Recentemente, recebi uma pergunta por e-mail de alguém da comunidade sobre o CLR_MANUAL_EVENT tipo de espera; especificamente, como solucionar problemas com essa espera tornando-se subitamente predominante para uma carga de trabalho existente que dependia muito de tipos de dados espaciais e consultas usando os métodos espaciais no SQL Server.
Como consultor, minha primeira pergunta é quase sempre:“O que mudou?” Mas neste caso, como em tantos outros, eu tinha certeza de que nada havia mudado com o código do aplicativo ou os padrões de carga de trabalho. Então, minha primeira parada foi puxar o CLR_MANUAL_EVENT aguarde na Biblioteca de Tipos de Espera do SQLskills.com para ver quais outras informações já coletamos sobre esse tipo de espera, pois geralmente não é uma espera que vejo problemas no SQL Server. O que achei realmente interessante foi o gráfico/mapa de calor de ocorrências para este tipo de espera fornecido pelo SentryOne no topo da página:
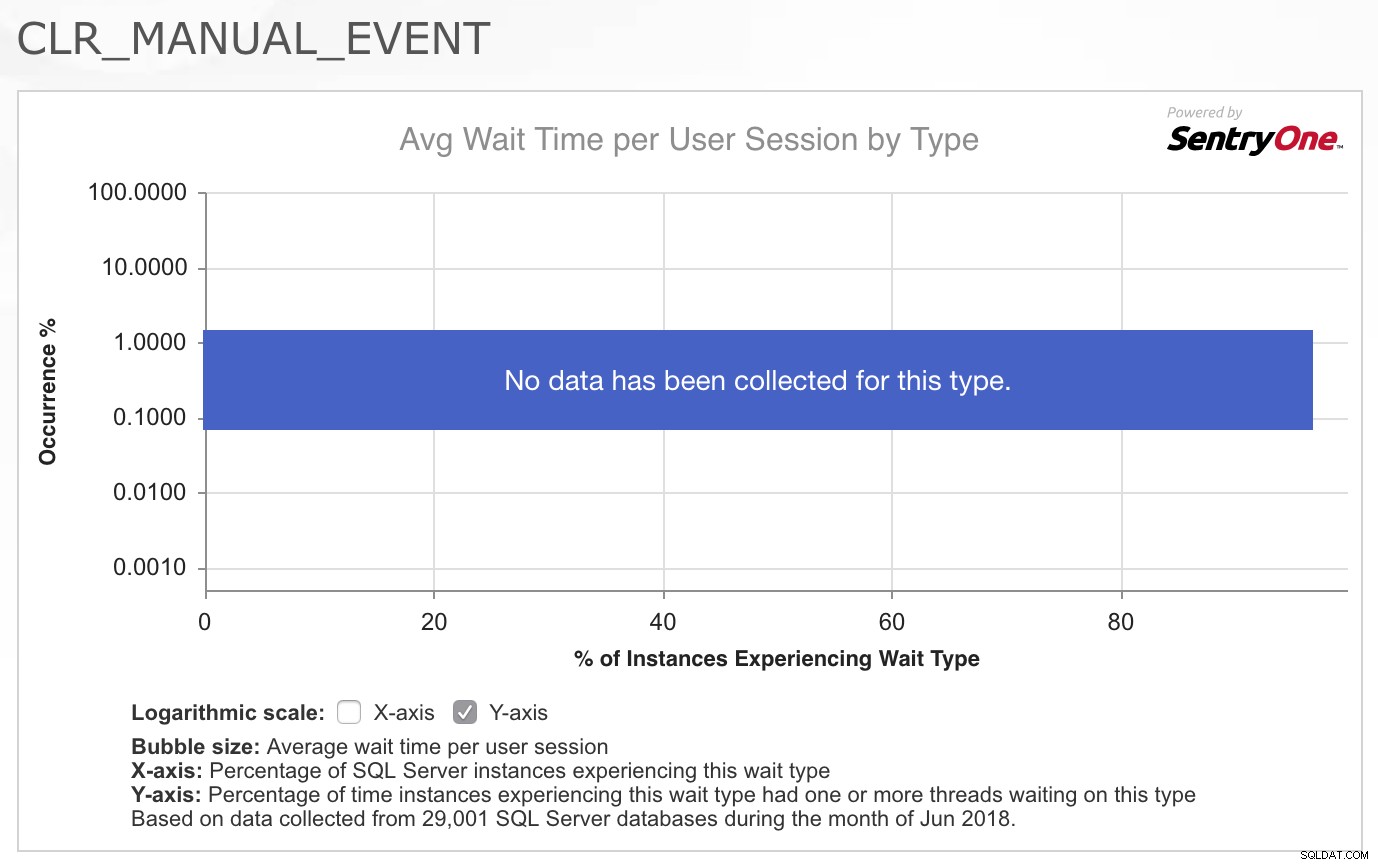
O fato de que nenhum dado foi coletado para esse tipo em uma boa seção transversal de seus clientes realmente confirmou para mim que isso não é algo que geralmente é um problema, então fiquei intrigado com o fato de que essa carga de trabalho específica agora estava exibindo problemas com esta espera. Eu não tinha certeza de onde ir para investigar o problema, então respondi ao e-mail dizendo que lamentava não poder ajudar mais porque não tinha ideia do que estaria causando literalmente dezenas de threads realizando consultas espaciais para de repente começar a ter que esperar por 2-4 segundos de cada vez neste tipo de espera.
Um dia depois, recebi um gentil e-mail de acompanhamento da pessoa que fez a pergunta que me informou que havia resolvido o problema. De fato, nada na carga de trabalho real do aplicativo havia mudado, mas houve uma mudança no ambiente que ocorreu. Um pacote de software de terceiros foi instalado em todos os servidores em sua infraestrutura por sua equipe de segurança, e esse software estava coletando dados em intervalos de cinco minutos e fazendo com que o processamento de coleta de lixo .NET fosse executado de forma incrivelmente agressiva e “enlouquecesse” como eles disseram. Armado com essas informações e alguns dos meus conhecimentos anteriores sobre desenvolvimento .NET, decidi que queria brincar um pouco com isso e ver se conseguia reproduzir o comportamento e como poderíamos solucionar ainda mais as causas.
Informações básicas
Ao longo dos anos, sempre acompanhei o PSSQL Blog no MSDN, e esse geralmente é um dos meus locais de referência quando lembro que li sobre um problema relacionado ao SQL Server em algum momento no passado, mas não consigo • lembre-se de todos os detalhes.
Há uma postagem no blog intitulada Altas esperas em CLR_MANUAL_EVENT e CLR_AUTO_EVENT por Jack Li de 2008 que explica por que essas esperas podem ser ignoradas com segurança no agregado sys.dm_os_wait_stats DMV, pois as esperas ocorrem em condições normais, mas não aborda o que fazer se os tempos de espera forem excessivamente longos ou o que pode estar fazendo com que sejam vistos em vários threads em sys.dm_os_waiting_tasks ativamente.
Há outra postagem no blog de Jack Li de 2013 intitulada Um problema de desempenho envolvendo coleta de lixo CLR e configuração de afinidade de CPU SQL que faço referência em nossa classe de ajuste de desempenho IEPTO2 quando falo sobre várias considerações de instância e como o .NET Garbage Collector (GC) sendo acionado por uma instância pode afetar as outras instâncias no mesmo servidor.
O GC em .NET existe para reduzir o uso de memória de aplicativos usando CLR, permitindo que a memória alocada para objetos seja limpa automaticamente, eliminando assim a necessidade de os desenvolvedores terem que lidar manualmente com alocação e desalocação de memória no grau exigido pelo código não gerenciado . A funcionalidade GC está documentada nos Manuais Online se você quiser saber mais sobre como ela funciona, mas os detalhes além do fato de que as coleções podem estar bloqueando não são importantes para solucionar problemas de esperas ativas em CLR_MANUAL_EVENT no SQL Server ainda mais.
Chegando à raiz do problema
Sabendo que a coleta de lixo pelo .NET era o que estava causando o problema, decidi fazer algumas experiências usando uma única consulta espacial no AdventureWorks2016 e um script do PowerShell muito simples para invocar o coletor de lixo manualmente em um loop para rastrear o que acontece em sys.dm_os_waiting_tasks dentro do SQL Server para a consulta:
USE AdventureWorks2016; GO SELECT a.SpatialLocation.ToString(), a.City, b.SpatialLocation.ToString(), b.City FROM Person.Address AS a INNER JOIN Person.Address AS b ON a.SpatialLocation.STDistance(b.SpatialLocation) <= 100 ORDER BY a.SpatialLocation.STDistance(b.SpatialLocation);
Esta consulta está comparando todos os endereços em Person.Address tabela uns contra os outros para encontrar qualquer endereço que esteja dentro de 100 metros de qualquer outro endereço na tabela. Isso cria uma tarefa paralela de longa execução dentro do SQL Server que também produz um grande resultado cartesiano. Se você decidir reproduzir esse comportamento por conta própria, não espere que isso seja concluído ou retorne os resultados. Com a consulta em execução, o thread pai da tarefa começa a aguardar em CXPACKET espera e a consulta continua sendo processada por vários minutos. No entanto, o que me interessava era o que acontece quando a coleta de lixo acontece no tempo de execução do CLR ou se o GC é invocado, então usei um script simples do PowerShell que faria um loop e forçaria manualmente a execução do GC.
OBSERVAÇÃO:ESTA NÃO É UMA PRÁTICA RECOMENDADA NO CÓDIGO DE PRODUÇÃO POR VÁRIOS MOTIVOS!
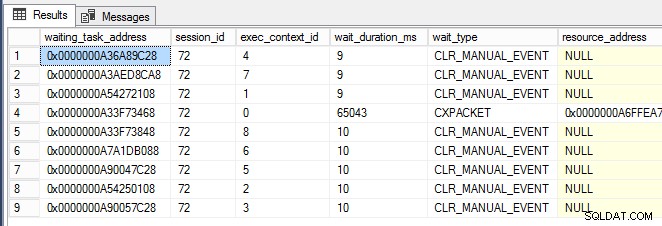
while (1 -eq 1) {[System.GC]::Collect() } Quando a janela do PowerShell estava em execução, quase imediatamente comecei a ver CLR_MANUAL_EVENT esperas que ocorrem nos encadeamentos de subtarefas paralelas (mostrados abaixo, onde exec_context_id é maior que zero) em sys.dm_os_waiting_tasks :
Agora que eu poderia acionar esse comportamento e estava começando a ficar claro que o SQL Server não é necessariamente o problema aqui e pode ser apenas vítima de outra atividade, eu queria saber como aprofundar e identificar a causa raiz do problema . Foi aqui que o PerfMon foi útil para rastrear o grupo de contadores de memória .NET CLR para todas as tarefas no servidor.
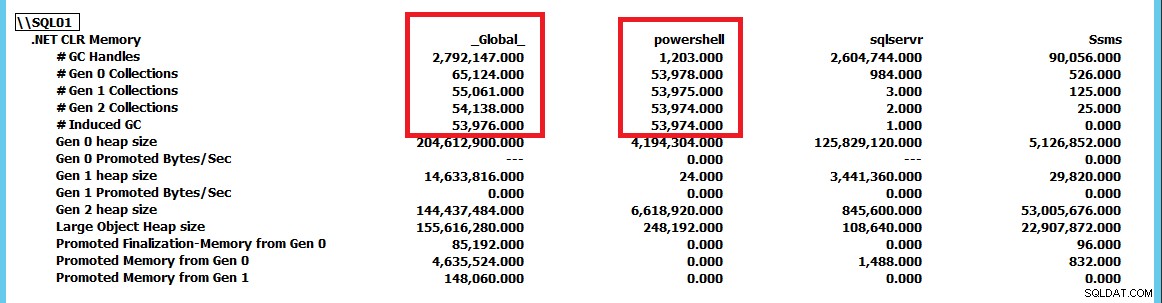
Esta captura de tela foi reduzida para mostrar as coleções para sqlservr e powershell como aplicativos em comparação com o _Global_ coleções pelo tempo de execução do .NET. Forçando GC.Collect() para ser executado constantemente, podemos ver que o powershell instância está conduzindo as coleções de GC no servidor. Usando esse grupo de contadores PerfMon, podemos rastrear quais aplicativos estão realizando mais coletas e, a partir daí, continuar a investigação do problema. Para este caso, simplesmente interromper o script do PowerShell elimina o CLR_MANUAL_EVENT espera dentro do SQL Server e a consulta continua o processamento até que a interrompamos ou permitamos que ela retorne o bilhão de linhas de resultados que seriam geradas por ela.
Conclusão
Se você tiver esperas ativas para CLR_MANUAL_EVENT causando lentidão no aplicativo, não assuma automaticamente que o problema existe dentro do SQL Server. O SQL Server usa a coleta de lixo no nível do servidor (pelo menos antes do SQL Server 2017 CU4, onde pequenos servidores com menos de 2 GB de RAM podem usar a coleta de lixo no nível do cliente para reduzir o uso de recursos). Se você vir esse problema ocorrendo no SQL Server, use o grupo de contadores de memória .NET CLR no PerfMon e verifique se outro aplicativo está conduzindo a coleta de lixo no CLR e bloqueando as tarefas CLR internamente no SQL Server como resultado.



