PostgreSQL é um projeto incrível e evolui a uma velocidade incrível. Vamos nos concentrar na evolução dos recursos de tolerância a falhas no PostgreSQL em todas as suas versões com uma série de postagens no blog. Este é o terceiro post da série e falaremos sobre problemas de linha do tempo e seus efeitos na tolerância a falhas e confiabilidade do PostgreSQL.
Se você quiser testemunhar o progresso da evolução desde o início, confira as duas primeiras postagens do blog da série:
- Evolução da tolerância a falhas no PostgreSQL
- Evolução da tolerância a falhas no PostgreSQL:fase de replicação

Cronogramas
A capacidade de restaurar o banco de dados para um ponto anterior no tempo cria algumas complexidades que abordaremos alguns dos casos explicando o failover (Fig. 1), troca (Fig. 2) e pg_rewind (Fig. 3) mais adiante neste tópico.
Por exemplo, no histórico original do banco de dados, suponha que você tenha descartado uma tabela crítica às 17h15 de terça-feira à noite, mas não percebeu seu erro até o meio-dia de quarta-feira. Imperturbável, você obtém seu backup, restaura para o ponto no tempo às 17h14 de terça-feira à noite e está funcionando. Nesta história do universo do banco de dados, você nunca descartou a tabela. Mas suponha que mais tarde você perceba que essa não foi uma boa ideia e gostaria de voltar para alguma quarta-feira de manhã na história original. Você não poderá fazê-lo se, enquanto seu banco de dados estava funcionando, ele substituiu alguns dos arquivos de segmento WAL que levaram até o momento em que você deseja voltar.
Assim, para evitar isso, você precisa distinguir a série de registros WAL gerados após ter feito uma recuperação point-in-time daqueles que foram gerados no histórico original do banco de dados.
Para lidar com esse problema, o PostgreSQL tem uma noção de timelines. Sempre que uma recuperação de arquivo é concluída, uma nova linha do tempo é criada para identificar a série de registros WAL gerados após essa recuperação. O número de ID da linha do tempo faz parte dos nomes dos arquivos do segmento WAL, portanto, uma nova linha do tempo não substitui os dados do WAL gerados pelas linhas do tempo anteriores. Na verdade, é possível arquivar muitas linhas do tempo diferentes.
Considere a situação em que você não tem certeza de qual momento para se recuperar e, portanto, precisa fazer várias recuperações pontuais por tentativa e erro até encontrar o melhor lugar para se ramificar da história antiga. Sem cronogramas, esse processo logo geraria uma bagunça incontrolável. Com linhas do tempo, você pode recuperar para qualquer estado anterior, incluindo estados em ramificações da linha do tempo que você abandonou anteriormente.
Toda vez que uma nova linha do tempo é criada, o PostgreSQL cria um arquivo "histórico da linha do tempo" que mostra de qual linha do tempo ela se ramificou e quando. Esses arquivos de histórico são necessários para permitir que o sistema escolha os arquivos de segmento WAL corretos ao recuperar de um arquivo que contém várias linhas do tempo. Portanto, eles são arquivados na área de arquivo WAL, assim como os arquivos de segmento WAL. Os arquivos de histórico são apenas pequenos arquivos de texto, por isso é barato e apropriado mantê-los indefinidamente (ao contrário dos arquivos de segmento que são grandes). Você pode, se quiser, adicionar comentários a um arquivo de histórico para registrar suas próprias anotações sobre como e por que essa linha do tempo específica foi criada. Esses comentários serão especialmente valiosos quando você tiver um emaranhado de linhas do tempo diferentes como resultado da experimentação.
O comportamento padrão de recuperação é recuperar ao longo da mesma linha do tempo que estava atual quando o backup básico foi feito. Se você deseja recuperar em alguma linha de tempo filha (ou seja, deseja retornar a algum estado que foi gerado após uma tentativa de recuperação), você precisa especificar o ID da linha de tempo de destino em recovery.conf. Você não pode recuperar em linhas do tempo que se ramificaram antes do backup básico.
Para simplificar o conceito de linhas do tempo no PostgreSQL, problemas relacionados à linha do tempo em caso de failover , troca e pg_rewind são resumidos e explicados com a Fig.1, Fig.2 e Fig.3.
Cenário de failover:
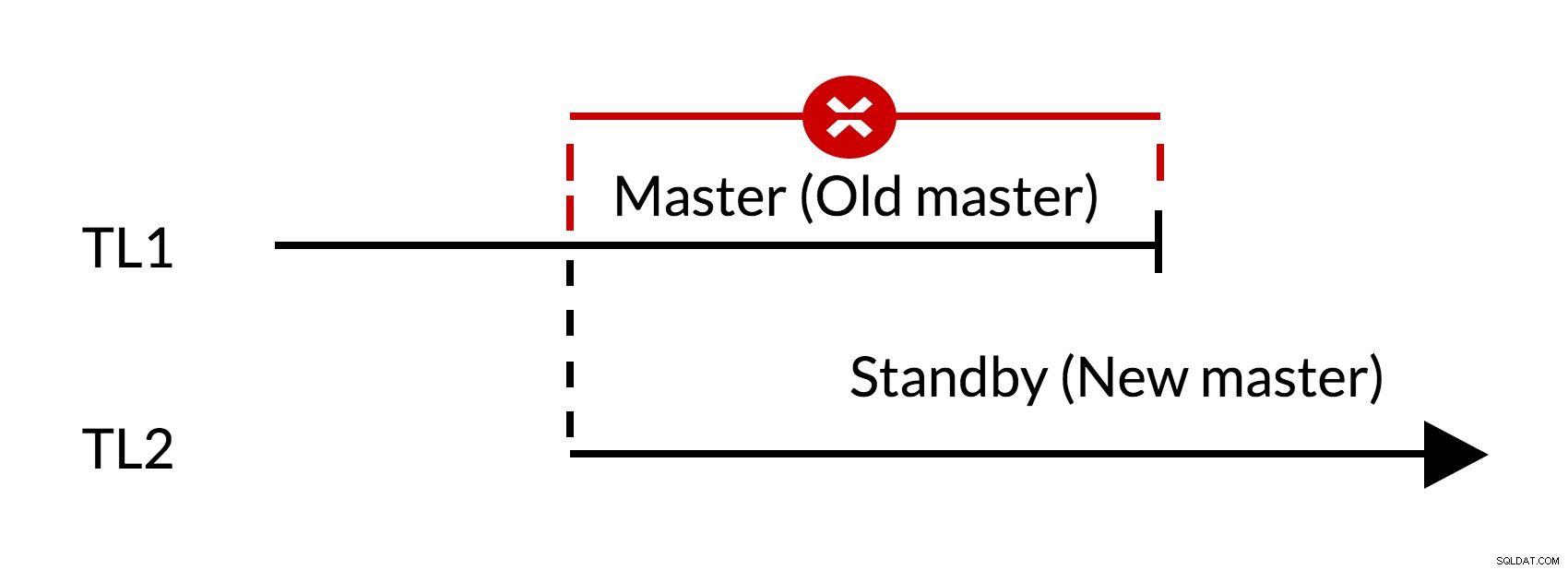
Fig.1 Failover
- Há mudanças pendentes no antigo mestre (TL1)
- O aumento da linha do tempo representa um novo histórico de alterações (TL2)
- As alterações da linha do tempo antiga não podem ser repetidas nos servidores que mudaram para a nova linha do tempo
- O antigo mestre não pode seguir o novo mestre
Cenário de transição:
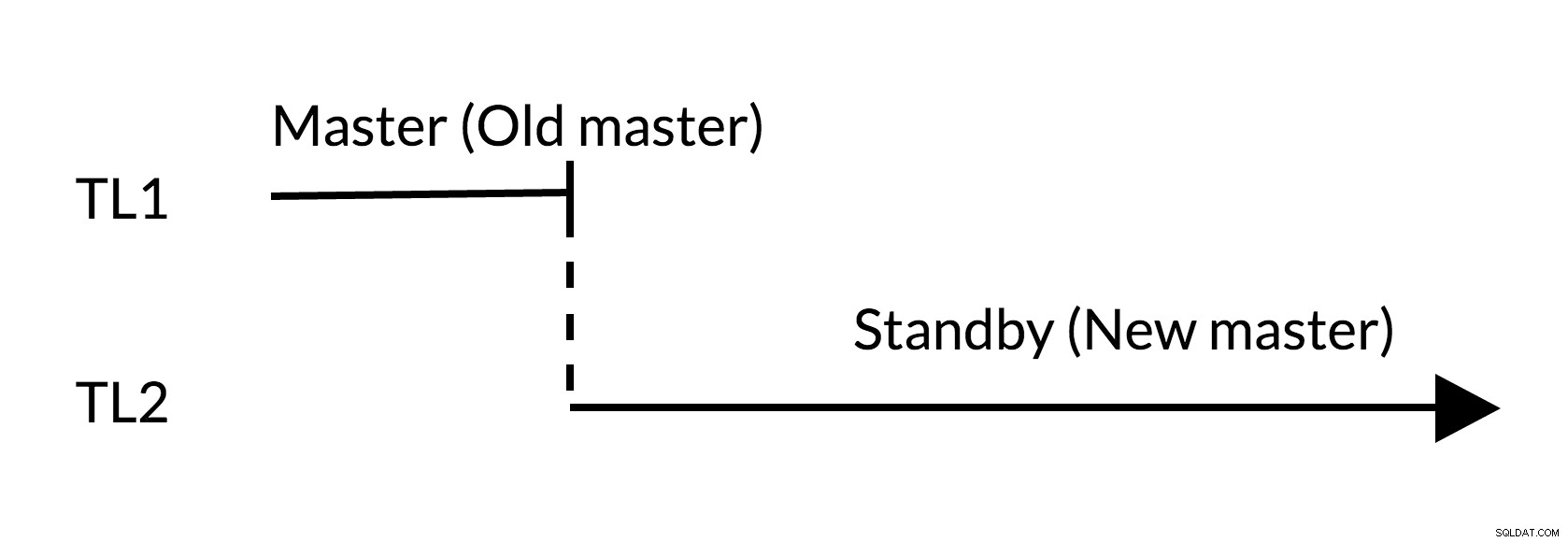 Fig.2 Alternância
Fig.2 Alternância
- Não há alterações pendentes no antigo mestre (TL1)
- O aumento da linha do tempo representa um novo histórico de alterações (TL2)
- O antigo mestre pode ficar em espera para o novo mestre
cenário pg_rewind:
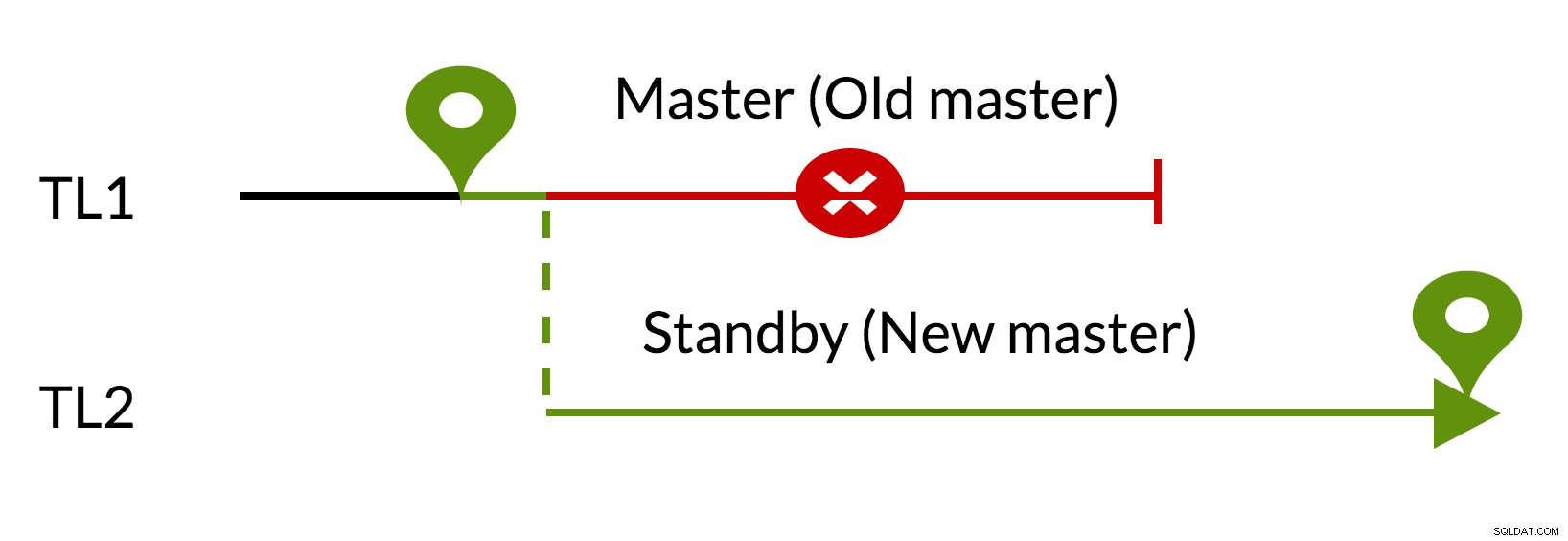 Fig.3 pg_rewind
Fig.3 pg_rewind
- As alterações pendentes são removidas usando dados do novo mestre (TL1)
- O antigo mestre pode seguir o novo mestre (TL2)
pg_rewind
pg_rewind é uma ferramenta para sincronizar um cluster PostgreSQL com outra cópia do mesmo cluster, após as linhas do tempo dos clusters terem divergido. Um cenário típico é colocar um servidor mestre antigo novamente online após o failover, como um modo de espera que segue o novo mestre.
O resultado é equivalente a substituir o diretório de dados de destino pelo de origem. Todos os arquivos são copiados, incluindo arquivos de configuração. A vantagem do pg_rewind sobre fazer um novo backup básico, ou ferramentas como rsync, é que o pg_rewind não requer a leitura de todos os arquivos inalterados no cluster. Isso torna muito mais rápido quando o banco de dados é grande e apenas uma pequena parte dele difere entre os clusters.
Como funciona?
A ideia básica é copiar tudo do novo cluster para o antigo, exceto os blocos que sabemos serem iguais.
- Verifique o log WAL do cluster antigo, começando do último ponto de verificação antes do ponto em que o histórico da linha do tempo do novo cluster se bifurcou do cluster antigo. Para cada registro WAL, anote os blocos de dados que foram tocados. Isso gera uma lista de todos os blocos de dados que foram alterados no cluster antigo, após a bifurcação do novo cluster.
- Copie todos os blocos alterados do novo cluster para o cluster antigo.
- Copie todos os outros arquivos, como arquivos de obstrução e configuração, do novo cluster para o cluster antigo, tudo exceto os arquivos de relação.
- Aplique o WAL do novo cluster, começando no ponto de verificação criado no failover. (Estritamente falando, pg_rewind não aplica o WAL, ele apenas cria um arquivo de rótulo de backup indicando que quando o PostgreSQL for iniciado, ele iniciará a reprodução desse ponto de verificação e aplicará todo o WAL necessário.)
Observação: wal_log_hints deve ser definido em postgresql.conf para que o pg_rewind funcione. Este parâmetro só pode ser definido na inicialização do servidor. O valor padrão é desligado .
Conclusão
Nesta postagem do blog, discutimos as linhas do tempo no Postgres e como lidamos com casos de failover e alternância. Também falamos sobre como o pg_rewind funciona e seus benefícios para a tolerância a falhas e confiabilidade do Postgres. Continuaremos com o commit síncrono na próxima postagem do blog.
Referências
Documentação do PostgreSQL
PostgreSQL 9 Administration Cookbook – Segunda Edição
pg_rewind Nordic PGDay apresentação por Heikki Linnakangas