A estratégia geral que o mecanismo de banco de dados SQL Server usa para manter uma exibição indexada sincronizada com suas tabelas base – que descrevi com mais detalhes em meu último post – é realizar manutenção incremental da exibição sempre que ocorrer uma operação de alteração de dados em uma das tabelas referenciadas na exibição. Em linhas gerais, a ideia é:
- Coletar informações sobre as alterações da tabela base
- Aplicar as projeções, filtros e junções definidos na visualização
- Agregue as alterações por chave clusterizada de visualização indexada
- Decida se cada alteração deve resultar em uma inserção, atualização ou exclusão na visualização
- Calcule os valores a serem alterados, adicionados ou removidos na visualização
- Aplicar as alterações de visualização
Ou, ainda mais sucintamente (embora com o risco de simplificação grosseira):
- Calcule os efeitos de visualização incremental das modificações de dados originais;
- Aplicar essas alterações à visualização
Geralmente, essa é uma estratégia muito mais eficiente do que reconstruir a exibição inteira após cada alteração de dados subjacente (a opção segura, mas lenta), mas depende da lógica de atualização incremental estar correta para cada alteração de dados concebível, em relação a cada definição de exibição indexada possível.
Como o título sugere, este artigo trata de um caso interessante em que a lógica de atualização incremental é interrompida, resultando em uma exibição indexada corrompida que não corresponde mais aos dados subjacentes. Antes de chegarmos ao bug em si, precisamos revisar rapidamente os agregados escalares e vetoriais.
Agregados escalares e vetoriais
Caso você não esteja familiarizado com o termo, existem dois tipos de agregados. Um agregado associado a uma cláusula GROUP BY (mesmo que o grupo por lista esteja vazio) é conhecido como agregado vetorial . Um agregado sem uma cláusula GROUP BY é conhecido como agregado escalar .
Considerando que um agregado vetorial é garantido para produzir uma única linha de saída para cada grupo presente no conjunto de dados, os agregados escalares são um pouco diferentes. Agregados escalares sempre produzir uma única linha de saída, mesmo se o conjunto de entrada estiver vazio.
Exemplo de agregado de vetor
O exemplo do AdventureWorks a seguir calcula dois agregados de vetor (uma soma e uma contagem) em um conjunto de entrada vazio:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Essas consultas produzem a seguinte saída (sem linhas):

O resultado é o mesmo, se substituirmos a cláusula GROUP BY por um conjunto vazio (requer SQL Server 2008 ou posterior):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Os planos de execução são idênticos em ambos os casos também. Este é o plano de execução para a consulta de contagem:
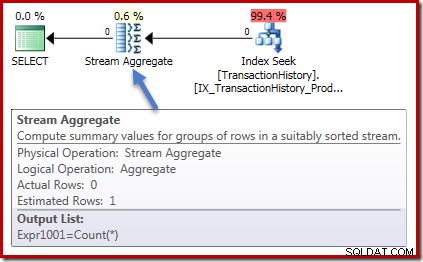
Zero linhas de entrada para o Stream Aggregate e zero linhas de saída. O plano de execução da soma se parece com isso:

Novamente, zero linhas no agregado e zero linhas fora. Todas as coisas boas e simples até agora.
Agregados escalares
Agora veja o que acontece se removermos a cláusula GROUP BY das consultas completamente:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
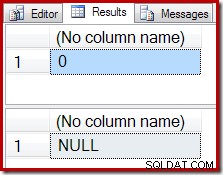
Em vez de um resultado vazio, o agregado COUNT produz um zero e o SUM retorna um NULL:
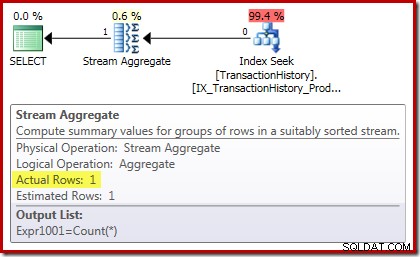
O plano de execução de contagem confirma que zero linhas de entrada produzem uma única linha de saída do Stream Aggregate:
O plano de execução da soma é ainda mais interessante:
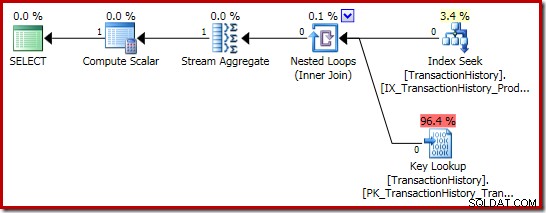
As propriedades Stream Aggregate mostram uma agregação de contagem sendo calculada além da soma que solicitamos:
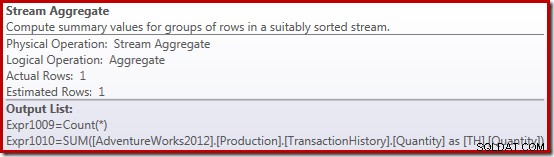
O novo operador Compute Scalar é usado para retornar NULL se a contagem de linhas recebidas pelo Stream Aggregate for zero, caso contrário, retornará a soma dos dados encontrados:
Isso tudo pode parecer um pouco estranho, mas é assim que funciona:
- Um agregado vetorial de zero linhas retorna zero linhas;
- Um agregado escalar sempre produz exatamente uma linha de saída, mesmo para uma entrada vazia;
- A contagem escalar de zero linhas é zero; e
- A soma escalar de zero linhas é NULL (não zero).
O ponto importante para nossos propósitos atuais é que os agregados escalares sempre produzem uma única linha de saída, mesmo que isso signifique criar uma do nada. Além disso, a soma escalar de zero linhas é NULL, não zero.
Esses comportamentos são todos "corretos" a propósito. As coisas são do jeito que são porque o SQL Standard originalmente não definiu o comportamento dos agregados escalares, deixando isso para a implementação. O SQL Server preserva sua implementação original por motivos de compatibilidade com versões anteriores. Os agregados vetoriais sempre tiveram comportamentos bem definidos.
Visualizações Indexadas e Agregação de Vetor
Agora considere uma visualização indexada simples incorporando alguns agregados (vetoriais):
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); As consultas a seguir mostram o conteúdo da tabela base, o resultado da consulta da exibição indexada e o resultado da execução da consulta de exibição na tabela subjacente à exibição:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Os resultados são:
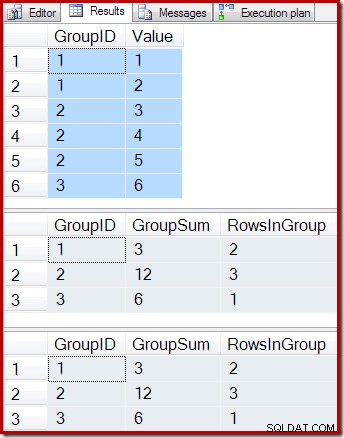
Conforme esperado, a exibição indexada e a consulta subjacente retornam exatamente os mesmos resultados. Os resultados continuarão sincronizados após todas e quaisquer alterações possíveis na tabela base T1. Para nos lembrar de como tudo isso funciona, considere o caso simples de adicionar uma única nova linha à tabela base:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); O plano de execução para esta inserção contém toda a lógica necessária para manter a visualização indexada sincronizada:
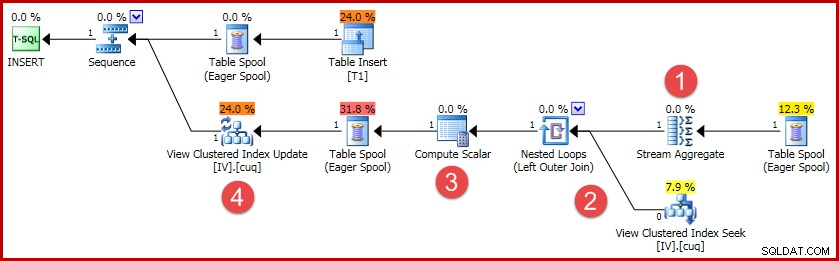
As principais atividades do plano são:
- O Stream Aggregate calcula as alterações por chave de visualização indexada
- A associação externa à visualização vincula o resumo de alterações à linha da visualização de destino, se houver
- O Compute Scalar decide se cada alteração exigirá uma inserção, atualização ou exclusão na exibição e calcula os valores necessários.
- O operador de atualização de visualização executa fisicamente cada alteração no índice clusterizado de visualização.
Existem algumas diferenças de plano para diferentes operações de alteração em relação à tabela base (por exemplo, atualizações e exclusões), mas a ideia geral por trás de manter a exibição sincronizada permanece a mesma:agregue as alterações por chave de exibição, encontre a linha de exibição se ela existir e execute uma combinação de operações de inserção, atualização e exclusão no índice de exibição conforme necessário.
Independentemente das alterações feitas na tabela base neste exemplo, a exibição indexada permanecerá sincronizada corretamente – as consultas NOEXPAND e EXPAND VIEWS acima sempre retornarão o mesmo conjunto de resultados. É assim que as coisas devem sempre funcionar.
Visualizações Indexadas e Agregação Escalar
Agora tente este exemplo, onde a visualização indexada usa agregação escalar (sem cláusula GROUP BY na visualização):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Esta é uma visão indexada perfeitamente legal; nenhum erro é encontrado ao criá-lo. No entanto, há uma pista de que podemos estar fazendo algo um pouco estranho:quando chega a hora de materializar a exibição criando o índice clusterizado exclusivo necessário, não há uma coluna óbvia para escolher como a chave. Normalmente, escolheríamos as colunas de agrupamento da cláusula GROUP BY da visão, é claro.
O script acima escolhe arbitrariamente a coluna NumRows. Essa escolha não é importante. Sinta-se à vontade para criar o índice clusterizado exclusivo como quiser. A visualização sempre conterá exatamente uma linha por causa dos agregados escalares, portanto, não há chance de uma violação de chave exclusiva. Nesse sentido, a escolha da chave de índice de exibição é redundante, mas necessária.
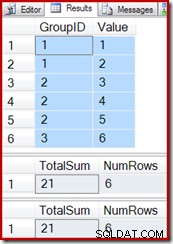
Reutilizando as consultas de teste do exemplo anterior, podemos ver que a visualização indexada funciona corretamente:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
A inserção de uma nova linha na tabela base (como fizemos com a exibição indexada de agregação de vetor) também continua funcionando corretamente:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); O plano de execução é semelhante, mas não exatamente idêntico:
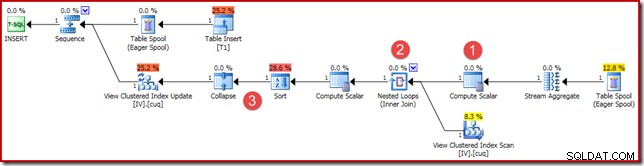
As principais diferenças são:
- Esse novo Compute Scalar está lá pelos mesmos motivos de quando comparamos os resultados de agregação vetorial e escalar anteriormente:ele garante que uma soma NULL seja retornada (em vez de zero) se a agregação operar em um conjunto vazio. Este é o comportamento necessário para uma soma escalar de nenhuma linha.
- A junção externa vista anteriormente foi substituída por uma junção interna. Sempre haverá exatamente uma linha na exibição indexada (devido à agregação escalar), portanto, não há necessidade de uma junção externa para testar se uma linha de exibição corresponde ou não. A única linha presente na exibição sempre representa todo o conjunto de dados. Esta Inner Join não tem predicado, então é tecnicamente uma junção cruzada (para uma tabela com uma única linha garantida).
- Os operadores Classificar e Recolher estão presentes por motivos técnicos abordados em meu artigo anterior sobre manutenção de exibição indexada. Eles não afetam a operação correta da manutenção da visualização indexada aqui.
Na verdade, muitos tipos diferentes de operações de alteração de dados podem ser executados com sucesso na tabela base T1 neste exemplo; os efeitos serão refletidos corretamente na exibição indexada. As seguintes operações de alteração na tabela base podem ser executadas mantendo a exibição indexada correta:
- Excluir linhas existentes
- Atualizar linhas existentes
- Inserir novas linhas
Pode parecer uma lista abrangente, mas não é.
O bug revelado
O problema é bastante sutil e se relaciona (como você deve esperar) aos diferentes comportamentos de agregados vetoriais e escalares. Os pontos principais são que um agregado escalar sempre produzirá uma linha de saída, mesmo que não receba nenhuma linha em sua entrada, e a soma escalar de um conjunto vazio seja NULL, não zero.
Para causar um problema, tudo o que precisamos fazer é não inserir ou excluir nenhuma linha na tabela base.
Essa afirmação não é tão louca quanto pode parecer à primeira vista.
O ponto é que uma consulta de inserção ou exclusão que não afeta nenhuma linha da tabela base ainda atualizará a exibição, porque o Stream Aggregate escalar na parte de manutenção de exibição indexada do plano de consulta produzirá uma linha de saída mesmo quando for apresentada sem entrada. O Compute Scalar que segue o Stream Aggregate também gerará uma soma NULL quando a contagem de linhas for zero.
O script a seguir demonstra o bug em ação:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
A saída desse script é mostrada abaixo:
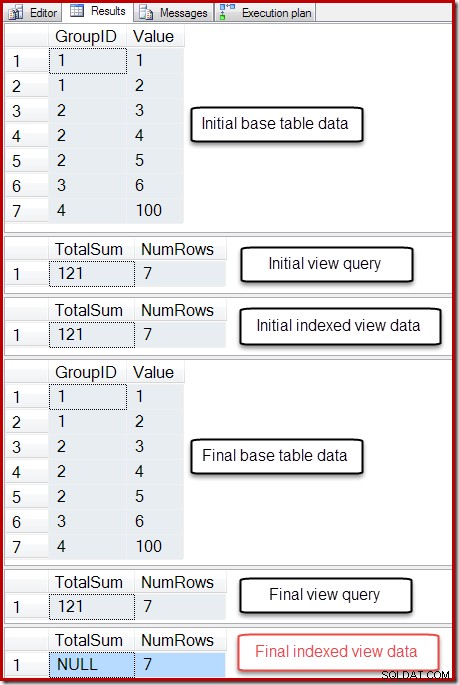
O estado final da coluna Total Sum da exibição indexada não corresponde à consulta de exibição subjacente ou aos dados da tabela base. A soma NULL corrompeu a exibição, o que pode ser confirmado executando DBCC CHECKTABLE (na exibição indexada).
O plano de execução responsável pela corrupção é mostrado abaixo:
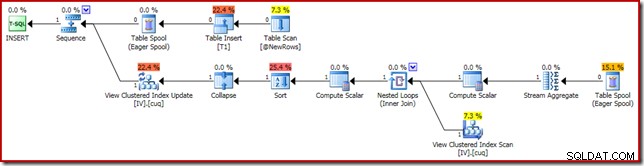
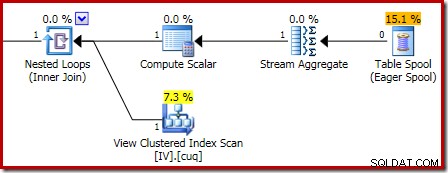
A ampliação mostra a entrada de zero linha para o Stream Aggregate e a saída de uma linha:
Se você quiser tentar o script de corrupção acima com uma exclusão em vez de uma inserção, aqui está um exemplo:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
A exclusão não afeta nenhuma linha da tabela base, mas ainda altera a coluna de soma da exibição indexada para NULL.
Generalizando o Bug
Você provavelmente pode criar qualquer número de consultas de inserção e exclusão da tabela base que não afetem nenhuma linha e causar corrupção na exibição indexada. No entanto, o mesmo problema básico se aplica a uma classe mais ampla de problemas do que apenas inserções e exclusões que não afetam nenhuma linha da tabela base.
É possível, por exemplo, produzir a mesma corrupção usando uma inserção que faz adicionar linhas à tabela base. O ingrediente essencial é que nenhuma linha adicionada deve se qualificar para a visualização . Isso resultará em uma entrada vazia para o Stream Aggregate e a saída de linha NULL causadora de corrupção do seguinte Compute Scalar.
Uma maneira de conseguir isso é incluir uma cláusula WHERE na visão que rejeita algumas das linhas da tabela base:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Dada a nova restrição de IDs de grupo incluídos na exibição, a inserção a seguir adicionará linhas à tabela base, mas ainda corromperá a exibição indexada com uma soma NULL:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; A saída mostra a corrupção de índice agora familiar:
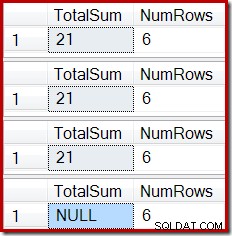
Um efeito semelhante pode ser produzido usando uma visualização que contém uma ou mais junções internas. Desde que as linhas adicionadas à tabela base sejam rejeitadas (por exemplo, falhando ao ingressar), o Stream Aggregate não receberá linhas, o Compute Scalar gerará uma soma NULL e a exibição indexada provavelmente será corrompida.
Considerações finais
Esse problema não ocorre para consultas de atualização (pelo menos até onde eu sei), mas isso parece ser mais por acidente do que por design - o Stream Aggregate problemático ainda está presente em planos de atualização potencialmente vulneráveis, mas o Compute Scalar que gera a soma NULL não é adicionada (ou talvez otimizada). Por favor, deixe-me saber se você conseguir reproduzir o bug usando uma consulta de atualização.
Até que esse bug seja corrigido (ou, talvez, agregações escalares não sejam permitidas em visualizações indexadas), tenha muito cuidado ao usar agregações em uma visualização indexada sem uma cláusula GROUP BY.
Este artigo foi solicitado por um item do Connect enviado por Vladimir Moldovanenko, que teve a gentileza de deixar um comentário em uma postagem antiga do meu blog (que diz respeito a uma corrupção de exibição indexada diferente causada pela declaração MERGE). Vladimir estava usando agregados escalares em uma exibição indexada por razões sólidas, portanto, não se apresse em julgar esse bug como um caso extremo que você nunca encontrará em um ambiente de produção! Meus agradecimentos a Vladimir por me alertar sobre seu item Connect.