[Veja um índice de todas as postagens de maus hábitos / práticas recomendadas]
Um dos slides da minha apresentação recorrente de Maus Hábitos e Práticas Recomendadas tem o título "Abuso de
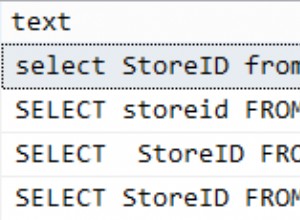
COUNT(*) ." Eu vejo esse abuso um pouco na natureza, e assume várias formas. Quantas linhas na tabela?
Eu costumo ver isso:
SELECT @count = COUNT(*) FROM dbo.tablename;
O SQL Server precisa executar uma verificação de bloqueio em toda a tabela para derivar essa contagem. Isso é caro. Essas informações são armazenadas nas visualizações de catálogo e DMVs, e você pode obtê-las sem toda essa E/S ou bloqueio:
SELECT @count = SUM(p.rows) FROM sys.partitions AS p INNER JOIN sys.tables AS t ON p.[object_id] = t.[object_id] INNER JOIN sys.schemas AS s ON t.[schema_id] = s.[schema_id] WHERE p.index_id IN (0,1) -- heap or clustered index AND t.name = N'tablename' AND s.name = N'dbo';
(Você pode obter as mesmas informações em
sys.dm_db_partition_stats , mas nesse caso altere p.rows para p.row_count (sim consistência!). Na verdade, esta é a mesma visão que sp_spaceused usa para derivar a contagem – e embora seja muito mais fácil digitar do que a consulta acima, recomendo não usá-la apenas para derivar uma contagem por causa de todos os cálculos extras que ela faz – a menos que você queira essa informação também. Observe também que ele usa funções de metadados que não obedecem ao seu nível de isolamento externo, portanto, você pode acabar esperando o bloqueio ao chamar esse procedimento.) Agora, é verdade que essas visualizações não são 100% precisas em microssegundos. A menos que você esteja usando um heap, um resultado mais confiável pode ser obtido no
sys.dm_db_index_physical_stats() coluna record_count (yay consistência novamente!), no entanto, esta função pode ter um impacto no desempenho, ainda pode bloquear e pode ser ainda mais cara do que um SELECT COUNT(*) – tem que fazer as mesmas operações físicas, mas tem que calcular informações adicionais dependendo do mode (como fragmentação, com a qual você não se importa neste caso). O aviso na documentação conta parte da história, relevante se você estiver usando grupos de disponibilidade (e provavelmente afeta o espelhamento de banco de dados de maneira semelhante):Se você consultar sys.dm_db_index_physical_stats em uma instância de servidor que hospeda uma réplica secundária legível AlwaysOn, poderá encontrar um problema de bloqueio de REDO. Isso ocorre porque essa exibição de gerenciamento dinâmico adquire um bloqueio IS na tabela ou exibição de usuário especificada que pode bloquear solicitações por um thread REDO para um bloqueio X nessa tabela ou exibição de usuário.
A documentação também explica por que esse número pode não ser confiável para um heap (e também fornece uma quase passagem para a inconsistência de linhas versus registros):
Para um heap, o número de registros retornados dessa função pode não corresponder ao número de linhas retornadas ao executar um SELECT COUNT(*) no heap. Isso ocorre porque uma linha pode conter vários registros. Por exemplo, em algumas situações de atualização, uma única linha de heap pode ter um registro de encaminhamento e um registro encaminhado como resultado da operação de atualização. Além disso, a maioria das linhas LOB grandes é dividida em vários registros no armazenamento LOB_DATA.
Então, eu me inclinaria para
sys.partitions como forma de otimizar isso, sacrificando um pouco de precisão marginal. - "Mas não posso usar os DMVs; minha contagem precisa ser super precisa!"
Uma contagem "super precisa" na verdade não tem sentido. Vamos considerar que sua única opção para uma contagem "super precisa" é bloquear a tabela inteira e proibir qualquer pessoa de adicionar ou excluir qualquer linha (mas sem impedir leituras compartilhadas), por exemplo:
SELECT @count = COUNT(*) FROM dbo.table_name WITH (TABLOCK); -- not TABLOCKX!
Então, sua consulta está zunindo, varrendo todos os dados, trabalhando em direção a essa contagem "perfeita". Enquanto isso, as solicitações de gravação estão sendo bloqueadas e aguardando. De repente, quando sua contagem precisa é retornada, seus bloqueios na mesa são liberados e todas as solicitações de gravação que estavam enfileiradas e aguardando, começam a disparar todos os tipos de inserções, atualizações e exclusões em sua tabela. Quão "super precisa" é a sua contagem agora? Valeu a pena obter uma contagem "precisa" que já é terrivelmente obsoleta? Se o sistema não estiver ocupado, então isso não é um problema tão grande - mas se o sistema não estiver ocupado, eu argumentaria fortemente que os DMVs serão bastante precisos.
Você poderia ter usado
NOLOCK em vez disso, mas isso significa apenas que os escritores podem alterar os dados enquanto você os lê e leva a outros problemas também (falei sobre isso recentemente). Tudo bem para muitos estádios, mas não se seu objetivo for precisão. Os DMVs estarão bem (ou pelo menos muito mais próximos) em muitos cenários e mais distantes em muito poucos (na verdade, nenhum que eu possa pensar). Por fim, você pode usar o isolamento de instantâneos confirmados de leitura. Kendra Little tem um post fantástico sobre os níveis de isolamento de snapshots, mas vou repetir a lista de advertências que mencionei no meu
NOLOCK artigo:- Os bloqueios Sch-S ainda precisam ser feitos mesmo sob RCSI.
- Os níveis de isolamento de instantâneo usam controle de versão de linha no tempdb, então você realmente precisa testar o impacto lá.
- RCSI não pode usar varreduras de ordem de alocação eficientes; você verá varreduras de intervalo.
- Paul White (@SQL_Kiwi) tem ótimas postagens que você deve ler sobre esses níveis de isolamento:
- Ler o isolamento de instantâneo confirmado
- Modificações de dados no isolamento de instantâneos confirmados de leitura
- O nível de isolamento do INSTANTÂNEO
Além disso, mesmo com RCSI, obter a contagem "precisa" leva tempo (e recursos adicionais no tempdb). No momento em que a operação é concluída, a contagem ainda é precisa? Só se ninguém tiver tocado na mesa nesse meio tempo. Portanto, um dos benefícios do RCSI (os leitores não bloqueiam os escritores) é desperdiçado.
Quantas linhas correspondem a uma cláusula WHERE?
Este é um cenário um pouco diferente – você precisa saber quantas linhas existem para um determinado subconjunto da tabela. Você não pode usar os DMVs para isso, a menos que o
WHERE cláusula corresponde a um índice filtrado ou cobre completamente uma partição exata (ou múltipla). Se o seu
WHERE cláusula é dinâmica, você pode usar RCSI, conforme descrito acima. Se o seu
WHERE cláusula não é dinâmica, você também pode usar RCSI, mas também pode considerar uma destas opções:- Índice filtrado – por exemplo, se você tiver um filtro simples como
is_active = 1oustatus < 5, então você poderia construir um índice como este:CREATE INDEX ix_f ON dbo.table_name(leading_pk_column) WHERE is_active = 1;
Agora, você pode obter contagens bastante precisas dos DMVs, pois haverá entradas representando esse índice (você só precisa identificar o index_id em vez de confiar no heap(0)/índice clusterizado(1)). No entanto, você precisa considerar alguns dos pontos fracos dos índices filtrados. - Visualização indexada - por exemplo, se você costuma contar pedidos por cliente, uma visualização indexada pode ajudar (embora não tome isso como um endosso genérico de que "visualizações indexadas melhoram todas as consultas!"):
CREATE VIEW dbo.view_name WITH SCHEMABINDING AS SELECT customer_id, customer_count = COUNT_BIG(*) FROM dbo.table_name GROUP BY customer_id; GO CREATE UNIQUE CLUSTERED INDEX ix_v ON dbo.view_name(customer_id);
Agora, os dados na visão serão materializados, e a contagem é garantida para ser sincronizada com os dados da tabela (há alguns bugs obscuros onde isso não é verdade, como este comMERGE, mas geralmente isso é confiável). Portanto, agora você pode obter suas contagens por cliente (ou para um conjunto de clientes) consultando a visualização, a um custo de consulta muito menor (1 ou 2 leituras):
SELECT customer_count FROM dbo.view_name WHERE customer_id = <x>;
Mas não existe almoço grátis . Você precisa considerar a sobrecarga de manter uma exibição indexada e o impacto que isso terá na parte de gravação de sua carga de trabalho. Se você não executar esse tipo de consulta com muita frequência, é improvável que valha a pena.
Pelo menos uma linha corresponde a uma cláusula WHERE?
Essa também é uma pergunta um pouco diferente. Mas muitas vezes vejo isso:
IF (SELECT COUNT(*) FROM dbo.table_name WHERE <some clause>) > 0 -- or = 0 for not exists
Como você obviamente não se importa com a contagem real, você só se importa se pelo menos uma linha existir, eu realmente acho que você deve alterá-la para o seguinte:
IF EXISTS (SELECT 1 FROM dbo.table_name WHERE <some clause>)
Isso pelo menos tem uma chance de curto-circuito antes que o final da tabela seja alcançado e quase sempre superará o
COUNT variação (embora existam alguns casos em que o SQL Server é inteligente o suficiente para converter IF (SELECT COUNT...) > 0 para um IF EXISTS() mais simples ). No pior cenário absoluto, onde nenhuma linha é encontrada (ou a primeira linha é encontrada na última página da varredura), o desempenho será o mesmo.[Veja um índice de todos os maus hábitos / postagens de práticas recomendadas]