Uma parte importante do ajuste de consulta é entender os algoritmos que estão disponíveis para o otimizador para lidar com várias construções de consulta, por exemplo, filtragem, junção, agrupamento e agregação, e como eles são dimensionados. Esse conhecimento ajuda você a preparar um ambiente físico ideal para suas consultas, como criar os índices certos. Também ajuda você a perceber intuitivamente qual algoritmo você deve esperar ver no plano em um determinado conjunto de circunstâncias, com base em sua familiaridade com os limites em que o otimizador deve alternar de um algoritmo para outro. Então, ao ajustar consultas com desempenho ruim, você pode identificar mais facilmente áreas no plano de consulta em que o otimizador pode ter feito escolhas abaixo do ideal, por exemplo, devido a estimativas de cardinalidade imprecisas, e tomar medidas para corrigi-las.
Outra parte importante do ajuste de consulta é pensar fora da caixa — além dos algoritmos que estão disponíveis para o otimizador ao usar as ferramentas óbvias. Seja criativo. Digamos que você tenha uma consulta com desempenho ruim, embora tenha organizado o ambiente físico ideal. Para as construções de consulta que você usou, os algoritmos disponíveis para o otimizador são x, yez, e o otimizador escolheu o melhor que pôde nas circunstâncias. Ainda assim, a consulta funciona mal. Você pode imaginar um plano teórico com um algoritmo que pode gerar uma consulta com muito melhor desempenho? Se você puder imaginar, é provável que você consiga conseguir com alguma reescrita de consulta, talvez com construções de consulta menos óbvias para a tarefa.
Nesta série de artigos, concentro-me em agrupar e agregar dados. Começarei examinando os algoritmos que estão disponíveis para o otimizador ao usar consultas agrupadas. Em seguida, descreverei cenários em que nenhum dos algoritmos existentes funciona bem e mostrarei reescritas de consulta que resultam em excelente desempenho e dimensionamento.
Gostaria de agradecer a Craig Freedman, Vassilis Papadimos e Joe Sack, membros da interseção do conjunto das pessoas mais inteligentes do planeta e do conjunto de desenvolvedores do SQL Server, por responderem às minhas perguntas sobre otimização de consultas!
Para dados de amostra, usarei um banco de dados chamado PerformanceV3. Você pode baixar um script para criar e preencher o banco de dados aqui. Usarei uma tabela chamada dbo.Orders, que é preenchida com 1.000.000 de linhas. Esta tabela tem alguns índices que não são necessários e podem interferir nos meus exemplos, portanto, execute o seguinte código para eliminar esses índices desnecessários:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Os únicos dois índices restantes nesta tabela são um índice clusterizado chamado idx_cl_od na coluna orderdate e um índice exclusivo não clusterizado chamado PK_Orders na coluna orderid, aplicando a restrição de chave primária.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Algoritmos existentes
O SQL Server oferece suporte a dois algoritmos principais para agregar dados:Stream Aggregate e Hash Aggregate. Com consultas agrupadas, o algoritmo Stream Aggregate exige que os dados sejam ordenados pelas colunas agrupadas, portanto, você precisa distinguir entre dois casos. Um é um Stream Aggregate pré-ordenado, por exemplo, quando os dados são obtidos pré-ordenados de um índice. Outro é um Stream Aggregate não pré-ordenado, em que uma etapa extra é necessária para classificar explicitamente a entrada. Esses dois casos são dimensionados de maneira muito diferente, então você pode considerá-los como dois algoritmos diferentes.
O algoritmo Hash Aggregate organiza os grupos e seus agregados em uma tabela de hash. Não requer que a entrada seja solicitada.
Com dados suficientes, o otimizador considera paralelizar o trabalho, aplicando o que é conhecido como agregado local-global. Nesse caso, a entrada é dividida em vários threads e cada thread aplica um dos algoritmos mencionados acima para agregar localmente seu subconjunto de linhas. Um agregado global então usa um dos algoritmos mencionados acima para agregar os resultados dos agregados locais.
Neste artigo, concentro-me no algoritmo Stream Aggregate pré-ordenado e seu dimensionamento. Em partes futuras desta série, abordarei outros algoritmos e descreverei os limites em que o otimizador alterna de um para outro e quando você deve considerar reescrever as consultas.
Agregado de stream encomendado
Dada uma consulta agrupada com um conjunto de agrupamento não vazio (o conjunto de expressões pelo qual você agrupa), o algoritmo Stream Aggregate exige que as linhas de entrada sejam ordenadas pelas expressões que formam o conjunto de agrupamento. Quando o algoritmo processa a primeira linha em um grupo, ele inicializa um membro que contém o valor agregado intermediário com o valor relevante (por exemplo, o valor da primeira linha para um agregado MAX). Ao processar uma não primeira linha do grupo, ele atribui a esse membro o resultado de um cálculo envolvendo o valor agregado intermediário e o valor da nova linha (por exemplo, o máximo entre o valor agregado intermediário e o novo valor). Assim que qualquer um dos membros do conjunto de agrupamento altera seu valor, ou a entrada é consumida, o valor agregado atual é considerado o resultado final do último grupo.
Uma maneira de ter os dados ordenados como o algoritmo Stream Aggregate precisa é obtê-los pré-ordenados de um índice. Você precisa que o índice seja definido com as colunas do conjunto de agrupamento como chaves - em qualquer ordem entre elas. Você também quer que o índice esteja cobrindo. Por exemplo, considere a seguinte consulta (vamos chamá-la de Consulta 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Um índice de armazenamento de linhas ideal para oferecer suporte a essa consulta seria aquele definido com shipperid como a coluna de chave principal e orderdate como uma coluna incluída ou como uma segunda coluna de chave:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
Com esse índice em vigor, você obtém o plano estimado mostrado na Figura 1 (usando o SentryOne Plan Explorer).

Figura 1:plano para a consulta 1
Observe que o operador Index Scan tem uma propriedade Ordered:True significando que é necessário entregar as linhas ordenadas pela chave de índice. O operador Stream Aggregate então ingere as linhas ordenadas conforme necessário. Quanto à forma de cálculo do custo do operador; antes de chegarmos a isso, um rápido prefácio primeiro…
Como você já deve saber, quando o SQL Server otimiza uma consulta, ele avalia vários planos candidatos e, eventualmente, escolhe aquele com o menor custo estimado. O custo estimado do plano é a soma de todos os custos estimados das operadoras. Por sua vez, o custo estimado de cada operador é a soma do custo estimado de E/S e o custo estimado de CPU. A unidade de custo não tem sentido por si só. Sua relevância está na comparação que o otimizador faz entre os planos candidatos. Ou seja, as fórmulas de custeio foram desenhadas com o objetivo de que, entre os planos candidatos, aquele com o menor custo represente (espero) aquele que terminará mais rapidamente. Uma tarefa terrivelmente complexa para fazer com precisão!
Quanto mais as fórmulas de custeio levarem em conta adequadamente os fatores que realmente afetam o desempenho e o dimensionamento do algoritmo, mais precisas elas serão e maior a probabilidade de que, com estimativas de cardinalidade precisas, o otimizador escolha o plano ideal. De qualquer forma, se você quiser entender por que o otimizador escolhe um algoritmo em vez de outro, você precisa entender duas coisas principais:uma é como os algoritmos funcionam e escalam, e outra é o modelo de custo do SQL Server.
Então, de volta ao plano da Figura 1; vamos tentar entender como os custos são calculados. Como política, a Microsoft não revelará as fórmulas internas de custeio usadas. Quando eu era criança, eu era fascinado por desmontar as coisas. Relógios, rádios, fitas cassete (sim, eu sou tão velho), você escolhe. Eu queria saber como as coisas eram feitas. Da mesma forma, vejo valor na engenharia reversa das fórmulas, pois se eu conseguir prever o custo com razoável precisão, provavelmente significa que entendo bem o algoritmo. Durante o processo você aprende muito.
Nossa consulta ingere 1.000.000 de linhas. Mesmo com esse número de linhas, o custo de E/S parece ser insignificante comparado ao custo da CPU, portanto, provavelmente é seguro ignorá-lo.
Quanto ao custo da CPU, você quer tentar descobrir quais fatores o afetam e de que maneira. Teoricamente, pode haver vários fatores:número de linhas de entrada, número de grupos, cardinalidade do conjunto de agrupamento, tipo de dados e tamanho dos membros do conjunto de agrupamento. Portanto, para tentar medir o efeito de qualquer um desses fatores, você deseja comparar os custos estimados de duas consultas que diferem apenas no fator que deseja medir. Por exemplo, para medir o impacto do número de linhas no custo, faça duas consultas com um número diferente de linhas de entrada, mas com todos os outros aspectos iguais (número de grupos, cardinalidade do conjunto de agrupamento, etc.). Além disso, é importante verificar se os números estimados - não os reais - são os desejados, pois o otimizador depende dos números estimados para calcular os custos.
Ao fazer essas comparações, é bom ter técnicas que permitam controlar totalmente os números estimados. Por exemplo, uma maneira simples de controlar o número estimado de linhas de entrada é consultar uma expressão de tabela baseada em uma consulta TOP e aplicar a função agregada na consulta externa. Se você estiver preocupado que devido ao uso do operador TOP o otimizador aplicará metas de linha e que isso resultará no ajuste dos custos originais, isso se aplica apenas aos operadores que aparecem no plano abaixo do operador Top (ao direita), não acima (à esquerda). O operador Stream Aggregate aparece naturalmente acima do operador Top no plano, pois ingere as linhas filtradas.
Quanto ao controle do número estimado de grupos de saída, você pode fazê-lo usando a expressão de agrupamento
Para garantir que você obtenha o algoritmo Stream Aggregate e um plano serial, você pode forçar isso com as dicas de consulta:OPTION(ORDER GROUP, MAXDOP 1).
Você também deseja descobrir se há algum custo inicial para o operador, para que possa considerá-lo em sua fórmula de engenharia reversa.
Vamos começar descobrindo como o número de linhas de entrada afeta o custo estimado de CPU do operador. Claramente, este fator deve ser relevante para o custo do operador. Além disso, você esperaria que o custo por linha fosse constante. Aqui estão algumas consultas para comparação que diferem apenas no número estimado de linhas de entrada (chame-as de Consulta 2 e Consulta 3, respectivamente):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
A Figura 2 tem as partes relevantes dos planos estimados para essas consultas:

Figura 2:planos para consulta 2 e consulta 3
Supondo que o custo por linha seja constante, você pode calculá-lo como a diferença entre os custos do operador dividido pela diferença entre as cardinalidades de entrada do operador:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
Para verificar se o número obtido é realmente constante e correto, você pode tentar prever os custos estimados em consultas com outros números de linhas de entrada. Por exemplo, o custo previsto com 500.000 linhas de entrada é:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Use a seguinte consulta para verificar se sua previsão está correta (chame-a de Consulta 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
A parte relevante do plano para esta consulta é mostrada na Figura 3.
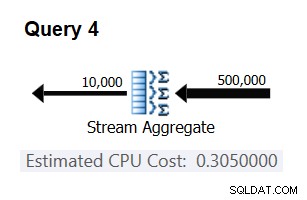
Figura 3:plano para a consulta 4
Bingo. Naturalmente, é uma boa ideia verificar várias cardinalidades de entrada adicionais. Com todos os que verifiquei, a tese de que há um custo constante por linha de entrada de 0,0000006 estava correta.
Em seguida, vamos tentar descobrir como o número estimado de grupos afeta o custo de CPU da operadora. Você esperaria que algum trabalho de CPU fosse necessário para processar cada grupo, e também é razoável esperar que seja constante por grupo. Para testar esta tese e calcular o custo por grupo, você pode usar as duas consultas a seguir, que diferem apenas no número de grupos de resultados (chame-as de Consulta 5 e Consulta 6, respectivamente):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
As partes relevantes dos planos de consulta estimados são mostradas na Figura 4.
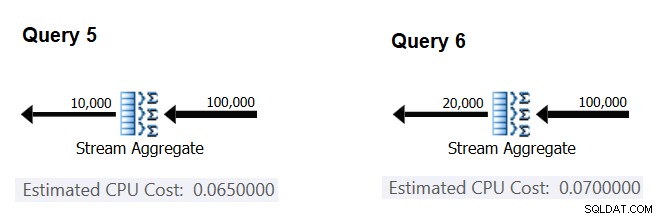
Figura 4:planos para consulta 5 e consulta 6
Da mesma forma que você calculou o custo fixo por linha de entrada, você pode calcular o custo fixo por grupo de saída como a diferença entre os custos do operador dividido pela diferença entre as cardinalidades de saída do operador:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
E assim como demonstrei antes, você pode verificar suas descobertas prevendo os custos com outros números de grupos de saída e comparando seus números previstos com os produzidos pelo otimizador. Com todos os números de grupos que tentei, os custos previstos foram precisos.
Usando técnicas semelhantes, você pode verificar se outros fatores afetam o custo do operador. Meus testes mostram que a cardinalidade do conjunto de agrupamento (número de expressões pelas quais você agrupa), os tipos de dados e os tamanhos das expressões agrupadas não têm impacto no custo estimado.
O que resta é verificar se há algum custo de inicialização significativo assumido para o operador. Se houver, a fórmula completa (espero) para calcular o custo de CPU do operador deve ser:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Assim, você pode derivar o custo inicial do resto:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
Você pode usar qualquer plano de consulta deste artigo para essa finalidade. Por exemplo, usando os números do plano para a Consulta 5 mostrado anteriormente na Figura 4, você obtém:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Ao que parece, o operador Stream Aggregate não tem nenhum custo de inicialização relacionado à CPU ou é tão baixo que não é mostrado com a precisão da medida de custo.
Em conclusão, a fórmula de engenharia reversa para o custo do operador Stream Aggregate é:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
A Figura 5 descreve o dimensionamento do custo do operador Stream Aggregate em relação ao número de linhas e ao número de grupos.
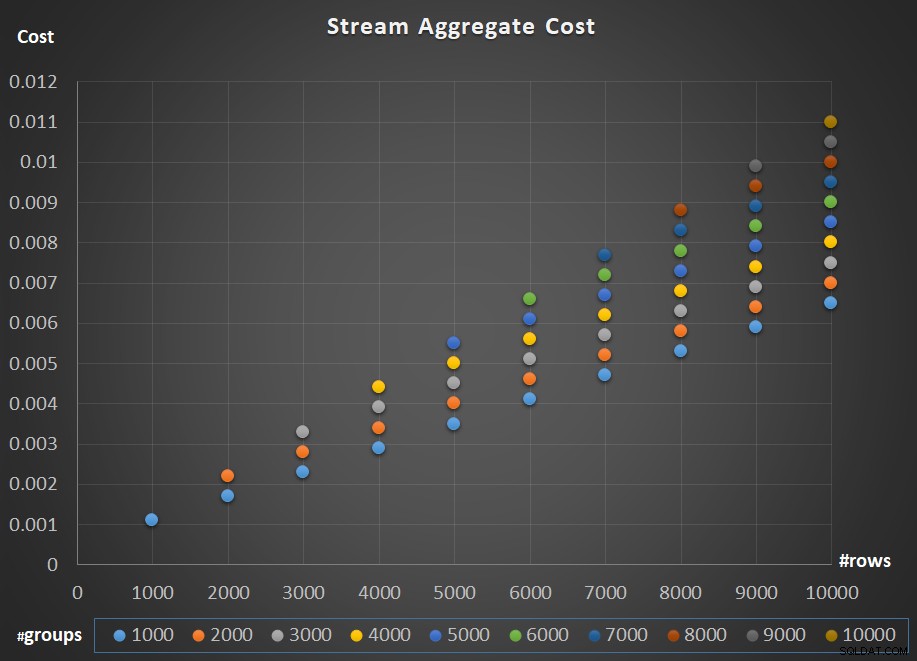
Figura 5:gráfico de dimensionamento do algoritmo agregado de fluxo
Quanto ao escalonamento do operador; é linear. Nos casos em que o número de grupos tende a ser proporcional ao número de linhas, o custo de todo o operador aumenta pelo mesmo fator que aumenta o número de linhas e grupos. O que significa que dobrar o número de linhas de entrada e grupos de entrada resulta na duplicação do custo total do operador. Para ver por que, suponha que representemos o custo do operador como:
r * 0.0000006 + g * 0.0000005
Se você aumentar o número de linhas e o número de grupos pelo mesmo fator p, obterá:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Portanto, se, para um determinado número de linhas e grupos, o custo do operador Stream Aggregate for C, aumentar o número de linhas e grupos pelo mesmo fator p resulta em um custo do operador pC. Veja se você pode verificar isso identificando exemplos no gráfico da Figura 5.
Nos casos em que o número de grupos permanece bastante estável mesmo quando o número de linhas de entrada aumenta, você ainda obtém escala linear. Você apenas considera o custo associado ao número de grupos como uma constante. Ou seja, se para um determinado número de linhas e grupos o custo do operador for C =G (custo associado ao número de grupos) mais R (custo associado ao número de linhas), aumentando apenas o número de linhas por um fator de p resulta em G + pR. Nesse caso, naturalmente, todo o custo do operador é menor que pC. Ou seja, dobrar o número de linhas resulta em menos que o dobro do custo total do operador.
Na prática, em muitos casos, quando você agrupa dados, o número de linhas de entrada é substancialmente maior que o número de grupos de saída. Este fato, aliado ao fato de que o custo alocado por linha e o custo por grupo são quase os mesmos, a parcela do custo da operadora que é atribuída ao número de grupos torna-se insignificante. Como exemplo, veja o plano para a Consulta 1 mostrado anteriormente na Figura 1. Nesses casos, é seguro pensar no custo do operador simplesmente como escalando linearmente em relação ao número de linhas de entrada.
Casos especiais
Existem casos especiais em que o operador Stream Aggregate não precisa dos dados classificados. Se você pensar bem, o algoritmo Stream Aggregate tem um requisito de ordenação mais relaxado da entrada em comparação com quando você precisa dos dados ordenados para fins de apresentação, por exemplo, quando a consulta tem uma cláusula ORDER BY de apresentação externa. O algoritmo Stream Aggregate simplesmente precisa que todas as linhas do mesmo grupo sejam ordenadas juntas. Pegue o conjunto de entrada {5, 1, 5, 2, 1, 2}. Para fins de ordenação de apresentação, esse conjunto deve ser ordenado da seguinte forma:1, 1, 2, 2, 5, 5. Para fins de agregação, o algoritmo Stream Aggregate ainda funcionaria bem se os dados fossem organizados na seguinte ordem:5, 5, 1, 1, 2, 2. Com isso em mente, quando você calcula uma agregação escalar (consulta com uma função de agregação e nenhuma cláusula GROUP BY) ou agrupa os dados por um conjunto de agrupamento vazio, nunca há mais de um grupo . Independentemente da ordem das linhas de entrada, o algoritmo Stream Aggregate pode ser aplicado. O algoritmo Hash Aggregate faz o hash dos dados com base nas expressões do conjunto de agrupamento como entradas e, tanto com agregados escalares quanto com um conjunto de agrupamento vazio, não há entradas para hash. Assim, tanto com agregados escalares quanto com agregados aplicados a um conjunto de agrupamento vazio, o otimizador sempre usa o algoritmo Stream Aggregate, sem exigir que os dados sejam pré-ordenados. Esse é pelo menos o caso no modo de execução de linha, pois atualmente (a partir do SQL Server 2017 CU4) o modo em lote está disponível apenas com o algoritmo Hash Aggregate. Usarei as duas consultas a seguir para demonstrar isso (chame-as de Consulta 7 e Consulta 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
Os planos para essas consultas são mostrados na Figura 6.
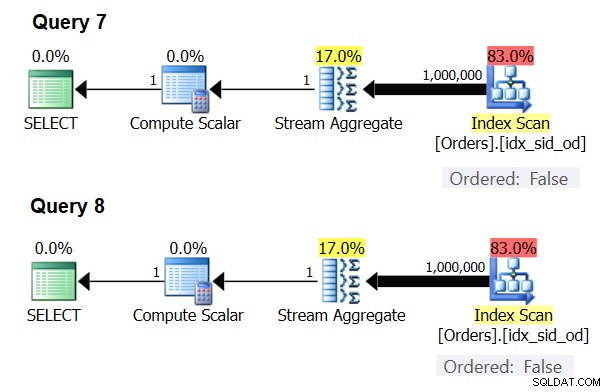
Figura 6:planos para consulta 7 e consulta 8
Tente forçar um algoritmo Hash Aggregate em ambos os casos:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
O otimizador ignora sua solicitação e produz os mesmos planos mostrados na Figura 6.
Teste rápido:qual é a diferença entre um agregado escalar e um agregado aplicado a um conjunto de agrupamento vazio?
Resposta:com um conjunto de entrada vazio, uma agregação escalar retorna um resultado com uma linha, enquanto uma agregação em uma consulta com um conjunto de agrupamento vazio retorna um conjunto de resultados vazio. Tente:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Quando terminar, execute o seguinte código para limpeza:
DROP INDEX idx_sid_od ON dbo.Orders;
Resumo e desafio
A engenharia reversa da fórmula de custeio para o algoritmo Stream Aggregate é uma brincadeira de criança. Eu poderia ter dito a você que a fórmula de custeio para um algoritmo Stream Aggregate pré-ordenado é @numrows * 0,0000006 + @numgroups * 0,0000005 em vez de um artigo inteiro para explicar como você descobre isso. O objetivo, no entanto, era descrever o processo e os princípios da engenharia reversa, antes de passar para os algoritmos mais complexos e os limites em que um algoritmo se torna mais ideal que os outros. Ensinando você a pescar em vez de lhe dar um tipo de coisa de peixe. Aprendi muito e descobri coisas nas quais nem pensei, enquanto tentava fazer engenharia reversa de fórmulas de custeio para vários algoritmos.
Pronto para testar suas habilidades? Sua missão, se você optar por aceitá-la, é um pouco mais difícil do que a engenharia reversa do operador Stream Aggregate. Faça engenharia reversa da fórmula de custeio de um operador de classificação serial. Isso é importante para nossa pesquisa, pois um algoritmo Stream Aggregate aplicado a uma consulta com um conjunto de agrupamento não vazio, onde os dados de entrada não são pré-ordenados, requer classificação explícita. Nesse caso, o custo e o dimensionamento da operação agregada dependem do custo e do dimensionamento dos operadores Sort e Stream Aggregate combinados.
Se você conseguir se aproximar decentemente da previsão do custo do operador de classificação, poderá sentir que ganhou o direito de adicionar à sua assinatura “Engenheiro Reverso”. Existem muitos engenheiros de software por aí; mas você certamente não vê muitos engenheiros reversos! Apenas certifique-se de testar sua fórmula tanto com números pequenos quanto com números grandes; você pode se surpreender com o que você encontra.