Você quer aprender a projetar um sistema de banco de dados e mapear um processo de negócios para um modelo de dados? Então este post é para você.
Neste artigo, você verá como criar um esquema de banco de dados simples para uma empresa de recrutamento. Depois de ler este tutorial, você poderá entender como os esquemas de banco de dados são projetados para aplicativos do mundo real.
O Processo de Negócios do Sistema de Recrutamento
Antes de projetar qualquer banco de dados ou modelo de dados, é imperativo entender o processo de negócios básico para esse sistema. O esquema de banco de dados que criaremos é para uma empresa ou equipe de recrutamento imaginária. Vamos primeiro ver as etapas envolvidas na contratação de novos funcionários:
- As empresas entram em contato com agências de recrutamento para contratar em seu nome. Em alguns casos, as empresas recrutam funcionários diretamente.
- A pessoa responsável pelo recrutamento inicia o processo de recrutamento. Esse processo pode ter várias etapas, como a triagem inicial, um teste escrito, a primeira entrevista, a entrevista de acompanhamento, a decisão de contratação real etc.
- Depois que os recrutadores concordam com um determinado processo – e isso pode mudar dependendo do cliente, da empresa ou do trabalho em questão – a vaga é divulgada em várias plataformas.
- Os candidatos começam a se candidatar à vaga.
- Os candidatos são selecionados e convidados para um teste ou entrevista inicial.
- Os candidatos aparecem para o teste/entrevista.
- Os testes são avaliados pelos recrutadores. Em alguns casos, os testes são encaminhados a especialistas para avaliação.
- As entrevistas dos candidatos são pontuadas por um ou mais recrutadores.
- Os candidatos são avaliados com base em testes e entrevistas.
- A decisão de contratação é tomada.
Um esquema de banco de dados do sistema de recrutamento
Tendo em vista o processo mencionado, nosso esquema de banco de dados é dividido em cinco áreas temáticas:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
Analisaremos cada uma dessas áreas em detalhes, na ordem em que estão listadas. Abaixo, você pode ver todo o modelo de dados.
Processo
A categoria de processo contém informações relacionadas aos processos de recrutamento. Ele contém três tabelas:
process , step e process_step . Veremos cada um. 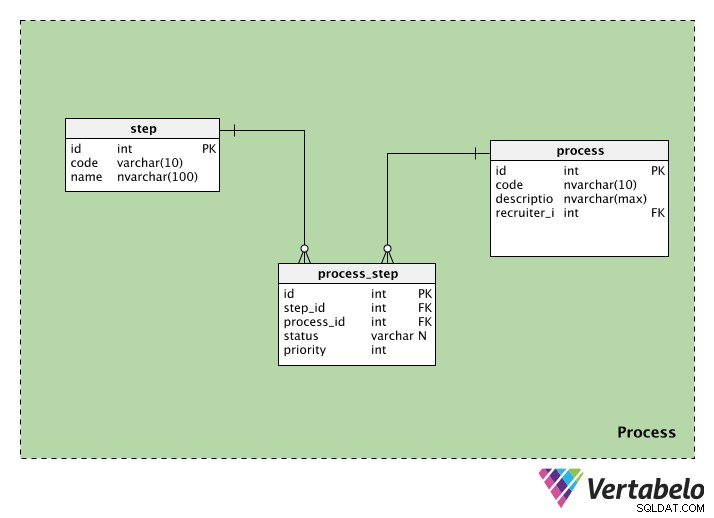
O process tabela armazena informações sobre cada processo de recrutamento. Cada processo terá um id especial, um código e uma description desse processo. Também teremos o recruiter_id da pessoa que inicia o processo.
A step tabela contém informações sobre as etapas seguidas ao longo desse processo de recrutamento. Cada etapa tem um id e um code nome. A coluna de nome pode ter valores como “triagem inicial”, “teste escrito”, “entrevista de RH”, etc.
Como um processo pode ter várias etapas e uma etapa pode fazer parte de muitos processos, precisamos de uma tabela de pesquisa. O process_step A tabela contém informações sobre cada passo (em step_id ) e o processo ao qual ele pertence (em process_id ). Também temos um status, que nos informa o status dessa etapa nesse processo; isso pode ser NULL se a etapa ainda não foi iniciada. Por fim, temos uma priority , que nos diz em qual ordem executar as etapas. As etapas com a priority mais alta valor será executado primeiro.
Trabalhos
Em seguida, temos os
Jobs área de assunto, que armazena todas as informações relacionadas ao(s) emprego(s) para o qual estamos recrutando. O esquema para esta categoria é assim: 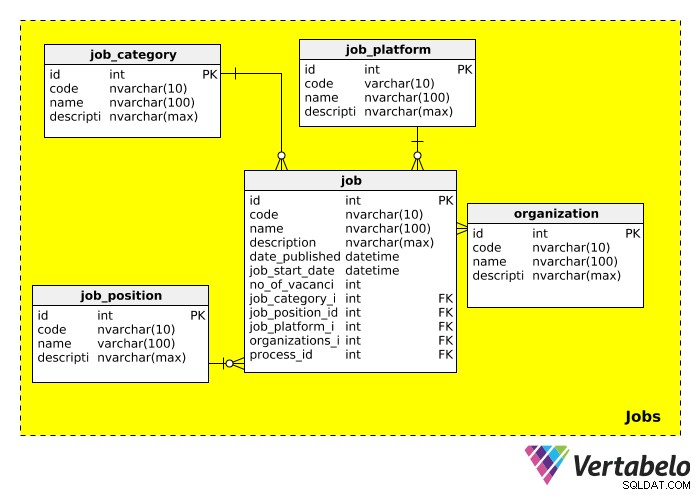
Vamos explicar cada uma das tabelas em detalhes.
A job_category tabela descreve amplamente o tipo de trabalho. Poderíamos esperar ver categorias de trabalho como “TI”, “gerenciamento”, “finanças”, “educação”, etc.
O job_position tabela contém o cargo real. Como um título pode ser anunciado para várias vagas (por exemplo, "Gerente de TI", "Gerente de vendas"), criamos uma tabela separada para cargos. Poderíamos esperar ver valores como “Líder da equipe de TI”, “Vice-presidente” e “Gerente” nesta tabela.
A job_platform tabela refere-se ao meio utilizado para anunciar a vaga de emprego. Por exemplo, um emprego pode ser publicado no Facebook, em um quadro de empregos online ou em um jornal local. Um link para esse anúncio de emprego pode ser adicionado na description campo.
A organization table armazena informações sobre todas as empresas que já utilizaram esse banco de dados como parte de seu processo de contratação. Obviamente, esta tabela é importante quando o recrutamento está sendo feito para outra empresa.
A última tabela nesta área de assunto, job , contém a descrição real do trabalho. A maioria dos atributos são autoexplicativos. Devemos observar que esta tabela possui muitas chaves estrangeiras, o que significa que pode ser usada para pesquisar a categoria, cargo, plataforma, organização contratante e o processo de recrutamento relacionado a essa vaga.
Pedido, Candidato e Documentos
A terceira parte do esquema consiste nas tabelas que armazenam informações sobre candidatos a emprego, suas inscrições e quaisquer documentos que acompanham as inscrições.
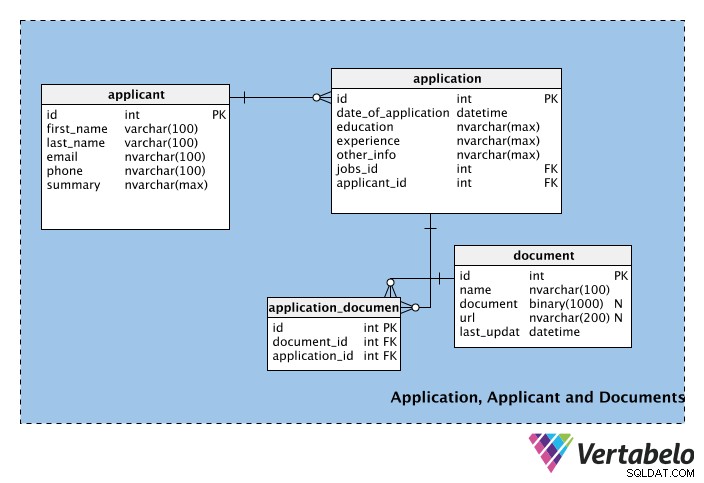
A primeira tabela, applicant , armazena informações pessoais dos candidatos, como nome, sobrenome, e-mail, número de telefone etc. O campo de resumo pode ser usado para armazenar um breve perfil do candidato (ou seja, um parágrafo).
A tabela a seguir contém informações para cada application , incluindo sua data. A tabela também contém a experience e education colunas. Essas colunas podem fazer parte do applicant mas um candidato pode ou não querer exibir uma qualificação educacional específica ou experiência de trabalho em cada inscrição que enviar. Portanto, essas colunas fazem parte do application tabela. O other_info A coluna armazena qualquer outra informação relacionada ao aplicativo. No application table, jobs_id e candidate_id são chaves estrangeiras das tabelas de vagas e candidatos, respectivamente.
Como pode haver vários aplicativos para cada trabalho, mas cada aplicativo é apenas para um trabalho, haverá uma relação de um para muitos entre os jobs e applications mesas. Da mesma forma, um candidato pode enviar várias inscrições (ou seja, para empregos diferentes), mas cada inscrição é de apenas um participante; implementamos outra relação um-para-muitos entre os applicants e applications tabelas para lidar com isso.
O document table gere os documentos comprovativos que os requerentes podem anexar à sua candidatura. Podem ser CVs, currículos, cartas de referência, cartas de apresentação, etc. Observe que esta tabela possui uma coluna binária denominada documento, que armazenará o arquivo em formato binário. Um link para o documento pode ser armazenado no url campo; a coluna name armazena o nome do documento e last_update significa a versão mais recente carregada pelo requerente. Observe que tanto document e url são anuláveis; nenhum é obrigatório, e um requerente pode optar por usar um ou ambos os métodos para adicionar informações ao seu pedido.
Nem todo aplicativo terá um documento anexado. Um documento pode ser anexado a vários aplicativos e um aplicativo pode ter vários documentos de suporte. Isso significa que há uma relação muitos-para-muitos entre o application e document mesas. Para gerenciar esse relacionamento, a tabela de pesquisa application_document foi criado.
Testes e entrevistas
Agora vamos passar para as tabelas que armazenam informações sobre os testes e entrevistas relacionadas ao processo de recrutamento.
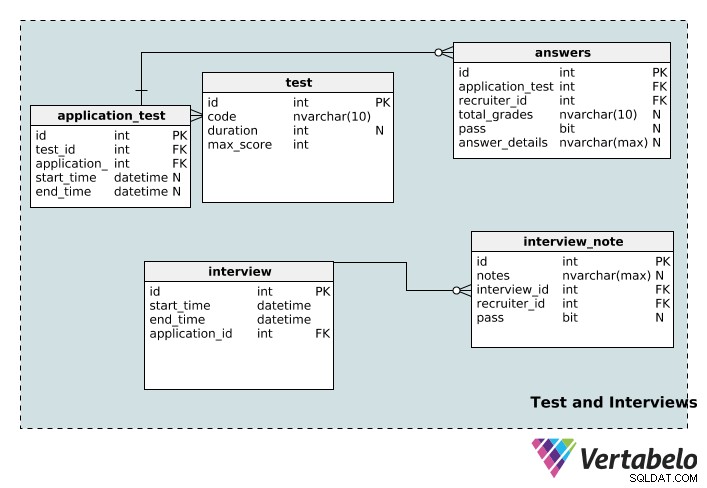
O test A tabela armazena detalhes do teste, incluindo seu id exclusivo , code nome, sua duration em minutos, e o maximum pontuação possível para esse teste.
Um aplicativo pode ser associado a vários testes e um teste pode ser associado a vários aplicativos. Mais uma vez, temos uma tabela de pesquisa para implementar essa relação:application_test . O start_time e end_time as colunas são anuláveis, pois um teste pode não ter uma duração específica, hora de início ou hora de término.
Um teste pode ser avaliado por vários recrutadores e um recrutador pode avaliar vários testes. As answers table é a mesa que torna isso possível. O total_grades A coluna registra o desempenho do candidato no teste e a coluna de aprovação simplesmente indica se essa pessoa foi aprovada ou reprovada. Os detalhes de cada teste individual são registrados em answer_details coluna. Observe que essas três colunas são anuláveis; um teste de aplicação pode ser atribuído a um recrutador que ainda não o classificou. Além disso, um recrutador pode receber um teste antes de ser realmente realizado.
A interview A tabela armazena informações básicas (o start_time , end_time , um id exclusivo e o application_id relevante ) para cada entrevista. Uma entrevista pode ser associada a apenas uma inscrição. Por outro lado, um aplicativo pode ter várias entrevistas. Portanto, existe uma relação um-para-muitos entre a aplicação e a mesa de entrevista.
Uma entrevista pode ser conduzida por vários revisores e um revisor pode fazer várias entrevistas. É outra relação muitos-para-muitos, então criamos a tabela de pesquisa interview_note . Ele armazena informações sobre a entrevista (em interview_id ), o recrutador (em recruiter_id ), e as anotações do recrutador sobre a entrevista. Os recrutadores também podem registrar se o candidato passou ou não na entrevista na coluna de aprovação, que é anulável.
Avaliação e status da solicitação de recrutadores
A última parte do nosso modelo de recrutamento armazena informações sobre recrutadores, status de inscrição e avaliações de inscrição.
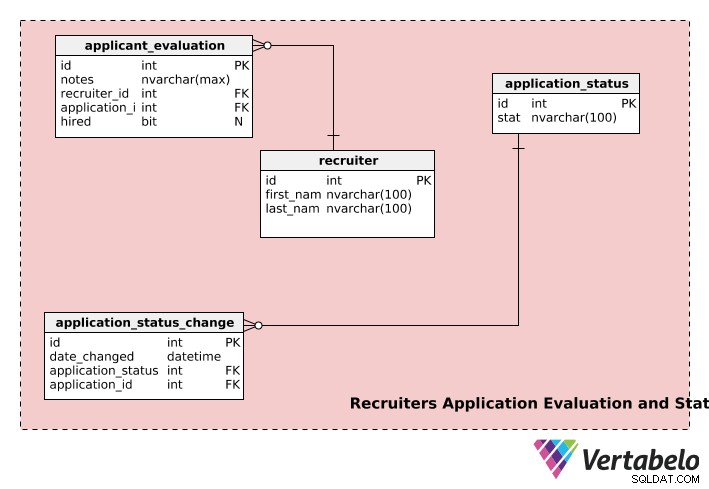
Os recruiters A tabela armazena o first_name de cada recrutador , last_name e id exclusivo número.
A application_evaluation tabela contém informações sobre avaliações de aplicativos. Além do application_id e recruiter_id , contém o feedback do recrutador (em notes ) e a decisão final de contratação, se houver, em hired . Uma inscrição pode ser avaliada por vários recrutadores e um recrutador pode avaliar várias inscrições, de modo que o recruiter e o application tabela tem uma relação de um para muitos com a application_evaluation tabela.
Um aplicativo pode passar por vários estágios durante o processo de contratação, por exemplo, “não enviado”, “em análise”, “aguardando decisão”, “decisão tomada”, etc. Uma inscrição terá o status de “não_enviada” quando o usuário iniciou uma inscrição, mas não a enviou para análise dos recrutadores. Após o envio do pedido, o status é alterado para “em análise” e assim por diante. O application_status tabela é usada para armazenar essas informações.
A application_status_change A tabela é usada para manter um registro das alterações de status de todas as solicitações enviadas. O date_changed A coluna armazena a data da mudança de status. Esta tabela pode ser útil se você quiser analisar o tempo de processamento para cada estágio de diferentes aplicativos. Além disso, o status de qualquer coluna em particular pode ser recuperado usando o application_id coluna do application_status_change tabela.
Um caso de uso de recrutamento simples
Vamos ver como nosso banco de dados pode ajudar no processo de recrutamento.
Suponha que uma empresa tenha designado você para contratar um gerente de TI com experiência em programação. Nosso banco de dados pode nos ajudar a contratar tal pessoa executando as seguintes etapas:
- O primeiro passo é iniciar um novo processo de contratação. Para fazer isso, os dados são inseridos no
processestepsmesas. Um recrutador pode adicionar quantas etapas precisar. - Durante a tarefa acima, o recrutador pode criar um novo trabalho e inserir os detalhes no
job,job_category,job_positioneorganizationmesas. Por fim, um anúncio de emprego será colocado em uma das plataformas armazenadas nojob_platformtabela. - Em seguida, os candidatos criarão um perfil enviando seus dados para o
applicanttabela. Em seguida, eles lançarão um novo aplicativo inserindo mais dados noapplicationtabela. - Os candidatos também podem anexar documentos às suas inscrições. Esses dados serão armazenados no
documenteapplication_documenttabelas. - Se um usuário quiser se candidatar a mais de uma vaga, ele repetirá as etapas 3 e 4.
- Depois que a inscrição for enviada, o status da inscrição será definido como "enviado" (ou outro nome de status escolhido pelo recrutador).
- O recrutador avaliará a inscrição e inserirá seus comentários na
application_evaluationtabela. Nesta fase, a coluna contratada não conterá informações. - Assim que um número adequado de inscrições for recebido, o recrutador executará a próxima etapa mostrada na
process_steptabela. - Se a próxima etapa for administrar algum tipo de teste, o recrutador criará um teste adicionando dados ao
testtabela. - Os testes criados na etapa 9 serão atribuídos a um aplicativo específico. As informações que atribuem cada teste a cada aplicativo serão armazenadas no
application_testtabela. Observe que, durante cada etapa, o status do aplicativo continuará mudando. Isso será registrado noapplication_status_changetabela. - Assim que o candidato concluir o teste, as notas de cada teste de inscrição serão corrigidas pelo recrutador e inseridas na
answertabela. - Após o teste, a próxima etapa da
process_steptabela será executada. Digamos que o próximo passo seja a entrevista. - Os dados da entrevista serão inseridos na
interviewtabela. O recrutador inserirá seus comentários e dirá se a pessoa passou na entrevista ou não. Isso será armazenado nainterview_notetabela. - Se o
processcontém mais etapas de entrevista e teste, elas serão executadas até que a última etapa seja alcançada. - A última etapa da
process_stepnormalmente é a decisão de contratação. Se o candidato passar nos testes e entrevistas e a empresa decidir contratá-lo, os dados serão inseridos na coluna de contratação daapplication_evaluationmesa e a pessoa é contratada.
O que você acha do nosso modelo de dados do sistema de recrutamento?
Neste artigo, vimos como criar um esquema de banco de dados muito simples para um sistema de recrutamento. Dividimos o esquema em quatro categorias e depois explicamos cada uma delas em detalhes. Por fim, executamos um caso de uso para mostrar que nosso esquema pode realmente ajudar a recrutar um funcionário.
Os trabalhos de design de banco de dados estão crescendo. Quer aumentar suas habilidades de banco de dados? Se você é um novato que quer aprender o básico de SQL ou um profissional experiente que quer se ramificar na criação de tabelas em SQL | Curso Interativo | Vertabelo Academy" target="_blank">design de banco de dados, confira os cursos individualizados do LearnSQL.com.