Isso também não é uma boa fragmentação
No mês passado, escrevi sobre fragmentação inesperada de índice clusterizado, então, desta vez, gostaria de discutir algumas das coisas que você pode fazer para evitar que a fragmentação de índice aconteça. Presumo que você tenha lido a postagem anterior e esteja familiarizado com os termos que defini lá, e ao longo do restante deste artigo, quando digo 'fragmentação' estou me referindo à fragmentação lógica e aos problemas de baixa densidade de página.
Escolha uma boa chave de cluster
A estrutura de dados mais cara para operar para remover a fragmentação é o índice clusterizado de uma tabela, porque é a maior estrutura, pois contém todos os dados da tabela. De uma perspectiva de fragmentação, faz sentido escolher uma chave de cluster que corresponda ao padrão de inserção da tabela, portanto, não há possibilidade de uma inserção ocorrer em uma página onde não há espaço e, portanto, causar uma divisão de página e introduzir fragmentação.
O que constitui a melhor chave de cluster para qualquer tabela é uma questão de muito debate, mas em geral você não errará se sua chave de cluster tiver as seguintes propriedades simples:
- Restringir (ou seja, o menor número possível de colunas)
- Estático (ou seja, você nunca o atualiza)
- Único
- Sempre crescente
É a propriedade cada vez maior que é a mais importante para a prevenção de fragmentação, pois evita inserções aleatórias que podem causar divisões de página em páginas já cheias. Exemplos de tal escolha de chave são as colunas int identity e bigint identity, ou mesmo um GUID sequencial da função NEWSEQUENTIALID().
Com esses tipos de chaves, as novas linhas terão um valor de chave garantido como superior a todos os outros na tabela e, portanto, o ponto de inserção da nova linha estará no final da página mais à direita na estrutura do índice clusterizado. Eventualmente, as novas linhas preencherão essa página e outra página será adicionada ao lado direito do índice, mas sem ocorrer nenhuma divisão de página prejudicial.
Agora, se você tiver uma chave de índice clusterizado que não está sempre aumentando, pode ser um procedimento muito complexo e intragável alterá-la para uma sempre crescente, então não se preocupe - em vez disso, você pode usar um fator de preenchimento como discuto abaixo de.
A propósito, para uma visão muito mais profunda sobre como escolher uma chave de cluster e todas as suas ramificações, confira a categoria de blog Chave de cluster da Kimberly (leia de baixo para cima).
Não atualizar colunas de chave de índice
Sempre que uma coluna chave é atualizada, não é apenas uma simples atualização no local, embora muitos lugares online e em livros digam que é (eles estão errados). Uma coluna de chave não pode ser atualizada no local, pois o novo valor de chave significaria que a linha está na ordem de chave errada para o índice. Em vez disso, uma atualização de coluna de chave é traduzida em uma exclusão de linha completa mais uma inserção de linha completa com o novo valor de chave. Se a página onde a nova linha será inserida não tiver espaço suficiente, ocorrerá uma divisão de página, causando fragmentação.
Evitar atualizações de colunas de chave deve ser fácil de fazer para o índice clusterizado, pois é um design ruim que exige a atualização da chave de cluster de uma linha da tabela. No entanto, para índices não clusterizados, é inevitável se as atualizações na tabela envolverem colunas nas quais há um índice não clusterizado. Para esses casos, você precisará usar um fator de preenchimento.
Não atualizar colunas de comprimento variável
Este é mais fácil dizer do que fazer. Se você precisar usar colunas de comprimento variável e for possível que elas sejam atualizadas, é possível que elas cresçam e exija mais espaço para a linha atualizada, levando a uma divisão de página se a página já estiver cheia.
Há algumas coisas que você pode fazer para evitar a fragmentação neste caso:
- Usar um fator de preenchimento
- Use uma coluna de comprimento fixo, se a sobrecarga de todos os bytes de preenchimento extras for um problema menor do que a fragmentação ou o uso de um fator de preenchimento
- Use um valor de espaço reservado para 'reservar' espaço para a coluna - esse é um truque que você pode usar se o aplicativo inserir uma nova linha e depois voltar para preencher alguns detalhes, causando expansão de coluna de comprimento variável l>
- Execute uma exclusão e uma inserção em vez de uma atualização
Use um fator de preenchimento
Como você pode ver, muitas das maneiras de evitar a fragmentação são desagradáveis, pois envolvem alterações no aplicativo ou no esquema e, portanto, usar um fator de preenchimento é uma maneira fácil de mitigar a fragmentação.
Um fator de preenchimento de índice é uma configuração para o índice que especifica quanto espaço vazio deixar em cada página de nível de folha quando o índice é criado, reconstruído ou reorganizado. A ideia é que haja espaço livre suficiente na página para permitir inserções aleatórias ou crescimentos de linha (de uma tag de versão sendo adicionada ou colunas de comprimento variável atualizadas) sem que a página seja preenchida e exija uma divisão de página. No entanto, eventualmente a página será preenchida e, portanto, periodicamente, o espaço livre precisa ser atualizado pela reconstrução ou reorganização do índice (geralmente chamado de manutenção do índice). O truque está em encontrar o fator de preenchimento correto a ser usado, juntamente com a periodicidade correta da manutenção do índice.
Você pode ler mais sobre como definir um fator de preenchimento no MSDN aqui. Não caia na armadilha de definir o fator de preenchimento para a instância inteira (usando sp_configure), pois isso significa que todos os índices serão reconstruídos ou reorganizados usando esse valor de fator de preenchimento, mesmo aqueles índices que não têm problemas de fragmentação. Você não quer que seus grandes índices clusterizados, com boas chaves sempre crescentes, tenham 30% de seu espaço em nível de folha desperdiçado preparando-se para inserções aleatórias que nunca acontecerão. É muito melhor descobrir quais índices são realmente afetados pela fragmentação e definir apenas um fator de preenchimento para eles.
Não há resposta certa ou fórmula mágica que eu possa lhe dar para isso. A prática geralmente aceita é colocar um fator de preenchimento de 70 (ou seja, deixar 30% de espaço livre) em vigor para os índices em que a fragmentação é um problema, monitorar a rapidez com que a fragmentação ocorre e, em seguida, modificar o fator de preenchimento ou a frequência de manutenção do índice (ou ambos).
Sim, isso significa que você está deliberadamente desperdiçando espaço nos índices para evitar a fragmentação, mas essa é uma boa compensação, considerando o custo das divisões de página e o quanto a fragmentação pode ser prejudicial para o desempenho. E sim, apesar do que alguns possam dizer, isso ainda é importante mesmo se você estiver usando SSDs.
Resumo
Existem algumas coisas simples que você pode fazer para evitar que a fragmentação aconteça, mas assim que você entrar em índices não clusterizados, ou usar o isolamento de instantâneo ou secundários legíveis, a fragmentação eleva sua cabeça feia e você precisa tentar evitá-la.
Agora, não pense que você deve definir um fator de preenchimento de 70 em todas as suas instâncias – você precisa escolher e configurá-los com cuidado, como descrevi acima.
E não se esqueça do SQL Sentry Fragmentation Manager, que você pode usar (como um complemento do Performance Advisor) para ajudar a descobrir onde estão os problemas de fragmentação e resolvê-los. Por exemplo, na guia Índices, você pode classificar facilmente seus índices primeiro pela fragmentação mais alta (e, se desejar, aplique um filtro à coluna de contagem de linhas para ignorar suas tabelas menores):
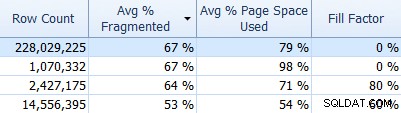
E, em seguida, veja se esses índices estão usando o fator de preenchimento padrão (0%) ou talvez um fator de preenchimento não padrão, que pode não ser uma boa correspondência para seus dados e padrões DML. Vou deixar você adivinhar quais na captura de tela acima eu estaria mais interessado em investigar. A implementação de fatores de preenchimento de índice mais apropriados é a maneira mais simples de resolver quaisquer problemas encontrados.