Implementar uma pesquisa amigável pode ser complicado, mas também pode ser feito com muita eficiência. Como eu sei disso? Não muito tempo atrás, eu precisava implementar um mecanismo de busca em um aplicativo móvel. O aplicativo foi construído no framework Ionic e se conectaria a um backend do CakePHP 2. A ideia era exibir os resultados enquanto o usuário digitava. Havia várias opções para isso, mas nem todas atendiam aos requisitos do meu projeto.
Para ilustrar o que esse tipo de tarefa envolve, vamos imaginar uma busca por músicas e suas possíveis relações (como artistas, álbuns, etc).
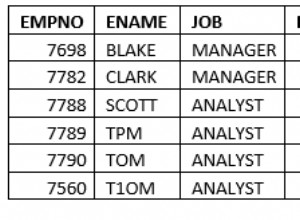
Os registros teriam que ser classificados por relevância, o que dependeria se a palavra de pesquisa correspondia aos campos do próprio registro ou de outras colunas em tabelas relacionadas. Além disso, a pesquisa deve implementar pelo menos algumas derivações básicas de palavras. (Stemming é usado para obter a forma raiz de uma palavra. "Stems", "stemmer", "stemmed" e "stemmed" têm a mesma raiz:"stem".)
A abordagem apresentada aqui foi testada com várias centenas de milhares de registros e conseguiu recuperar resultados úteis à medida que o usuário digitava.
Produtos de pesquisa de texto completo a serem considerados
Existem várias maneiras de implementar esse tipo de pesquisa. Nosso projeto tinha algumas restrições em relação a tempo e recursos do servidor, então tivemos que manter a solução o mais simples possível. Alguns candidatos acabaram surgindo:
Pesquisa elástica
O Elasticsearch fornece pesquisas de texto completo em um serviço orientado a documentos. Ele foi projetado para gerenciar grandes quantidades de carga de forma distribuída:ele pode classificar os resultados por relevância, realizar agregações e trabalhar com palavras derivadas e sinônimos. Esta ferramenta destina-se a pesquisas em tempo real. Do site deles:
O Elasticsearch cria recursos distribuídos sobre o Apache Lucene para fornecer os recursos de pesquisa de texto completo mais poderosos disponíveis. A API de consulta poderosa e amigável ao desenvolvedor suporta pesquisa multilíngue, geolocalização, sugestões contextuais do que você quis dizer, preenchimento automático e snippets de resultados.
O Elasticsearch pode funcionar como um serviço REST, respondendo a solicitações http, e pode ser configurado muito rapidamente. No entanto, iniciar o mecanismo como um serviço requer que você tenha alguns privilégios de acesso ao servidor. E se o seu provedor de hospedagem não oferecer suporte ao Elasticsearch pronto para uso, você precisará instalar alguns pacotes.
A conclusão é que este produto é uma ótima opção se você deseja uma solução de pesquisa sólida. (Nota:Você pode precisar de um VPS ou servidor dedicado, pois os requisitos de hardware são bastante exigentes.)
Esfinge
Assim como o Elasticsearch, o Sphinx também fornece um produto de pesquisa de texto completo muito sólido:o Craigslist atende a mais de 300.000.000 de consultas por dia com ele. Sphinx não fornece uma interface RESTful nativa. Ele é implementado em C, com uma pegada de hardware menor que o Elasticsearch (que é implementado em Java e pode ser executado em qualquer SO com um jvm). Você também precisará de acesso root ao servidor com alguma RAM/CPU dedicada para executar o Sphinx corretamente.
Pesquisa de texto completo do MySQL
Historicamente, pesquisas de texto completo eram suportadas nos mecanismos MyISAM. Após a versão 5.6, o MySQL também suportava pesquisas de texto completo nos mecanismos de armazenamento InnoDB. Esta foi uma ótima notícia, pois permite que os desenvolvedores se beneficiem da integridade referencial do InnoDB, capacidade de realizar transações e bloqueios de linha.
Existem basicamente duas abordagens para pesquisas de texto completo no MySQL:linguagem natural e modo booleano. (Uma terceira opção aumenta a pesquisa em linguagem natural com uma segunda consulta de expansão.)
A principal diferença entre os modos natural e booleano é que o booleano permite determinados operadores como parte da pesquisa. Por exemplo, operadores booleanos podem ser usados se uma palavra tiver maior relevância do que outras na consulta ou se uma palavra específica deve estar presente nos resultados, etc. MySQL durante a pesquisa.
Tomando as Decisões
O melhor ajuste para o nosso problema foi usar pesquisas de texto completo do InnoDb no modo booleano. Por quê?
- Tivemos pouco tempo para implementar a função de pesquisa.
- Neste momento, não tínhamos big data para processar nem uma carga massiva para exigir algo como Elasticsearch ou Sphinx.
- Usamos hospedagem compartilhada que não suporta Elasticsearch ou Sphinx e o hardware era bastante limitado neste estágio.
- Embora desejássemos a derivação de palavras em nossa função de pesquisa, não era um problema:poderíamos implementá-la (dentro de restrições) por meio de alguma codificação PHP simples e desnormalização de dados
- As pesquisas de texto completo no modo booleano podem pesquisar palavras com curingas (para a palavra derivada) e classificar os resultados com base na relevância.
Pesquisas de texto completo no modo booleano
Como mencionado anteriormente, a pesquisa em linguagem natural é a abordagem mais simples:basta pesquisar uma frase ou palavra nas colunas onde você definiu um índice de texto completo e obterá resultados classificados por relevância.
No Modelo Vertabelo Normalizado
Vamos ver como uma pesquisa simples funcionaria. Vamos criar uma tabela de amostra primeiro:
-- Criado por Vertabelo (https://vertabelo.com)-- Data da última modificação:2016-04-25 15:01:22.153-- tables-- Tabela:artistasCREATE TABLE artistas ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artistas_pk PRIMARY KEY (id)) ENGINE InnoDB;CREATE FULLTEXT INDEX artistas_idx_1 ON artistas (nome);-- Fim do arquivo.
No modo de linguagem natural
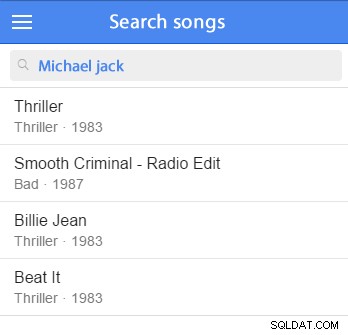
Você pode inserir alguns dados de amostra e começar a testar. (Seria bom adicioná-lo ao seu conjunto de dados de amostra.) Por exemplo, tentaremos pesquisar por Michael Jackson:
SELECT *FROM artistWHERE MATCH (artists.name) AGAINST ('Michael Jackson' NO MODO DE IDIOMA NATURAL) Esta consulta encontrará registros que correspondem aos termos de pesquisa e classificará os registros correspondentes por relevância; quanto melhor a correspondência, mais relevante ela é e mais alto o resultado aparecerá na lista.
No modo booleano
Podemos realizar a mesma pesquisa no modo booleano. Se não aplicarmos nenhum operador à nossa consulta, a única diferença será que os resultados não são classificados por relevância:
SELECT *FROM artistWHERE MATCH (artists.name) AGAINST ('Michael Jackson' NO MODO BOOLEAN) O operador curinga no modo booleano
Como queremos pesquisar palavras derivadas e parciais, precisaremos do operador curinga (*). Este operador pode ser usado em buscas em modo booleano, por isso escolhemos esse modo.
Então, vamos liberar o poder da pesquisa booleana e tentar pesquisar parte do nome do artista. Usaremos o operador curinga para corresponder a qualquer artista cujo nome comece com 'Mich':
SELECT *FROM artistWHERE MATCH (name) AGAINST ('Mich*' NO MODO BOOLEAN) Classificando por relevância no modo booleano
Agora vamos ver a relevância calculada para a pesquisa. Isso nos ajudará a entender a classificação que faremos mais tarde com o Cake:
SELECT *, MATCH (nome) AGAINST ('mich*' NO MODO BOOLEAN) AS rankFROM artistWHERE MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE)ORDER BY rank DESC Esta consulta recupera as correspondências de pesquisa e o valor de relevância que o MySQL calcula para cada registro. O otimizador de mecanismo detectará que estamos selecionando a relevância, portanto, não se incomodará em recalcular a classificação.
Seleção de palavras na pesquisa de texto completo
Quando incorporamos a derivação de palavras em uma pesquisa, a pesquisa se torna mais amigável. Mesmo que o resultado não seja uma palavra em si, os algoritmos tentam gerar a mesma raiz para palavras derivadas. Por exemplo, o radical “argu” não é uma palavra em inglês, mas pode ser usado como radical para “argue”, “argud”, “argues”, “arguing”, “Argus” e outras palavras.
A derivação melhora os resultados, pois o usuário pode inserir uma palavra que não tem correspondência exata, mas sua “raiz” sim. Embora o lematizador PHP ou o lematizador Python do Snowball possam ser uma opção (se você tiver acesso SSH root ao seu servidor), usaremos a classe PorterStemmer.php.
Esta classe implementa o algoritmo proposto por Martin Porter para derivar palavras em inglês. Conforme declarado pelo autor em seu site, é gratuito para qualquer finalidade. Basta soltar o arquivo dentro do diretório Vendors dentro do CakePHP, incluir a biblioteca em seu modelo e chamar o método estático para originar uma palavra:
//incluir a biblioteca (deve ser chamada PorterStemmer.php) dentro da pasta Vendors do CakePHP App::import('Vendor', 'PorterStemmer'); //stem uma palavra (as palavras devem ser derivadas uma a uma)echo PorterStemmer::Stem(‘stemming’); //saída será 'stem' Nosso objetivo é tornar a pesquisa rápida e eficiente e poder classificar os resultados pela relevância do texto completo. Para fazer isso, precisaremos empregar a derivação de palavras de duas maneiras:
- As palavras inseridas pelo usuário
- Dados relacionados à música (que armazenaremos em colunas e classificaremos os resultados com base na relevância)
O primeiro tipo de radicalização de palavras pode ser realizado assim:
App::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ /remover caracteres indesejados$words =explodir(" ", trim($search));$stemmedSearch ="";$unstemmedSearch ="";foreach ($words as $word) { $stemmedSearch .=PorterStemmer::Stem($ palavra) . "* "; // adicionamos o curinga após cada palavra $unstemmedSearch =$word . "* ";//para pesquisar a coluna do artista que não é stemmed}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") { //caso contrário o mySql irá reclamar, pois você não pode usar o curinga sozinho $stemmedSearch =""; $unstemmedSearch ="";} Criamos duas strings:uma para pesquisar o nome do artista (sem derivação) e outra para pesquisar nas outras colunas derivadas. Isso nos ajudará mais tarde a construir nosso 'contra' parte da consulta de texto completo. Agora vamos ver como podemos determinar e classificar os dados da música.
Desnormalizando dados de música
Nossos critérios de classificação serão baseados na correspondência do artista da música (sem derivação) primeiro. Em seguida, virá o nome da música, álbum e categorias relacionadas. Stemming será usado em todos os critérios de pesquisa secundários.
Para ilustrar isso, suponha que eu procure por 'nirvana' e haja uma música chamada 'Nirvana Games' de 'XYZ' e outra música chamada 'Polly' do artista 'Nirvana'. Os resultados devem listar 'Polly' primeiro, pois a correspondência no nome do artista é mais importante do que a correspondência no nome da música (com base nos critérios).
Para fazer isso, adicionei 4 campos nas
songs tabela, um para cada um dos critérios de busca/ordenação que desejamos:ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL AFTER` denorm_trackname`,ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
Nosso modelo de banco de dados completo ficaria assim:
Sempre que você salvar uma música usando add/edit no CakePHP, você só precisa armazenar o nome do artista na coluna denorm_artist sem derrotá-lo. Em seguida, adicione o nome da faixa derivada no denorm_trackname campo (semelhante ao que fizemos no texto pesquisado) e salve o nome do álbum derivado no denorm_album coluna. Por fim, armazene a categoria derivada definida para a música em denorm_categories campo, concatenando as palavras e adicionando um espaço entre cada nome de categoria derivada.
Pesquisa de texto completo e classificação por relevância no CakePHP
Continuando com o exemplo de busca por ‘Nirvana’, vamos ver o que uma consulta semelhante a esta pode alcançar:
SELECT trackname, MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) como rank1, MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) como rank2, MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) como rank3, MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) como rank4 FROM song WHERE MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR MATCH(denorm_trackname) AGAINST ('Nirvana* ' NO BOOLEAN MODE) OU MATCH(denorm_album) AGAINST ('Nirvana*' NO BOOLEAN MODE) OU MATCH(denorm_categories) AGAINST ('Nirvana*' NO BOOLEAN MODE) ORDER BY rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC
Teríamos a seguinte saída:
| nome da faixa | classificação1 | rank2 | classificação3 | classificação 4 |
| Polly | 0,0906190574169159 | 0 | 0 | 0 |
| jogos do nirvana | 0 | 0,0906190574169159 | 0 | 0 |
Para fazer isso no CakePHP, o find O método deve ser chamado usando uma combinação de parâmetros 'campos', 'condições' e 'ordem'. Continuando com o antigo código de exemplo PHP:
//dentro do arquivo de modelo Song.php $fields =array( "Song.trackname", "MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} NO MODO BOOLEAN) como `rank1`", "MATCH(Song. denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) como `rank2`", "MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) como `rank3`", "MATCH(Song.denorm_categories) AGAINST ( {$stemmedSearch} IN BOOLEAN MODE) as `rank4`" );$order ="`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";$conditions =array( "OU" => array( "MATCH(Song.denorm_artist) CONTRA ({$unstemmedSearch} NO MODO BOOLEAN)", "MATCH(Song.denorm_trackname) CONTRA ({$stemmedSearch} IN BOOLEAN MODE)", "MATCH(Song. denorm_album) AGAINST ({$stemmedSearch} NO MODO BOOLEAN)", "MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)" );$results =$this->find (‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order); $resultados será a matriz de músicas classificadas com os critérios que definimos anteriormente.
Essa solução pode ser usada para gerar pesquisas significativas para o usuário – sem exigir muito tempo dos desenvolvedores ou adicionar grande complexidade ao código.
Tornando as pesquisas do CakePHP ainda melhores
Vale ressaltar que “apimentar” as colunas desnormalizadas com mais dados pode levar a melhores resultados.
Por "spicing" quero dizer que você pode incluir, nas colunas desnormalizadas, mais dados de colunas adicionais que você considera úteis com o objetivo de tornar os resultados mais relevantes, por exemplo, se você soubesse que o país de um artista poderia figurar nos termos de pesquisa, você poderia adicionar o país junto com o nome do artista no
denorm_artist coluna. Isso melhoraria a qualidade dos resultados da pesquisa. Pela minha experiência (dependendo dos dados reais que você usa e das colunas que você desnormaliza), os resultados mais altos tendem a ser realmente precisos. Isso é ótimo para aplicativos móveis, pois rolar uma lista longa pode ser frustrante para o usuário.
Finalmente, se você precisar obter mais dados das tabelas às quais a música se relaciona, você sempre pode fazer uma junção e obter o artista, categorias, álbuns, comentários da música, etc. sugiro adicionar o plug-in EagerLoader para realizar as junções com eficiência.
Se você tiver sua própria abordagem para implementar a pesquisa de texto completo, compartilhe-a nos comentários abaixo. Todos podemos aprender com a experiência uns dos outros.