna de chave primária – o índice primário também pode ser criado em qualquer coluna que não seja de chave primária. Mas quando criado na chave primária, todas as entradas de chave são únicas no índice, enquanto no outro caso, o índice primário também pode ter uma chave duplicada.
É possível excluir uma chave primária?
É possível excluir uma chave primária. Quando você exclui uma chave primária, o índice clusterizado relacionado, bem como a propriedade de exclusividade dessa coluna, são perdidos.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Vantagens do Índice Primário:
- As consultas de intervalo baseadas em índice primário são muito eficientes. Pode haver a possibilidade de que o bloco de disco que o banco de dados leu do disco contenha todos os dados pertencentes à consulta, já que o índice primário é agrupado e os registros são ordenados fisicamente. Assim, a localidade dos dados pode ser fornecida pelo índice primário.
- Qualquer consulta que aproveite a chave primária é muito rápida.
Desvantagens do Índice Primário:
- Como o índice primário contém uma referência direta ao endereço do bloco de dados através do espaço de endereço virtual e os blocos de disco são fisicamente organizados na ordem da chave de índice, toda vez que o SO faz alguma divisão de página de disco devido a
DMLoperações comoINSERT/UPDATE/DELETE, o índice primário também precisa ser atualizado. EntãoDMLoperações pressiona o desempenho do índice primário.
Índice secundário:
Qualquer índice que não seja um índice clusterizado é chamado de índice secundário. Os índices secundários não afetam os locais de armazenamento físico, ao contrário dos índices primários.
Quando você precisa de um índice secundário?
Você pode ter vários casos de uso em seu aplicativo em que não consulta o banco de dados com uma chave primária. Em nosso exemplo
phone_no é a chave primária, mas podemos precisar consultar o banco de dados com pan_no , ou name . Nesses casos, você precisa de índices secundários nessas colunas se a frequência dessas consultas for muito alta. Como criar um índice secundário no MySQL?
O comando a seguir cria um índice secundário no
name coluna no index_demo tabela. CREATE INDEX secondary_idx_1 ON index_demo (name);
Estrutura do índice secundário:
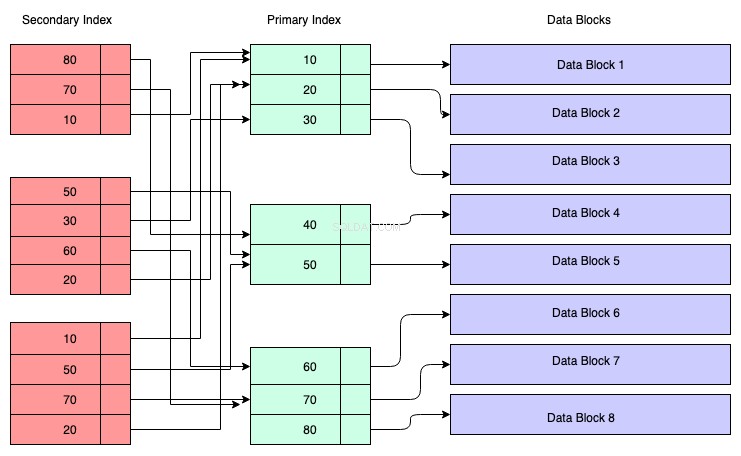
No diagrama abaixo, os retângulos de cor vermelha representam blocos de índice secundários. O índice secundário também é mantido na Árvore B+ e é classificado de acordo com a chave na qual o índice foi criado. Os nós folha contêm uma cópia da chave dos dados correspondentes no índice primário.
Então, para entender, você pode assumir que o índice secundário tem referência ao endereço da chave primária, embora não seja o caso. Recuperar dados por meio do índice secundário significa que você precisa percorrer duas árvores B+ — uma é a própria árvore B+ do índice secundário e a outra é a árvore B+ do índice primário.
Vantagens de um índice secundário:
Logicamente, você pode criar quantos índices secundários desejar. Mas, na realidade, quantos índices realmente necessários precisam de um processo de pensamento sério, pois cada índice tem sua própria penalidade.
Desvantagens de um índice secundário:
Com
DML operações como DELETE / INSERT , o índice secundário também precisa ser atualizado para que a cópia da coluna da chave primária possa ser excluída/inserida. Nesses casos, a existência de muitos índices secundários pode criar problemas. Além disso, se uma chave primária for muito grande como um
URL , como os índices secundários contêm uma cópia do valor da coluna da chave primária, ele pode ser ineficiente em termos de armazenamento. Mais chaves secundárias significa um número maior de cópias duplicadas do valor da coluna da chave primária, portanto, mais armazenamento no caso de uma chave primária grande. Além disso, a própria chave primária armazena as chaves, portanto, o efeito combinado no armazenamento será muito alto. Consideração antes de excluir um índice primário:
No MySQL, você pode excluir um índice primário descartando a chave primária. Já vimos que um índice secundário depende de um índice primário. Portanto, se você excluir um índice primário, todos os índices secundários devem ser atualizados para conter uma cópia da nova chave de índice primário que o MySQL ajusta automaticamente.
Este processo é caro quando existem vários índices secundários. Além disso, outras tabelas podem ter uma referência de chave estrangeira para a chave primária, portanto, você precisa excluir essas referências de chave estrangeira antes de excluir a chave primária.
Quando uma chave primária é excluída, o MySQL cria automaticamente outra chave primária internamente, e essa é uma operação cara.
Índice de chave ÚNICO:
Assim como as chaves primárias, as chaves exclusivas também podem identificar registros exclusivamente com uma diferença:a coluna de chave exclusiva pode conter
null valores. Ao contrário de outros servidores de banco de dados, no MySQL uma coluna de chave exclusiva pode ter tantos
null valores possível. No padrão SQL, null significa um valor indefinido. Portanto, se o MySQL tiver que conter apenas um null valor em uma coluna de chave exclusiva, ele deve assumir que todos os valores nulos são os mesmos. Mas logicamente isso não está correto, pois
null significa indefinido — e valores indefinidos não podem ser comparados entre si, é a natureza de null . Como o MySQL não pode afirmar se todos os null s significa o mesmo, ele permite vários null valores na coluna. O comando a seguir mostra como criar um índice de chave exclusivo no MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Índice composto:
O MySQL permite definir índices em várias colunas, até 16 colunas. Esse índice é chamado de índice Multi-coluna/Composto/Composto.
Digamos que temos um índice definido em 4 colunas —
col1 , col2 , col3 , col4 . Com um índice composto, temos capacidade de pesquisa em col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Portanto, podemos usar qualquer prefixo do lado esquerdo das colunas indexadas, mas não podemos omitir uma coluna do meio e usar isso como — (col1, col3) ou (col1, col2, col4) ou col3 ou col4 etc. Estas são combinações inválidas. Os comandos a seguir criam 2 índices compostos em nossa tabela:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);Se você tiver consultas contendo um
WHERE cláusula em várias colunas, escreva a cláusula na ordem das colunas do índice composto. O índice beneficiará essa consulta. Na verdade, ao decidir as colunas para um índice composto, você pode analisar diferentes casos de uso do seu sistema e tentar encontrar a ordem das colunas que beneficiará a maioria dos seus casos de uso. Índices compostos podem ajudá-lo em
JOIN &SELECT consultas também. Exemplo:no seguinte SELECT * consulta, composite_index_2 é usado. 
Quando vários índices são definidos, o otimizador de consultas MySQL escolhe aquele índice que elimina o maior número de linhas ou varre o menor número de linhas possível para melhor eficiência.
Por que usamos índices compostos ? Por que não definir vários índices secundários nas colunas que nos interessam?
O MySQL usa apenas um índice por tabela por consulta, exceto UNION. (Em um UNION, cada consulta lógica é executada separadamente e os resultados são mesclados.) Portanto, definir vários índices em várias colunas não garante que esses índices sejam usados mesmo que façam parte da consulta.
O MySQL mantém algo chamado estatísticas de índice que ajudam o MySQL a inferir como os dados se parecem no sistema. As estatísticas de índice são uma generalização, mas com base nesses metadados, o MySQL decide qual índice é apropriado para a consulta atual.
Como funciona o índice composto?
As colunas usadas em índices compostos são concatenadas juntas e essas chaves concatenadas são armazenadas em ordem de classificação usando uma Árvore B+. Quando você executa uma pesquisa, a concatenação de suas chaves de pesquisa é comparada com as do índice composto. Então, se houver alguma incompatibilidade entre a ordenação de suas chaves de pesquisa e a ordenação das colunas de índice composto, o índice não poderá ser usado.
Em nosso exemplo, para o registro a seguir, uma chave de índice composto é formada pela concatenação de
pan_no , name , age — HJKXS9086Wkousik28 . +--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Como identificar se você precisa de um índice composto:
- Analise suas consultas primeiro de acordo com seus casos de uso. Se você perceber que determinados campos estão aparecendo juntos em muitas consultas, considere criar um índice composto.
- Se você estiver criando um índice em
col1&um índice composto em (col1,col2), então apenas o índice composto deve funcionar bem.col1sozinho pode ser servido pelo próprio índice composto, pois é um prefixo do lado esquerdo do índice. - Considere a cardinalidade. Se as colunas usadas no índice composto tiverem alta cardinalidade juntas, elas são boas candidatas para o índice composto.
Índice de cobertura:
Um índice de cobertura é um tipo especial de índice composto em que todas as colunas especificadas na consulta existem em algum lugar no índice. Portanto, o otimizador de consulta não precisa acessar o banco de dados para obter os dados — em vez disso, ele obtém o resultado do próprio índice. Exemplo:já definimos um índice composto em
(pan_no, name, age) , então agora considere a seguinte consulta:SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'As colunas mencionadas no
SELECT &WHERE cláusulas fazem parte do índice composto. Portanto, neste caso, podemos obter o valor da age coluna do próprio índice composto. Vamos ver o que o EXPLAIN comando mostra para esta consulta:EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';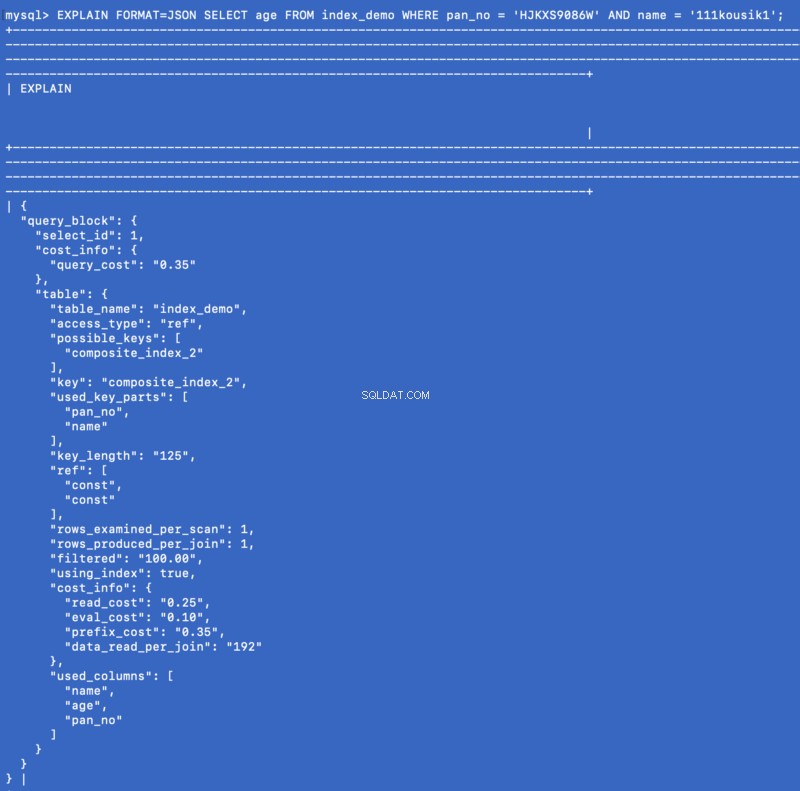
Na resposta acima, observe que há uma chave —
using_index que está definido como true o que significa que o índice de cobertura foi usado para responder à consulta. Não sei o quanto os índices de cobertura são apreciados em ambientes de produção, mas aparentemente parece ser uma boa otimização caso a consulta seja adequada.
Índice parcial:
Já sabemos que os Índices aceleram nossas consultas ao custo de espaço. Quanto mais índices você tiver, maior será o requisito de armazenamento. Já criamos um índice chamado
secondary_idx_1 na coluna name . A coluna name pode conter grandes valores de qualquer comprimento. Também no índice, os metadados dos localizadores de linha ou dos ponteiros de linha têm seu próprio tamanho. Portanto, no geral, um índice pode ter uma alta carga de armazenamento e memória. No MySQL, também é possível criar um índice nos primeiros bytes de dados. Exemplo:o comando a seguir cria um índice nos primeiros 4 bytes do nome. Embora esse método reduza a sobrecarga de memória em uma certa quantidade, o índice não pode eliminar muitas linhas, pois neste exemplo os primeiros 4 bytes podem ser comuns em muitos nomes. Normalmente este tipo de indexação de prefixo é suportado em
CHAR ,VARCHAR , BINARY , VARBINARY tipo de colunas. CREATE INDEX secondary_index_1 ON index_demo (name(4));O que acontece nos bastidores quando definimos um índice?
Vamos executar o
SHOW EXTENDED comando novamente:SHOW EXTENDED INDEXES FROM index_demo;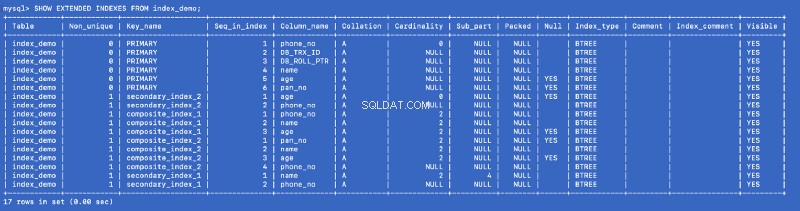
Definimos
secondary_index_1 em name , mas o MySQL criou um índice composto em (name , phone_no ) onde phone_no é a coluna de chave primária. Criamos secondary_index_2 em age &MySQL criou um índice composto em (age , phone_no ). Criamos composite_index_2 em (pan_no , name , age ) &MySQL criou um índice composto em (pan_no , name , age , phone_no ). O índice composto composite_index_1 já tem phone_no como parte dela. Portanto, qualquer que seja o índice que criamos, o MySQL em segundo plano cria um índice composto de apoio que, por sua vez, aponta para a chave primária. Isso significa que a chave primária é um cidadão de primeira classe no mundo da indexação MySQL. Também prova que todos os índices são apoiados por uma cópia do índice primário — mas não tenho certeza se uma única cópia do índice primário é compartilhada ou se são usadas cópias diferentes para índices diferentes.
Existem muitos outros índices, como o índice espacial e o índice de pesquisa de texto completo oferecidos pelo MySQL. Eu ainda não experimentei esses índices, então não vou discuti-los neste post.
Diretrizes gerais de indexação:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html