Com a Recuperação de Desastres, nosso objetivo é configurar sistemas para lidar com qualquer coisa que possa dar errado com nosso banco de dados. O que acontece se o banco de dados travar? E se um desenvolvedor acidentalmente truncar uma tabela? E se descobrirmos que alguns dados foram excluídos na semana passada, mas não notamos até hoje? Essas coisas acontecem, e ter um plano e um sistema sólidos em vigor fará com que o DBA pareça um herói quando o coração de todos os outros já parou quando um desastre mostra sua cabeça feia.
Qualquer banco de dados que tenha algum tipo de valor deve ter uma maneira de implementar uma ou mais opções de recuperação de desastres. O PostgreSQL tem um sistema de replicação muito sólido embutido e é flexível o suficiente para ser configurado em muitas configurações para auxiliar na recuperação de desastres, caso algo dê errado. Vamos nos concentrar em cenários como o questionado acima, como configurar nossas opções de recuperação de desastres e os benefícios de cada solução.
Alta disponibilidade
Com a replicação de streaming no PostgreSQL, a alta disponibilidade é simples de configurar e manter. O objetivo é fornecer um site de failover que possa ser promovido a mestre se o banco de dados principal ficar inativo por qualquer motivo, como falha de hardware, falha de software ou até mesmo interrupção da rede. Hospedar uma réplica em outro host é ótimo, mas hospedá-la em outro data center é ainda melhor.
Para obter detalhes sobre como configurar a replicação de streaming, o Variousnines tem um mergulho profundo detalhado disponível aqui. A documentação oficial de replicação de streaming do PostgreSQL tem informações detalhadas sobre o protocolo de replicação de streaming e como tudo funciona.
Uma configuração padrão será assim, um banco de dados mestre aceitando conexões de leitura/gravação, com um banco de dados de réplica recebendo todas as atividades do WAL quase em tempo real, reproduzindo todas as atividades de alteração de dados localmente.
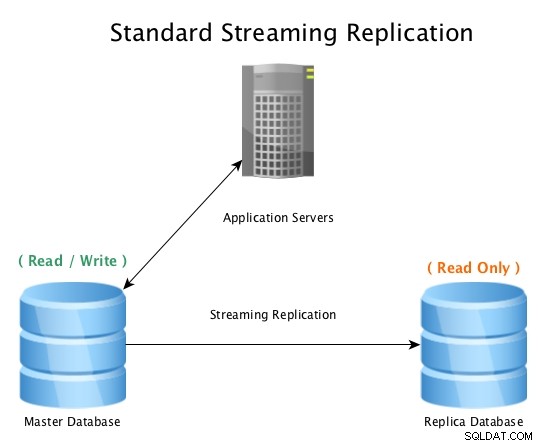 Replicação de streaming padrão com PostgreSQL
Replicação de streaming padrão com PostgreSQL Quando o banco de dados mestre se torna inutilizável, um procedimento de failover é iniciado para colocá-lo offline e promover o banco de dados de réplica para mestre, apontando todas as conexões para o host recém-promovido. Isso pode ser feito reconfigurando um balanceador de carga, configuração de aplicativo, aliases de IP ou outras maneiras inteligentes de redirecionar o tráfego.
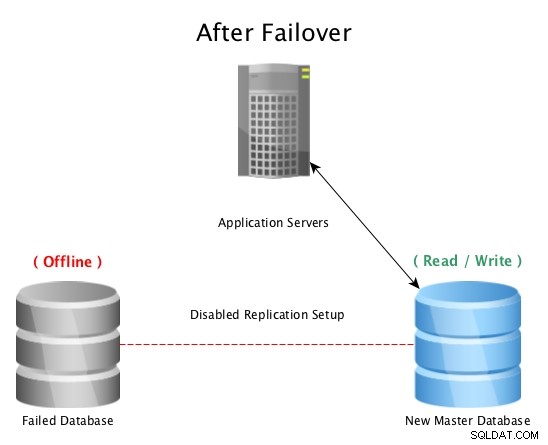 Após um failover com PostgreSQL Streaming Replication
Após um failover com PostgreSQL Streaming Replication Quando um desastre atinge um banco de dados mestre (como uma falha de disco rígido, falta de energia ou qualquer coisa que impeça o mestre de funcionar conforme o esperado), o failover para um hot standby é a maneira mais rápida de permanecer on-line atendendo consultas a aplicativos ou clientes sem problemas sérios tempo de inatividade. A corrida começa para corrigir o host de banco de dados com falha ou colocar uma nova réplica online para manter a rede de segurança de ter um standby pronto para ser usado. Ter várias esperas garantirá que a janela após uma falha desastrosa também esteja pronta para uma falha secundária, por mais improvável que pareça.
Observação:ao fazer failover para uma réplica de streaming, ela continuará de onde o mestre anterior parou, o que ajuda a manter o banco de dados online, mas não a recuperar dados perdidos acidentalmente.
Recuperação pontual
Outra opção de recuperação de desastres é a recuperação pontual (PITR). Com o PITR, uma cópia do banco de dados pode ser trazida de volta a qualquer momento que desejarmos, desde que tenhamos um backup de base anterior a esse momento e todos os segmentos WAL necessários até esse momento.
Uma opção Point In Time Recovery não é tão rapidamente colocada online quanto um Hot Standby, no entanto, o principal benefício é poder recuperar um instantâneo de banco de dados antes de um grande evento, como uma tabela excluída, dados incorretos sendo inseridos ou até mesmo corrupção de dados inexplicável . Qualquer coisa que destrua os dados de tal forma que gostaríamos de obter uma cópia antes dessa destruição, o PITR salva o dia.
O Point in Time Recovery funciona criando instantâneos periódicos do banco de dados, geralmente pelo uso do programa pg_basebackup, e mantendo cópias arquivadas de todos os arquivos WAL gerados pelo mestre
Configuração de recuperação pontual
A instalação requer algumas opções de configuração definidas no mestre, algumas das quais são boas para usar com valores padrão na versão mais recente, PostgreSQL 11. Neste exemplo, copiaremos o arquivo de 16 MB diretamente para nosso host PITR remoto usando rsync , e compactando-os do outro lado com um cron job.
Arquivamento WAL
Mestre postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'OBSERVAÇÃO: A configuração archive_command pode ser muitas coisas, o objetivo geral é enviar todos os arquivos WAL arquivados para outro host para fins de segurança. Se perdermos algum arquivo WAL, o PITR após o arquivo WAL perdido se tornará impossível. Deixe sua criatividade de programação enlouquecer, mas certifique-se de que seja confiável.
[Opcional] Compacte os arquivos WAL arquivados:
Cada configuração varia um pouco, mas, a menos que o banco de dados em questão seja muito leve em atualizações de dados, o acúmulo de arquivos de 16 MB preencherá o espaço da unidade rapidamente. Um script de compactação fácil, configurado por meio do cron, pode ser parecido com o abaixo.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]OBSERVAÇÃO: Durante qualquer método de recuperação, todos os arquivos compactados precisarão ser descompactados posteriormente. Alguns administradores optam por compactar apenas os arquivos depois de X dias, mantendo o espaço geral baixo, mas também mantendo os arquivos WAL mais recentes prontos para recuperação sem trabalho extra. Escolha a melhor opção para os bancos de dados em questão para maximizar sua velocidade de recuperação.
Backups básicos
Um dos principais componentes de um backup PITR é o backup básico e a frequência dos backups básicos. Estes podem ser de hora em hora, diários, semanais, mensais, mas escolha a melhor opção com base nas necessidades de recuperação, bem como no tráfego da rotatividade de dados do banco de dados. Se tivermos backups semanais todos os domingos e precisarmos recuperar até sábado à tarde, colocamos online o backup básico do domingo anterior com todos os arquivos WAL entre esse backup e o sábado à tarde. Se esse processo de recuperação demorar 10 horas para ser processado, isso provavelmente é indesejavelmente longo demais, os backups de base diários reduzirão esse tempo de recuperação, pois o backup de base seria dessa manhã, mas também aumentará a quantidade de trabalho no host para o backup de base em si.
Se a recuperação de uma semana de arquivos WAL levar apenas alguns minutos, porque o banco de dados apresenta baixa rotatividade, os backups semanais são bons. Os mesmos dados existirão no final, mas a rapidez com que você consegue acessá-los é a chave.
Em nosso exemplo, configuraremos um backup básico semanal e, como estamos usando a replicação de streaming para alta disponibilidade, além de reduzir a carga no mestre, criaremos o backup básico fora do banco de dados de réplica.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zOBSERVAÇÃO: O comando pg_basebackup assume que este host está configurado para acesso sem senha para 'replicação' do usuário no mestre, o que pode ser feito por 'trust' em pg_hba para este host de backup PITR, senha no arquivo .pgpass ou outras formas mais seguras . Lembre-se da segurança ao configurar backups.
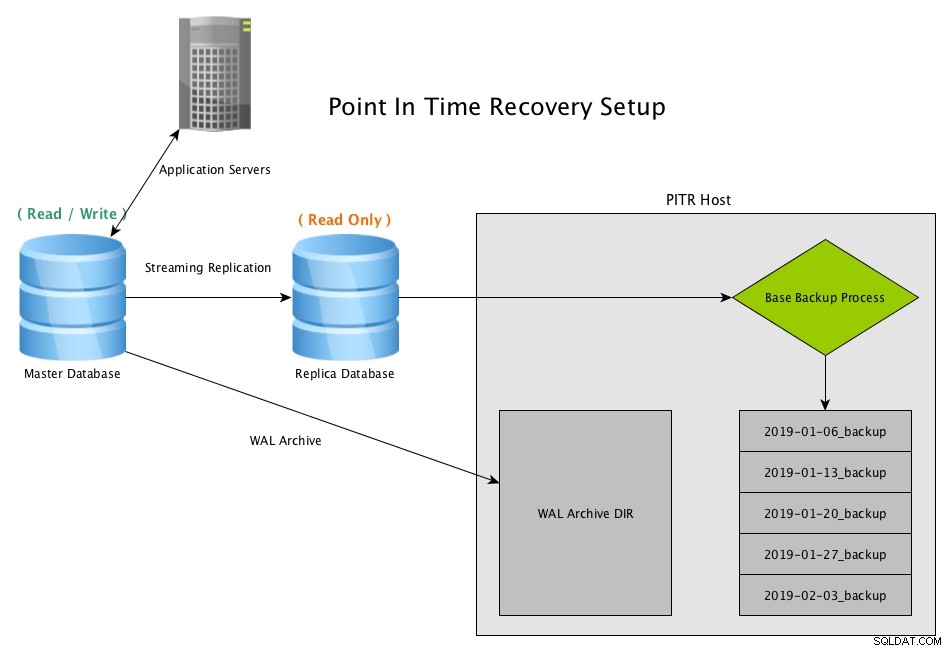 Point In Time Recovery (PITR) de uma réplica de streaming com PostgreSQLBaixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba mais o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Point In Time Recovery (PITR) de uma réplica de streaming com PostgreSQLBaixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba mais o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper Cenário de recuperação de PITR
Configurar a Recuperação Point In Time é apenas parte do trabalho, ter que recuperar dados é a outra parte. Com boa sorte, isso pode nunca acontecer, no entanto, é altamente recomendável fazer periodicamente uma restauração de um backup do PITR para validar se o sistema funciona e para garantir que o processo seja conhecido / scriptado corretamente.
Em nosso cenário de teste, escolheremos um ponto no tempo para recuperar e iniciaremos o processo de recuperação. Por exemplo:sexta-feira de manhã, um desenvolvedor envia uma nova alteração de código para produção sem passar por uma revisão de código e destrói vários dados importantes do cliente. Como nosso Hot Standby está sempre sincronizado com o mestre, fazer failover para ele não resolveria nada, pois seriam os mesmos dados. Backups PITR é o que nos salvará.
O push de código foi às 11h, então precisamos restaurar o banco de dados para um pouco antes desse horário, 10h59, decidimos, e felizmente fazemos backups diários para que tenhamos um backup a partir da meia-noite desta manhã. Como não sabemos o que tudo foi destruído, também decidimos fazer uma restauração completa desse banco de dados em nosso host PITR e colocá-lo online como o mestre, pois ele possui as mesmas especificações de hardware do mestre, caso isso cenário aconteceu.
Desligar o Mestre
Como decidimos restaurar totalmente de um backup e promovê-lo para mestre, não há necessidade de mantê-lo online. Nós o fechamos, mas o mantemos por perto caso precisemos pegar alguma coisa dele mais tarde, apenas no caso.
Configurar o backup básico para recuperação
Em seguida, em nosso host PITR, buscamos nosso backup de base mais recente de antes do evento, que é o backup '2018-12-21_backup'.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Com isso, o backup base, bem como os arquivos WAL fornecidos pelo pg_basebackup estão prontos para serem executados, se o colocarmos online agora, ele se recuperará até o ponto em que o backup ocorreu, mas queremos recuperar todas as transações WAL entre meia-noite e 11h59, então configuramos nosso arquivo recovery.conf.
Criar recovery.conf
Como esse backup realmente veio de uma réplica de streaming, provavelmente já existe um arquivo recovery.conf com configurações de réplica. Vamos sobrescrevê-lo com novas configurações. Uma lista de informações detalhadas para todas as diferentes opções está disponível na documentação do PostgreSQL aqui.
Tomando cuidado com os arquivos WAL, o comando restore copiará os arquivos compactados necessários para o diretório de restauração, descompactá-los e, em seguida, mover para onde o PostgreSQL precisa deles para recuperação. Os arquivos WAL originais permanecerão onde estão, caso sejam necessários por qualquer outro motivo.
Novo recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Iniciar o processo de recuperação
Agora que tudo está configurado, iniciaremos o processo de recuperação. Quando isso acontece, é uma boa ideia seguir o log do banco de dados para garantir que ele esteja restaurando conforme o esperado.
Iniciar o banco de dados:
pg_ctl -D /var/lib/pgsql/11/data startSeguir os logs:
Haverá muitas entradas de log mostrando que o banco de dados está se recuperando de arquivos compactados e, em um determinado ponto, ele mostrará uma linha dizendo “recuperação parando antes da confirmação da transação …”
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07Neste ponto, o processo de recuperação ingeriu todos os arquivos WAL, mas também precisa ser revisto antes de ficar online como mestre. Neste exemplo, o log observa que a próxima transação após o horário de destino de recuperação de 11:59:00 foi 11:59:01 e não foi recuperada. Para verificar, faça login no banco de dados e dê uma olhada, o banco de dados em execução deve ser um instantâneo exatamente às 11:59.
Quando tudo parece bem, hora de promover a recuperação como mestre.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Agora, o banco de dados está online, recuperado até o ponto que decidimos, e aceitando conexões de leitura/gravação como um nó mestre. Certifique-se de que todos os parâmetros de configuração estejam corretos e prontos para produção.
O banco de dados está online, mas o processo de recuperação ainda não foi concluído! Agora que esse backup do PITR está online como o mestre, uma nova configuração de espera e PITR deve ser configurada, até então esse novo mestre pode estar online e atendendo aplicativos, mas não está seguro de outro desastre até que tudo esteja configurado novamente.
Outros cenários de recuperação pontual
Trazer de volta um backup PITR para um banco de dados inteiro é um caso extremo, mas há outros cenários em que apenas um subconjunto de dados está ausente, corrompido ou danificado. Nesses casos, podemos ser criativos com nossas opções de recuperação. Sem colocar o master offline e substituí-lo por um backup, podemos colocar um backup PITR online no momento exato que queremos em outro host (ou outra porta se o espaço não for um problema) e exportar os dados recuperados do backup diretamente no banco de dados mestre. Isso pode ser usado para recuperar um punhado de linhas, um punhado de tabelas ou qualquer configuração de dados necessária.
Com replicação de streaming e Recuperação Point In Time, o PostgreSQL nos dá grande flexibilidade para garantir que podemos recuperar todos os dados de que precisamos, desde que tenhamos hosts em espera prontos para funcionar como mestre ou backups prontos para recuperação. Uma boa opção de recuperação de desastres pode ser expandida com outras opções de backup, mais nós de réplica, vários sites de backup em diferentes data centers e continentes, pg_dumps periódicos em outra réplica, etc.
Essas opções podem se somar, mas a verdadeira questão é "qual é o valor dos dados e quanto você está disposto a gastar para recuperá-los?". Em muitos casos, a perda dos dados é o fim de um negócio, portanto, boas opções de recuperação de desastres devem ser implementadas para evitar que o pior aconteça.