Post de Dan Holmes, que bloga em sql.dnhlms.com.
SQL Server Books Online (BOL), whitepapers e muitas outras fontes mostrarão como e por que você pode querer atualizar estatísticas em uma tabela ou índice. No entanto, você só tem uma maneira de moldar esses valores. Mostrarei como você pode criar as estatísticas exatamente da maneira que deseja dentro dos limites das 200 etapas disponíveis.
Isenção de responsabilidade :Isso funciona para mim porque conheço meu aplicativo, meu banco de dados e o fluxo de trabalho regular do meu usuário e os padrões de uso do aplicativo. No entanto, ele usa comandos não documentados e, se usado incorretamente, pode fazer com que seu aplicativo tenha um desempenho significativamente pior.
Em nosso aplicativo, o usuário do Scheduling está lendo e gravando regularmente dados que representam eventos para amanhã e nos próximos dias. Os dados de hoje e anteriores não são usados pelo Agendador. Logo pela manhã, o conjunto de dados para amanhã começa em algumas centenas de linhas e, ao meio-dia, pode ser de 1400 ou mais. O gráfico a seguir ilustrará as contagens de linhas. Esses dados foram coletados na manhã de quarta-feira, 18 de novembro de 2015. Historicamente, você pode ver que a contagem regular de linhas é de aproximadamente 1.400, exceto nos dias de fim de semana e no dia seguinte.
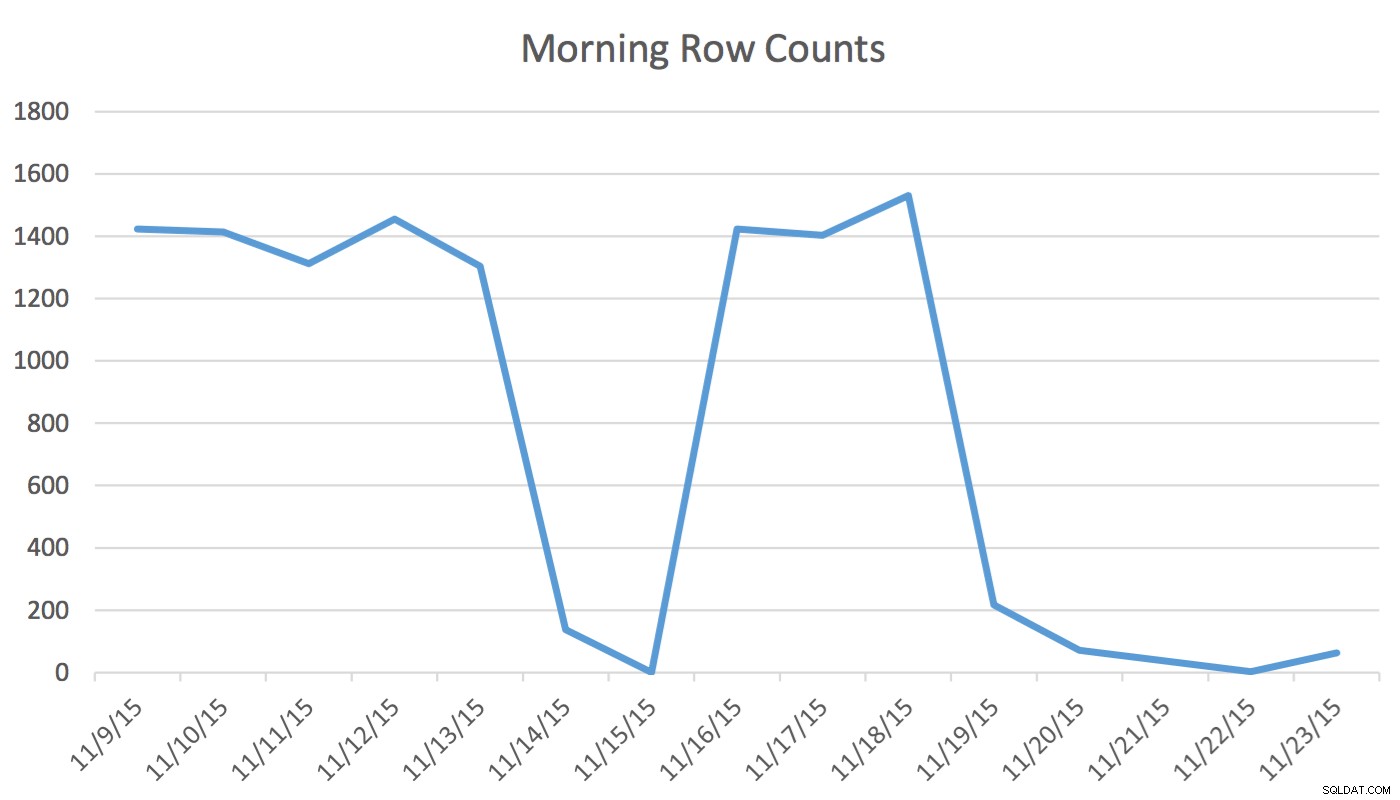
Para o Agendador, os únicos dados pertinentes são os próximos dias. O que está acontecendo hoje e aconteceu ontem não é relevante para sua atividade. Então, como isso causa um problema? Essa tabela tem 2.259.205 linhas, o que significa que a alteração na contagem de linhas da manhã ao meio-dia não será suficiente para acionar uma atualização de estatísticas iniciada pelo SQL Server. Além disso, um trabalho agendado manualmente que cria estatísticas usando
UPDATE STATISTICS preenche o histograma com uma amostra de todos os dados da tabela, mas pode não incluir as informações relevantes. Este delta de contagem de linhas é suficiente para alterar o plano. No entanto, sem uma atualização das estatísticas e um histograma preciso, o plano não mudará para melhor à medida que os dados mudarem. Uma seleção relevante do histograma para esta tabela de um backup datado em 04/11/2015 pode ter esta aparência:
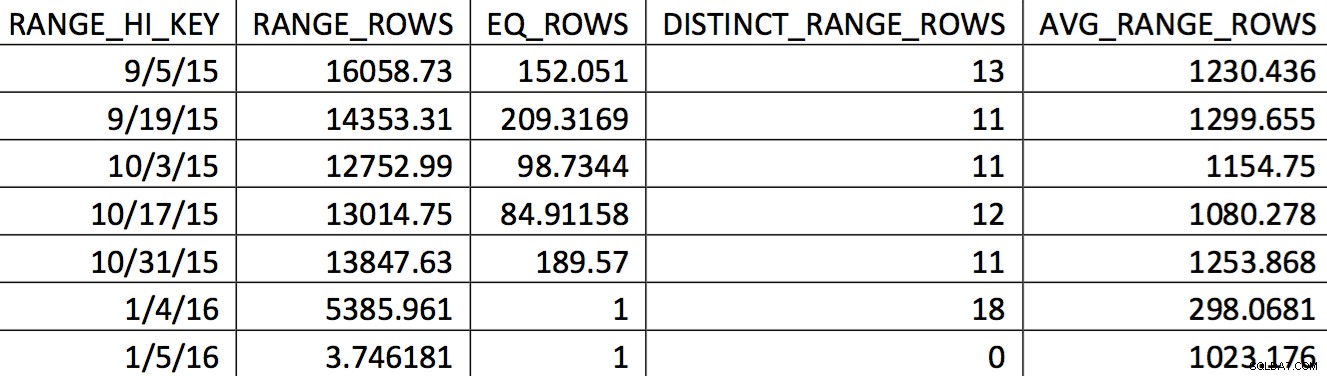
Os valores de interesse não são refletidos com precisão no histograma. O que seria utilizado para a data de 05/11/2015 seria o valor alto 04/01/2016. Com base no gráfico, este histograma claramente não é uma boa fonte de informação para o otimizador para a data de interesse. Forçar os valores de uso no histograma não é confiável, então como você pode fazer isso? Minha primeira tentativa foi usar repetidamente o
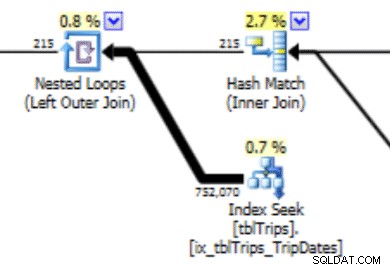
WITH SAMPLE opção de UPDATE STATISTICS e consultar o histograma até que os valores que eu precisava estivessem no histograma (um esforço detalhado aqui). Em última análise, essa abordagem provou não ser confiável. Esse histograma pode levar a um plano com esse tipo de comportamento. A subestimação de linhas produz uma junção de loop aninhado e uma busca de índice. As leituras são subsequentemente mais altas do que deveriam devido a essa escolha de plano. Isso também afetará a duração da instrução.
O que funcionaria muito melhor é criar os dados exatamente como você deseja, e aqui está como fazer isso.
Existe uma opção não suportada de
UPDATE STATISTICS :STATS_STREAM . Isso é usado pelo Suporte ao Cliente da Microsoft para exportar e importar estatísticas para que eles possam obter uma recriação do otimizador sem ter todos os dados na tabela. Podemos usar esse recurso. A ideia é criar uma tabela que imite o DDL da estatística que queremos customizar. Os dados relevantes são adicionados à tabela. As estatísticas são exportadas e importadas para a tabela original. Nesse caso, é uma tabela com 200 linhas de datas não NULL e 1 linha que inclui os valores NULL. Além disso, há um índice nessa tabela que corresponde ao índice que possui os valores de histograma incorretos.
O nome da tabela é
tblTripsScheduled . Tem um índice não clusterizado em (id, TheTripDate) e um índice clusterizado em TheTripDate . Há um punhado de outras colunas, mas apenas as envolvidas no índice são importantes. Crie uma tabela (tabela temporária, se desejar) que imite a tabela e o índice. A tabela e o índice ficam assim:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate); Em seguida, a tabela precisa ser preenchida com 200 linhas de dados nas quais as estatísticas devem se basear. Para a minha situação, é o dia dos próximos sessenta dias. Os últimos 60 dias são preenchidos com uma seleção "aleatória" a cada 10 dias. (O
cnt valor no CTE é um valor de depuração. Ele não desempenha um papel nos resultados finais.) A ordem decrescente para o rn garante que os 60 dias sejam incluídos e, em seguida, o máximo possível do passado. DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate; Nossa tabela agora é preenchida com todas as linhas que são valiosas para o usuário hoje e uma seleção de linhas históricas. Se a coluna
TheTripdate fosse anulável, a inserção também teria incluído o seguinte:UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Em seguida, atualizamos as estatísticas no índice de nossa tabela temporária.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Agora, exporte essas estatísticas para uma tabela temporária. Essa mesa fica assim. Ele corresponde à saída de
DBCC SHOW_STATISTICS WITH HISTOGRAM . CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
); DBCC SHOW_STATISTICS tem uma opção para exportar as estatísticas como um fluxo. É esse fluxo que queremos. Esse fluxo também é o mesmo fluxo que UPDATE STATISTICS opção de fluxo usa. Fazer isso:INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); A etapa final é criar o SQL que atualiza as estatísticas da nossa tabela de destino e depois executá-lo.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); Neste ponto, substituímos o histograma pelo nosso personalizado. Você pode verificar verificando o histograma:
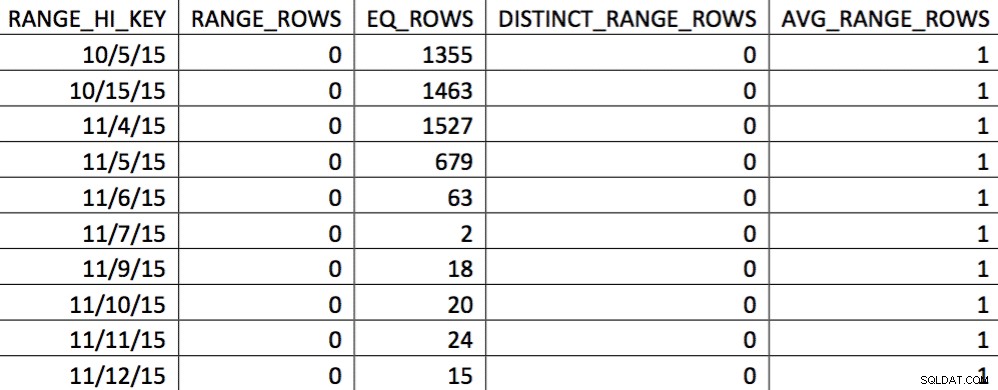
Nesta seleção dos dados de 4/11, todos os dias a partir de 4/11 são representados, e os dados históricos são representados e precisos. Revisitando a parte do plano de consulta mostrado anteriormente, você pode ver que o otimizador fez uma escolha melhor com base nas estatísticas corrigidas:
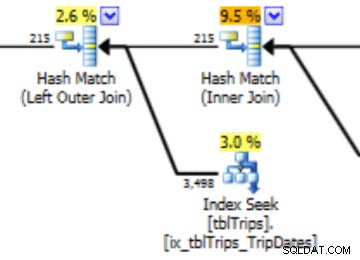
Há um benefício de desempenho para estatísticas importadas. O custo para calcular as estatísticas está em uma tabela "offline". O único tempo de inatividade para a tabela de produção é a duração da importação do fluxo.
Esse processo usa recursos não documentados e parece que pode ser perigoso, mas lembre-se de que há um desfazer fácil:a declaração de estatísticas de atualização. Se algo der errado, as estatísticas sempre podem ser atualizadas usando o T-SQL padrão.
Agendar esse código para ser executado regularmente pode ajudar muito o otimizador a produzir planos melhores, dado um conjunto de dados que muda ao longo do ponto de inflexão, mas não o suficiente para acionar uma atualização de estatísticas.
Quando terminei o primeiro rascunho deste artigo, a contagem de linhas na tabela no primeiro gráfico mudou de 217 para 717. Essa é uma mudança de 300%. Isso é suficiente para alterar o comportamento do otimizador, mas não o suficiente para acionar uma atualização de estatísticas. Essa mudança de dados teria deixado um plano ruim em vigor. É com o processo aqui descrito que este problema é resolvido.
Referências:
- ATUALIZAR ESTATÍSTICAS (Livros Online)
- Documento de Estatísticas do SQL 2008
- Pesquisa de ponto de virada