Existem várias maneiras de entrar em contato com alguém hoje em dia, certo?
Temos vários telefones:celular e fixo, pessoal e de trabalho. Temos endereços diferentes – residencial, de correspondência, cobrança, comercial, etc. – e provavelmente vários endereços de e-mail também. Não se esqueça do Skype e de vários aplicativos de mensagens. Agora adicione o LinkedIn e o Facebook – que por sinal, ambos têm seus próprios elementos de mensagens.
Não faz muito tempo, muitos deles não existiam. Portanto, você pode garantir que, em alguns anos, teremos uma nova maneira de entrar em contato com pessoas e organizações.
Podemos modelar todas essas informações de contato de forma que não precisemos alterar nosso design de banco de dados quando 'a última coisa' aparecer? Leia mais para descobrir…
O modelo de ponto de contato do partido
Em uma palavra, sim. Bancos de dados podem ser projetados para acomodar informações que ainda nem temos.
Vou pular direto e mostrar a solução, depois descreverei como as peças funcionam juntas. Vou ligar para as várias formas de contato pontos de contato , embora eu tenha visto métodos de contato e até mesmo locais de contato usado.
Fisicamente, todos esses pontos de contato serão armazenados em uma única coluna da tabela,
contact_point.contact_value . Pense em um número de telefone, um endereço de e-mail ou um endereço da web (URL) e você entenderá por que podemos armazená-los aqui; eles são apenas strings (varchars) neste nível. A diferenciação está nos metadados. A única exceção a isso é o endereço postal, que será descrito com mais detalhes posteriormente. As tabelas amarelas à esquerda contêm metadados e as tabelas azuis à direita contêm dados comerciais.
As principais categorias
Embora tenhamos muitas maneiras de entrar em contato com alguém, essas maneiras na verdade se enquadram em um pequeno número de categorias ou tipos. Você verá o que quero dizer quando você olhar para a lista abaixo:
| Tipo de ponto de contato |
|---|
| Número de telefone (fixo) |
| Número de celular |
| Número de fax |
| Endereço de e-mail |
| Endereço Postal |
| Endereço da Web |
| Pager |
Em certo sentido, estes são fisicamente distintos. Claro, você pode usar um telefone celular para ligar para um telefone fixo ou outro celular. Quando se trata de chamadas de voz entre telefones fixos e celulares, a distinção não é tão importante. Ainda assim, é mais provável que enviemos um texto (SMS) para um celular do que para um telefone fixo.
Mas não é provável que você ligue deliberadamente por voz para um número de fax. Afinal, o que você vai dizer quando ouvir, além de 'Opa, número errado'? Naturalmente, é muito mais provável que você ligue com outra máquina de fax, seja física ou emulada. Você também não enviaria uma carta para um telefone fixo ou tentaria fazer uma chamada de voz para um endereço postal.
É importante distinguir esses tipos, porque interagimos de maneira diferente com eles. Isso será especialmente verdadeiro se seu aplicativo tiver algum tipo de integração com serviços de comunicação. Ele precisa saber com qual tipo interagir.
Como as partes usam os pontos de contato
Isso provavelmente é um pouco mais intuitivo, um pouco mais alinhado com a forma como pensamos sobre os tipos de contato. Aqui está uma lista mais longa (mas não exaustiva!) que o ajudará a ter uma ideia desses tipos:
| Tipo de contato da parte (tipo de ponto de contato) |
|---|
| Linha de conferência (número de telefone) |
| Endereço de cobrança (endereço postal) |
| Endereço de entrega (endereço postal) |
| Linha direta (número de telefone) |
| Endereço de férias/férias (endereço postal) |
| Telefone de férias/férias (Número de telefone) |
| Endereço residencial (endereço postal) |
| Telefone residencial (Número de telefone) |
| Telefone residencial/fax (Número de telefone) |
| Perfil do LinkedIn (endereço da Web) |
| Endereço principal (endereço postal) |
| E-mail principal (endereço de e-mail) |
| Fax principal (Número de fax) |
| Telefone principal (Número de telefone) |
| Site principal (endereço da Web) |
| E-mail pessoal (endereço de e-mail) |
| Fax pessoal (número de fax) |
| Celular pessoal (Número de celular) |
| Pager pessoal (Pager) |
| Site pessoal (endereço da Web) |
| Endereço secundário (endereço postal) |
| Telefone secundário (Número de telefone) |
| Perfil de mídia social (endereço da Web) |
| Endereço comercial (endereço postal) |
| E-mail comercial (endereço de e-mail) |
| Fax de trabalho (número de fax) |
| Celular do trabalho (Número do celular) |
| Telefone comercial (número de telefone) |
O endereço postal – um caso especial
Todos esses tipos de pontos de contato são armazenados em um único campo, com exceção de um endereço postal. Isso normalmente requer um número de linhas (ou campos).
Há um artigo de blog aqui que propõe uma maneira simples e independente de idioma de armazenar endereços postais. Se os seus requisitos são bastante básicos – por exemplo, imprimir etiquetas de endereço praticamente à medida que são inseridas no sistema – essa abordagem provavelmente será suficiente. Se suas necessidades forem mais sofisticadas, você provavelmente terá que desenvolver uma solução diferente.
Para ter uma ideia de quão complexo o endereçamento pode ser, dê uma olhada rápida neste Esquema para Tipos de Endereço Padrão Britânico BS7666. O padrão compreende várias partes que abrangem os Diários de Rua, Diários de Terras e Propriedades e pontos de entrega. Não diferencia entre imóveis comerciais ou residenciais; entre terrenos ocupados, desenvolvidos ou devolutos; entre áreas urbanas ou rurais; ou entre entidades endereçáveis por correio e entidades não endereçáveis por correio s como postes de comunicação (torres). Para conseguir isso, ele introduz termos com os quais a maioria de nós provavelmente não está familiarizada, como Primary Addressable Object (PAO), que é o nome dado a um objeto endereçável que pode ser endereçado sem referência a outro objeto endereçável. Exemplos familiares de PAOs incluem um nome de edifício ou um número de rua. Um objeto endereçável secundário (SAO) é dado a qualquer objeto endereçável que é endereçado por referência a um PAO. Este pode ser o primeiro andar de um edifício nomeado.
Para nos dar uma visualização disso, rapidamente fiz a engenharia reversa em uma ferramenta de modelagem UML. Aqui está o que obtemos:
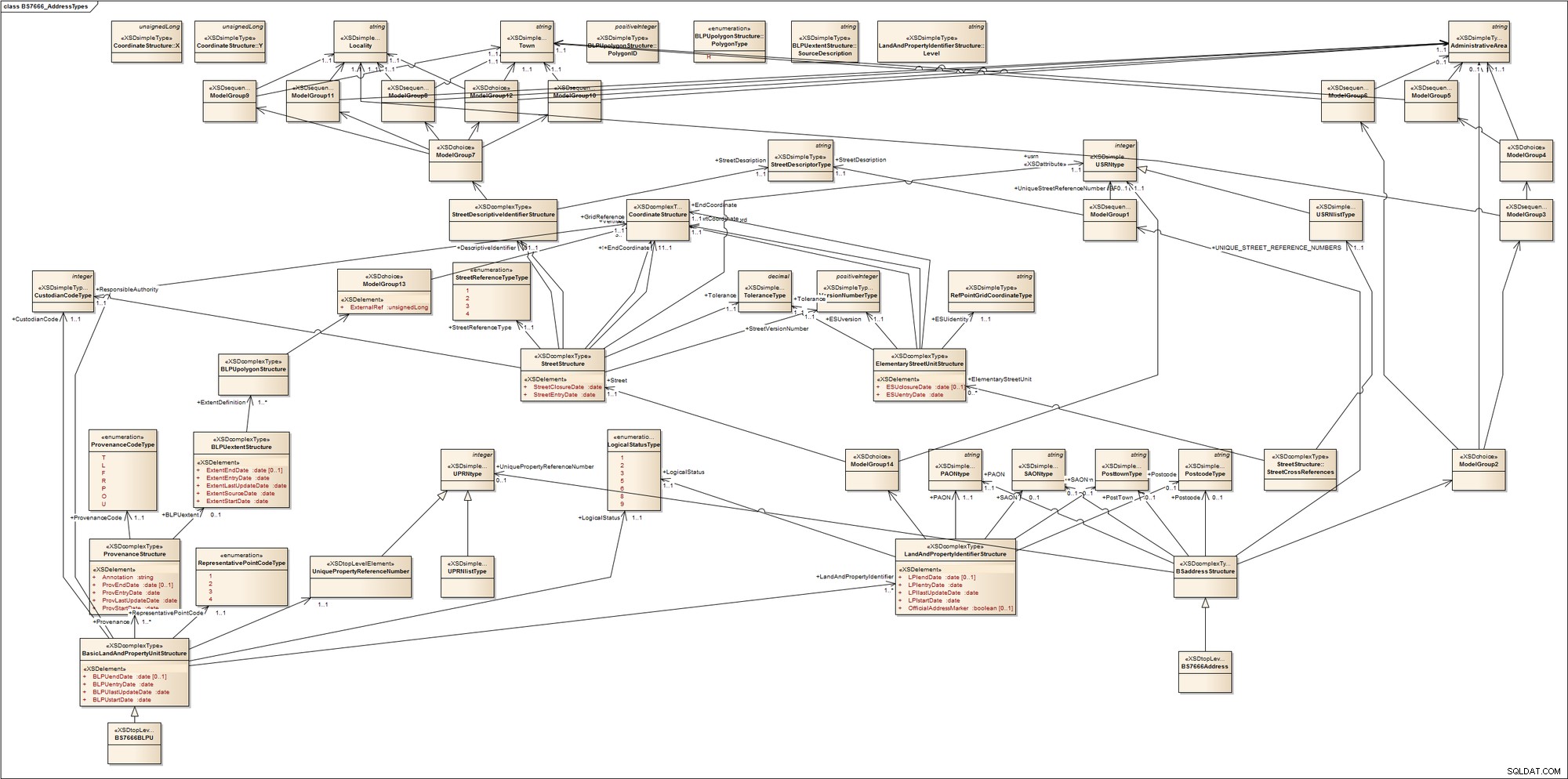
Meu ponto é que pode ficar bem complicado e confuso; endereçamento em alguns domínios pode ser realmente muito complexo.
Se você achatar isso em uma única tabela relacional, você obteria algo como o seguinte:
Embora isso capture os componentes do endereço BS7666, não informa como o modelo funciona. Toda a lógica relacional do esquema XML fica escondida na lógica do aplicativo.
Esses dois diagramas representam dois extremos de modelagem de dados . Mas existe um meio termo para modelar endereços?
É realmente possível ter um modelo de endereço relativamente simples, flexível e configurável.
Componentes de endereço
Um componente de endereço normalmente é uma linha em uma etiqueta de endereço, ou melhor, um tipo de linha em uma etiqueta de endereço. O tipo de componentes que normalmente usamos para endereços do Reino Unido estão listados na tabela a seguir:
| Tipo de componente de endereço |
|---|
| Destinatário |
| Área |
| Nome do edifício |
| Número do edifício |
| País |
| Condado |
| Nome do Departamento |
| Localidade Dependente |
| Nome da Via Dependente |
| Localidade duplamente dependente |
| Código postal internacional |
| Nível |
| Localidade |
| SSC Mailsort |
| Nome da organização |
| Número final do PAO |
| Sufixo Final do PAO |
| Número inicial do PAO |
| Sufixo de início do PAO |
| Texto PAO |
| Caixa postal |
| Código postal |
| Cidade Postal |
| Código postal |
| Tipo de código postal |
| Número final do SAO |
| Sufixo Final SAO |
| Número inicial do SAO |
| Sufixo de início SAO |
| Texto SAO |
| Rua |
| Descrição da rua |
| Nome do Subedifício |
| Nome da Via |
| Cidade |
Você pode ter três ou quatro linhas de endereço, além da cidade postal e do código postal. No entanto, a dificuldade que você encontrará é identificar o que essas linhas realmente contêm quando importa – por exemplo ao mapear dados entre sistemas. Ao realizar a criação de perfil de dados, você descobrirá que a Linha de Endereço 3 às vezes contém uma localidade dependente, mas outras vezes contém um município ou localidade. Agora você está no processamento de linguagem natural (NLP); você precisa reconhecer a diferença entre localidade e município. E as permutações se multiplicam à medida que você adiciona mais países.
Portanto, devemos definir todos os componentes de endereço para todos os países em que operamos.
Formatos de endereço
Os formatos de endereço são compostos de duas partes:um cabeçalho e seu detalhe. O cabeçalho é basicamente o nome ou título que o formato de endereço é conhecido por. Os exemplos podem incluir:
| Tipo de formato de endereço |
|---|
| Genérico de 3 linhas |
| Genérico de 5 linhas |
| Correios das Forças Britânicas (BFPO) |
| Internacional |
| Endereço dos Correios (PAF) |
| EUA Endereço |
| Endereço francês |
Tomando como exemplo o Full Post Office Address Format (PAF) do Reino Unido, definimos os seguintes componentes de formato de endereço:
| Formato | Componente | Sequência | É obrigatório? |
|---|---|---|---|
| PAF | Destinatário | 1 | N |
| PAF | Nome da organização | 2 | N |
| PAF | Nome do Departamento | 3 | N |
| PAF | Caixa postal | 4 | N |
| PAF | Nome do edifício | 5 | N |
| PAF | Nome do Sub-edifício | 6 | N |
| PAF | Número do edifício | 7 | N |
| PAF | Viagem | 8 | N |
| PAF | Rua | 9 | N |
| PAF | Localidade duplamente dependente | 10 | N |
| PAF | Localidade Dependente | 11 | N |
| PAF | Cidade Postal | 12 | S |
| PAF | Código postal | 13 | S |
Nosso aplicativo lê esses metadados e exibe os componentes de endereço na ordem correta. Quando a captura de endereço é necessária, os metadados nos informam se o componente de endereço é obrigatório ou não.
Mais frequentemente, nosso aplicativo solicita o código postal do usuário final e procura os valores correspondentes e preenche os componentes de endereço automaticamente. Alguns aplicativos permitem que o usuário edite o endereço; outros [irritantes] não!
Ele não é mostrado no PDM, mas se sua organização opera internacionalmente, você pode definir um relacionamento de muitos para muitos entre
address_format_type e country para que o formato de endereço correto (com base no país do usuário) seja apresentado ao usuário final (party ). Quando e somente quando o
contact_point é um endereço postal contact_point_type , ele deve ter um relacionamento com um address_format_type. Por outro lado, segue-se que os tipos de endereços não postais nunca ter uma relação com um address_format_type . Além disso, o formato deve permanecer fixo durante a vida útil do contact_point , caso contrário, você introduzirá a possibilidade de problemas de integridade de dados. (Para que não seja o caso , o destino address_format_components deve ser um subconjunto da fonte address_format_components ). A coluna
contact_value não tem significado para um endereço postal porque os valores são armazenados em umddress_line.line_content . Por outro lado, contact_value é obrigatório para todos os outros contact_point_types . Basicamente, contact_point.contact_value e address_line.line_content são mutuamente exclusivos. A relação de muitos para muitos entre a parte e o ponto de contato
Você pode pensar em
contact_point (mais address_line ) como contendo os valores e party_contact como definir o uso. Isso permite que um único contact_point ter vários usos . Nosso endereço residencial [postal] também pode ser nosso endereço de cobrança e endereço de entrega, dependendo do contexto. Até agora, a narrativa assumiu que uma parte possui um determinado
contact_point . Mas o modelo de dados não impõe essa regra de propriedade! Não faz qualquer tipo de restrição. Há outra possibilidade que existe com este design:várias partes para os mesmos pontos de contato. Você precisa considerar cuidadosamente as implicações antes de se aventurar por esse caminho.
Aqui está um exemplo. No Reino Unido, as Organizações de Premiação (AOs) geralmente empregam professores como examinadores. Um professor tem duas relações:uma com a escola onde trabalha e outra com a AO como examinadora. A escola terá um banco de
contact_points com vários números de telefone e possivelmente um ou mais endereços postais. Serão coisas como o endereço principal da escola (endereço postal), e-mail principal (endereço de e-mail), fax principal (número de fax) e telefone principal (número de telefone). É totalmente viável que nosso examinador possa usar os mesmos
contact_points como sua escola, mas ele ou ela usará party_contact para defini-los como relacionados ao trabalho. Se o número de telefone principal da escola mudar, o número do trabalho do professor será atualizado automaticamente, o que é bem legal. Se você seguir esse caminho, precisará definir no nível do aplicativo qual parte ou partes têm permissão para atualizar
contact_points . Uma palavra rápida sobre o desempenho
As tabelas de metadados amarelas serão constantemente usadas pelas consultas. Consequentemente, eles provavelmente permanecerão na memória. Na maioria dos RDBMSs, você pode fixar tabelas na memória para garantir isso. No Oracle, eu as criaria como tabelas organizadas por índice, que são pequenas e funcionam bem. Faça o que for equivalente para o seu RDBMS.
Você também deseja garantir que
party_contact as linhas são colocadas no mesmo bloco (ou página) usando um índice clusterizado em party_id . Faça o mesmo com address_line.contact_point_id . Isso reduz a quantidade de IO. Existe outra opção se você quiser uma
party possuir exclusivamente um contact_point . Você pode então mesclar contact_point em party_contact para criar party_contact_point (ainda agrupado em party_id ). Isso simplifica o modelo e pode ajudar no desempenho. Alterar contatos não significa alterar bancos de dados
Vivemos numa época em que se pode dizer que a mudança é a única constante.
Isso não significa que cada vez que algo muda, isso tem que impactar seu banco de dados. Com um pouco de reflexão, podemos preparar nossos projetos para o futuro – talvez mais do que fizemos até agora. Fazer isso nos ajuda a responder rapidamente à mudança inevitável.
Se você está embarcando em um projeto greenfield, eu recomendaria usar o Party Model (do qual o Contact Point faz parte) para organizações e pessoas. Por que não abrir o modelo e ajustá-lo às suas necessidades? Por favor, sinta-se à vontade para pegar uma cópia e torná-la sua.
Mas se seu banco de dados ou bancos de dados já estiverem determinados, o esquema que apresentei aqui ainda pode ser usado, em formato XML, para definir sua carga útil ao integrar dados entre sistemas.



