Enquanto Jeff Atwood e Joe Celko parecem pensar que o custo dos GUIDs não é grande coisa (veja a postagem do blog de Jeff, "Primary Keys:IDs versus GUIDs", e este tópico do grupo de notícias, intitulado "Identity Vs. Uniqueidentifier"), outros especialistas – mais especificamente, especialistas em índice e arquitetura com foco no espaço do SQL Server – tendem a discordar. Por exemplo, Kimberly Tripp aborda alguns detalhes em seu post, "O espaço em disco é barato - ESSE NÃO É O PONTO!", onde ela explica que o impacto não é apenas no espaço em disco e na fragmentação, mas mais importante no tamanho do índice e na memória pegada.
O que Kimberly diz é realmente verdade - sempre me deparo com a justificativa "espaço em disco é barato" para GUIDs (exemplo da semana passada). Existem outras justificativas para GUIDs, incluindo a necessidade de gerar identificadores exclusivos fora do banco de dados (e às vezes antes que a linha seja realmente criada) e a necessidade de identificadores exclusivos em sistemas distribuídos separados (e onde os intervalos de identidade não são práticos). Mas eu realmente quero dissipar o mito de que os GUIDs não custam muito, porque custam, e você precisa pesar esses custos em sua decisão.
Parti nesta missão para testar o desempenho de diferentes tamanhos de chave, com os mesmos dados no mesmo número de linhas, com os mesmos índices e aproximadamente a mesma carga de trabalho (reproduzir a mesma carga de trabalho *exata* pode ser bastante desafiador). Eu não apenas queria medir as coisas básicas, como tamanho do índice e fragmentação do índice, mas também os efeitos que eles têm no final da linha, como:
- impacto no uso do buffer pool
- frequência de divisões de página "ruins"
- impacto geral na duração realista da carga de trabalho
- impacto nos tempos de execução médios de consultas individuais
- impacto na duração do tempo de execução dos acionadores posteriores
- impacto no uso do tempdb
Usarei uma variedade de técnicas para investigar esses dados, incluindo Eventos Estendidos, o rastreamento padrão, DMVs relacionados a tempdb e SQL Sentry Performance Advisor.
Configuração
Primeiro, criei um milhão de clientes para colocar em uma tabela de sementes usando alguns metadados internos do SQL Server; isso garantiria que os clientes "aleatórios" consistiriam nos mesmos dados naturais ao longo de cada teste.
CREATE TABLE dbo.CustomerSeeds( rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) FROM ( SELECT fn, ln, em, a, r =ROW_NUMBER() OVER (PARTITION BY em ORDER BY em) FROM ( SELECT TOP (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. nome, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID())) ),3) + '.com', a =CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y WHERE r =1 GROUP BY fn, ln, em ORDER BY n) AS z ORDER BY rn;GO SELECT TOP (10) * FROM dbo.CustomerSeeds ORDER BY rn;GO
Sua milhagem pode variar, mas no meu sistema, essa população levou 86 segundos. Dez linhas representativas (clique para ampliar):
 Amostra de clientes
Amostra de clientes Em seguida, eu precisava de tabelas para abrigar os dados iniciais de cada caso de uso, com alguns índices extras para simular algum tipo de realidade, e criei sufixos curtos para facilitar todos os tipos de diagnósticos posteriormente:
| tipo de dados | padrão | compressão | sufixo de caso de uso |
|---|---|---|---|
| INT | IDENTIDADE | nenhum | Eu |
| INT | IDENTIDADE | página + linha | Ic |
| GRANDE | IDENTIDADE | nenhum | B |
| GRANDE | IDENTIDADE | página + linha | Bc |
| ÚNICO IDENTIFICADOR | NOVO() | nenhum | G |
| ÚNICO IDENTIFICADOR | NOVO() | página + linha | Gc |
| ÚNICO IDENTIFICADOR | NEWSEQUENTIALID() | nenhum | S |
| ÚNICO IDENTIFICADOR | NEWSEQUENTIALID() | página + linha | Sc |
Tabela 1:casos de uso, tipos de dados e sufixos
Oito tabelas ao todo, todas baseadas no mesmo modelo (eu apenas mudaria os comentários para corresponder ao caso de uso e substituiria
$use_case$ com o sufixo apropriado da tabela acima):CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, LastName NVARCHAR(64) NOT NULL, E-mail NVARCHAR(320) NOT NULL, Active BIT NOT NULL DEFAULT 1, criado DATETIME NOT NULL DEFAULT SYSDATETIME(), atualizado DATETIME NULL, CONSTRAINT C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --WITH (DATA_COMPRESSION =PAGE)GO;CREATE UNIQUE INDEX C_Email_Customers_$use_case$ ON dbo. Customers_$use_case$(EMail) --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Active_Customers_$use_case$ ON dbo.Customers_$use_case$(FirstName, LastName, EMail) WHERE Active =1 --WITH (DATA_COMPRESSION =PAGE);GOCREATE ÍNDICE C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(LastName, FirstName) INCLUDE (EMail) --WITH (DATA_COMPRESSION =PAGE);GO
Uma vez que as tabelas foram criadas, continuei a preencher as tabelas e medir muitas das métricas que mencionei acima. Reiniciei o serviço do SQL Server entre cada teste para ter certeza de que todos estavam começando da mesma linha de base, que os DMVs seriam redefinidos etc.
Inserções não contestadas
Meu objetivo final era preencher a tabela com 1.000.000 de linhas, mas primeiro eu queria ver o impacto do tipo de dados e da compactação em inserções brutas sem contenção. Gerei a seguinte consulta – que preencheria a tabela com os primeiros 200.000 contatos, 2.000 linhas por vez – e a executei em cada tabela:
DECLARE @i INT =1;WHILE @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Active) SELECT FirstName, LastName, Email, Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) LINHAS BUSCAR AS PRÓXIMAS 2000 LINHAS SOMENTE; SET @i +=1;END
Resultados (clique para ampliar):
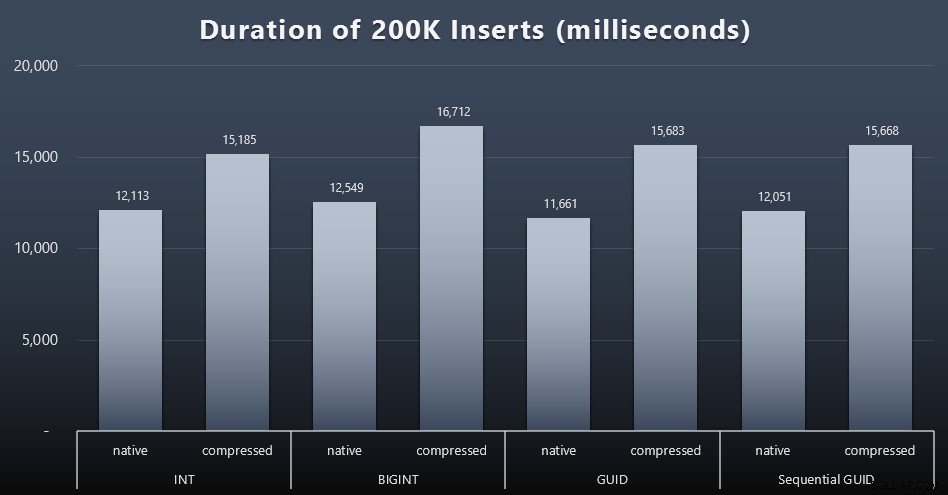
Cada caso levou cerca de 12 segundos (sem compactação) e 16 segundos (com compactação), sem um vencedor claro em nenhum dos modos de armazenamento. O efeito da compactação (principalmente na sobrecarga da CPU) é bastante consistente, mas como está sendo executado em um SSD rápido, o impacto de E/S dos diferentes tipos de dados é insignificante. Na verdade, a compactação contra BIGINT parecia ter o maior impacto (e isso faz sentido, já que cada valor menor que 2 bilhões seria compactado).
Carga de trabalho mais contenciosa
Em seguida, eu queria ver como uma carga de trabalho mista competiria por recursos e geralmente funcionaria em relação a cada tipo de dados. Então eu criei esses procedimentos (substituindo$use_case$e$data_type$apropriadamente para cada teste):
-- atualizações aleatórias de singleton para dados em mais de um índiceCREATE PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN SET NOCOUNT ON; UPDATE dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- lê ("paginação") - suportando múltiplos sorts-- use SQL dinâmico para rastrear estatísticas de consulta separadamenteCREATE PROCEDURE [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT CustomerID, FirstName, LastName, Email, Active, Created, Updated FROM dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) ROWS FETCH NEXT @ps SOMENTE LINHAS;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGO
Então criei trabalhos que chamariam esses procedimentos repetidamente, com pequenos atrasos, e também – simultaneamente – terminariam de preencher os 800.000 contatos restantes. Este script cria todos os 32 trabalhos e também imprime a saída que pode ser usada posteriormente para chamar todos os trabalhos para um teste específico de forma assíncrona:
USE msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(nome SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(nome, cmd) VALUES( N'Atualização aleatória de carga de trabalho', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN SELECT TOP (1) @CustomerID =CustomerID FROM dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; WAITFOR DELAY ''00:00 :01''; SET @i +=1; END'),( N'Preencher clientes', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (FirstName, LastName, Email, Active) SELECT FirstName, LastName, Email, Active FROM dbo.CustomerSeeds AS c ORDER POR rn OFFSET 2000 * (@i-1) ROWS FETCH NEXT 2000 ROWS ONLY; WAITFOR DELAY ''00:00:01''; SET @i +=1; END'),( N'Paging workload 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- classificar por CustomerID SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; AGUARDE ATRASO ''00:00:01''; SET @i +=2; END'),( N'Paging workload 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- class by LastName, FirstName SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''LastName, FirstName'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'); DECLARE @n SYSNAME, @c NVARCHAR(MAX); DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT nome =t.use_case + N' ' + j.name, cmd =REPLACE(J.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) FROM @typ AS t CROSS JOIN @jobs AS j; ABRIR c; FETCH c INTO @n, @c; WHILE @@FETCH_STATUS <> -1BEGIN IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE nome =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(local)'; PRINT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; FETCH c INTO @n, @c;END
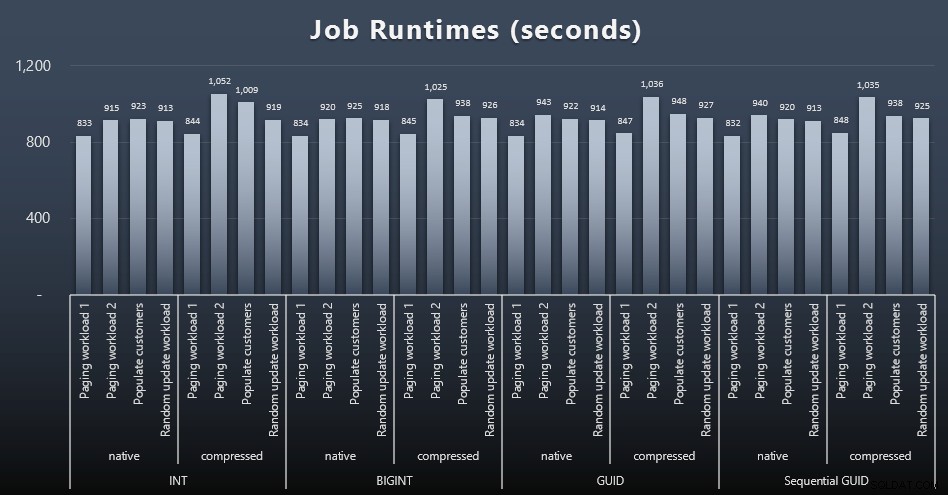
Medir os tempos de trabalho em cada caso era trivial - eu poderia verificar as datas de início/término emmsdb.dbo.sysjobhistoryou puxe-os do SQL Sentry Event Manager. Aqui estão os resultados (clique para ampliar):
E se você quiser ter um pouco menos para digerir, basta olhar para os tempos de execução médios e máximos nos quatro trabalhos (clique para ampliar):
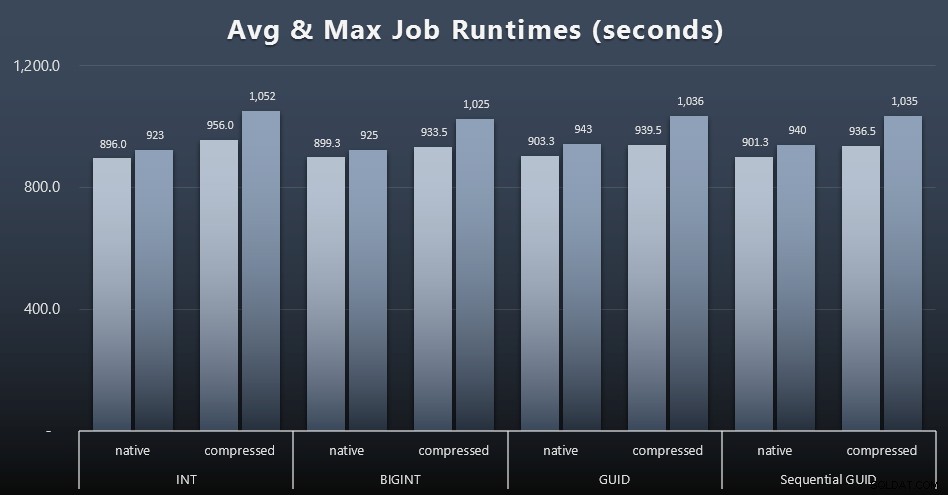
Mas mesmo neste segundo gráfico não há realmente variação suficiente para fazer um argumento convincente a favor ou contra qualquer uma das abordagens.
Tempos de execução de consulta
Peguei algumas métricas desys.dm_exec_query_statsesys.dm_exec_trigger_statspara determinar quanto tempo as consultas individuais estavam demorando em média.
População
Os primeiros 200.000 clientes foram carregados rapidamente – menos de 20 segundos – devido à ausência de cargas de trabalho concorrentes. Uma vez que os quatro trabalhos estavam sendo executados simultaneamente, no entanto, houve um impacto significativo nas durações de gravação devido à simultaneidade. As 800.000 linhas restantes exigiram pelo menos uma ordem de magnitude a mais de tempo para serem concluídas, em média. Aqui estão os resultados da média de cada inserção de 2.000 clientes (clique para ampliar):
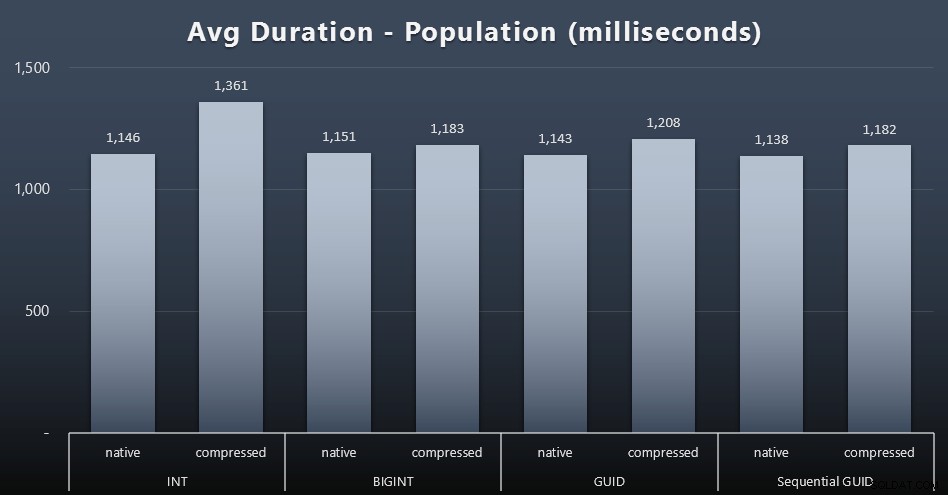
Vemos aqui que compactar um INT foi o único real outlier – tenho algumas teorias sobre isso, mas nada conclusivo ainda.
Cargas de trabalho de paginação
Os tempos de execução médios das consultas de paginação também parecem ter sido significativamente afetados pela simultaneidade em comparação com minhas execuções de teste isoladas. Aqui estão os resultados (clique para ampliar):
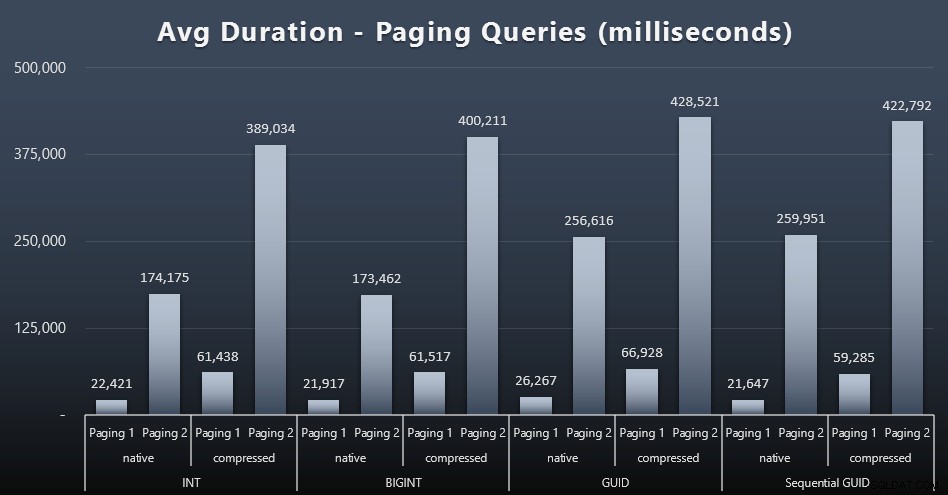
(Paging 1 =pedido por CustomerID, Paging 2 =pedido por LastName, FirstName.)
Vemos que tanto para Paginação 1 (pedir por CustomerID) quanto para Paginação 2 (ordenar por nomes), há um impacto significativo no tempo de execução devido à compactação (até ~700%). Ambos os GUIDs parecem ser os cavalos mais lentos nesta corrida, com NEWID() tendo o pior desempenho.
Atualizar cargas de trabalho
As atualizações singleton foram bastante rápidas, mesmo sob forte simultaneidade, mas ainda havia algumas diferenças perceptíveis devido à compactação e até algumas diferenças surpreendentes entre os tipos de dados (clique para ampliar):
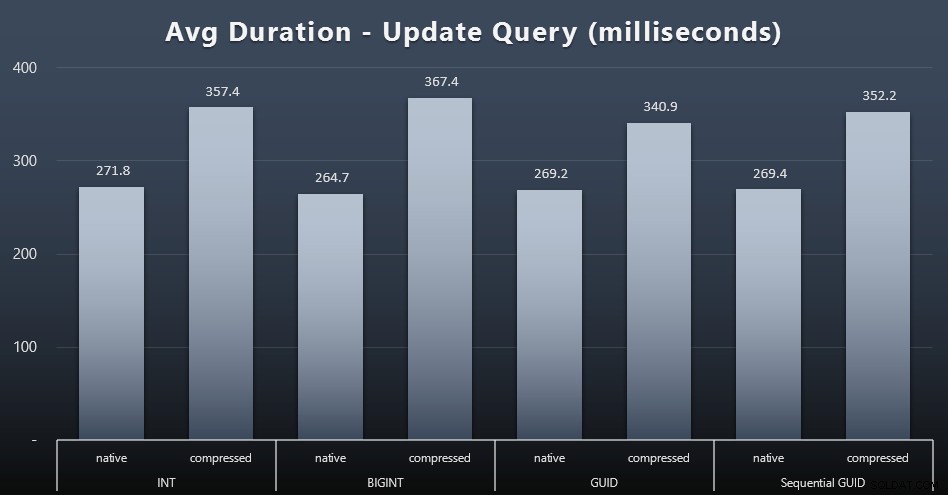
Mais notavelmente, as atualizações nas linhas contendo valores GUID foram realmente mais rápidas do que as atualizações contendo INT/BIGINT, quando a compactação estava em uso. Com armazenamento nativo, as diferenças foram menos notáveis (mas INT ainda era um perdedor).
Estatísticas de gatilho
Aqui estão os tempos de execução médio e máximo para o gatilho simples em cada caso (clique para ampliar):
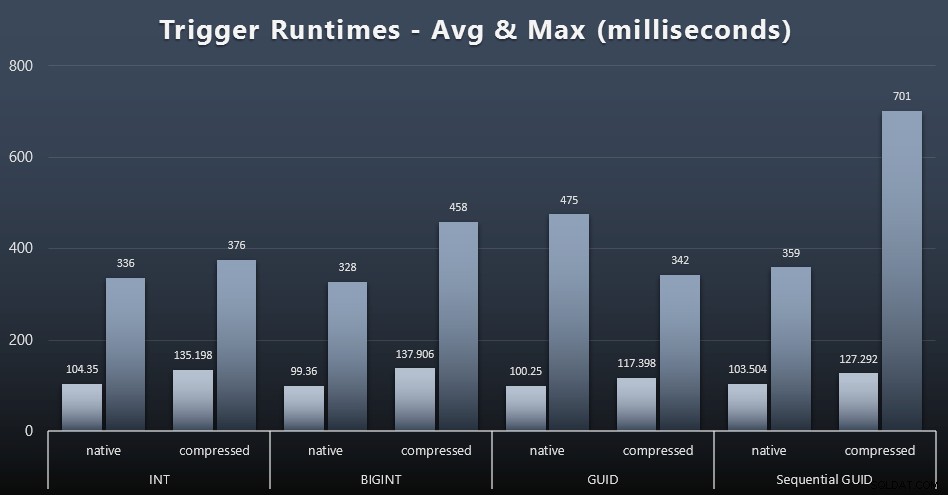
A compactação parece ter um impacto muito maior aqui do que a escolha do tipo de dados (embora isso provavelmente fosse mais pronunciado se parte da minha carga de trabalho de atualização tivesse atualizado muitas linhas em vez de consistir apenas em buscas de uma única linha). O máximo para o GUID sequencial é claramente um valor atípico de algum tipo que eu não investiguei (você pode dizer que é insignificante com base na média ainda alinhada em toda a linha).
O que essas consultas estavam esperando?
Após cada carga de trabalho, também dei uma olhada nas principais esperas no sistema, descartando esperas óbvias de fila/temporizador (conforme descrito por Paul Randal) e atividades irrelevantes do software de monitoramento (como
TRACEWRITE ). Aqui estão as 3 principais esperas em cada caso (clique para ampliar):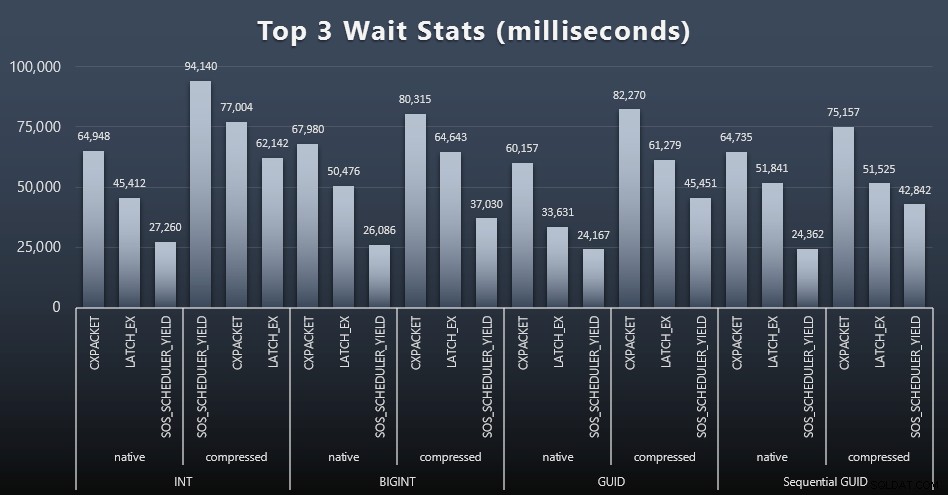
Na maioria dos casos, as esperas eram CXPACKET, depois LATCH_EX e depois SOS_SCHEDULER_YIELD. No caso de uso envolvendo inteiros e compactação, porém, SOS_SCHEDULER_YIELD assumiu, o que implica para mim alguma ineficiência no algoritmo para compactar inteiros (que pode não estar relacionado ao algoritmo usado para espremer BIGINTs em INTs). Não investiguei isso mais a fundo, nem encontrei justificativa para rastrear esperas por consulta individual.
Espaço em Disco/Fragmentação
Embora eu tenha a tendência de concordar que não se trata do espaço em disco, ainda é uma métrica que vale a pena apresentar. Mesmo neste caso muito simplista onde há apenas uma tabela e a chave não está presente em todas as outras tabelas relacionadas (o que certamente existiria em uma aplicação real), a diferença é significativa. Primeiro vamos ver o
reserved coluna de sp_spaceused (Clique para ampliar):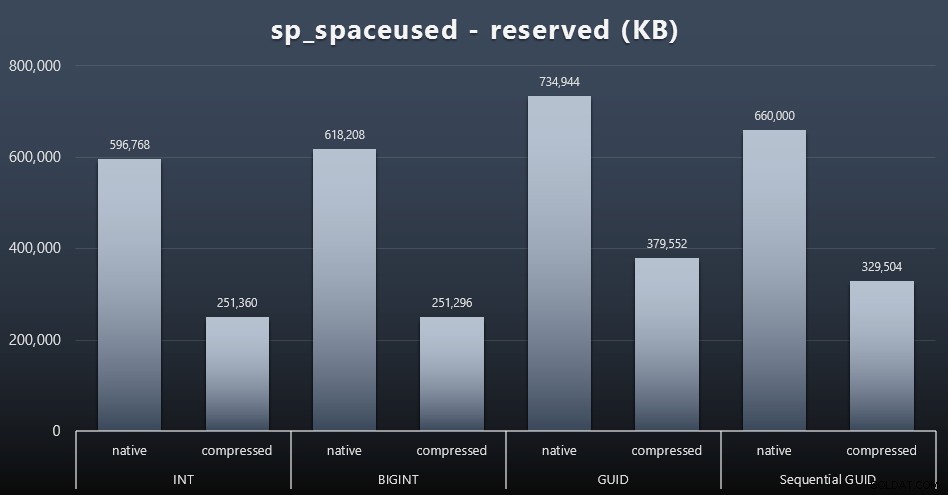
Aqui, BIGINT só ocupou um pouco mais de espaço que INT, e GUID (como esperado) teve um salto maior. O GUID sequencial teve um aumento menos significativo no espaço usado e também compactado muito melhor do que o GUID tradicional. Novamente, sem surpresas aqui – um GUID é maior que um número, ponto final. Agora, os defensores do GUID podem argumentar que o preço que você paga em termos de espaço em disco não é muito (18% sobre BIGINT sem compactação, cerca de 50% com compactação). Mas lembre-se que esta é uma única tabela de 1 milhão de linhas. Imagine como isso extrapolará quando você tiver 10 milhões de clientes e muitos deles tiverem 10, 30 ou 500 pedidos – essas chaves podem ser repetidas em uma dúzia de outras tabelas e ocupar o mesmo espaço extra em cada linha.
Quando observei a fragmentação após cada carga de trabalho (lembre-se, nenhuma manutenção de índice está sendo realizada) usando esta consulta:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Os resultados resultaram em visuais muito menos interessantes; todos índices não agrupados foram fragmentados em mais de 99%. Os índices clusterizados, no entanto, eram altamente fragmentados ou não fragmentados (clique para ampliar):
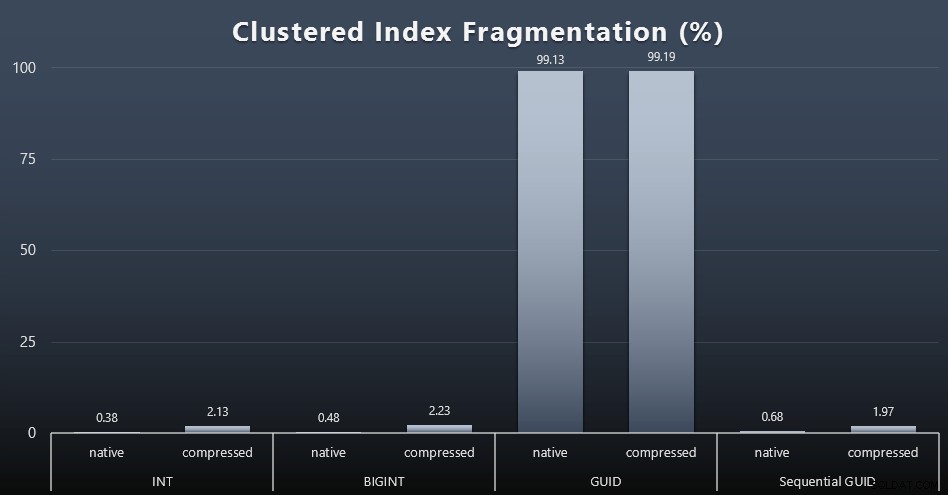
A fragmentação é outra métrica que geralmente significa muito menos quando estamos falando de SSDs, mas é importante observar a mesma coisa, pois nem todos os sistemas podem se dar ao luxo de ignorar o impacto que a fragmentação pode ter nos padrões de E/S. Acredito que usando GUIDs não sequenciais, em um sistema mais vinculado a E/S, o impacto dessa fragmentação por si só seria drasticamente amplificado na maioria das outras métricas neste teste.
Uso do conjunto de buffers
É aqui que ser criterioso sobre a quantidade de espaço em disco usado por suas tabelas realmente compensa – quanto maiores forem suas tabelas, mais espaço elas ocuparão no buffer pool. Mover dados para dentro e para fora do buffer pool é caro e, novamente, esse é um caso muito simplista em que os testes foram executados isoladamente e não havia outros aplicativos e bancos de dados na instância competindo por memória preciosa.
Esta é uma medida simples da seguinte consulta no final de cada carga de trabalho:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE secretário_name =N'Buffer Pool';
Resultados (clique para ampliar):
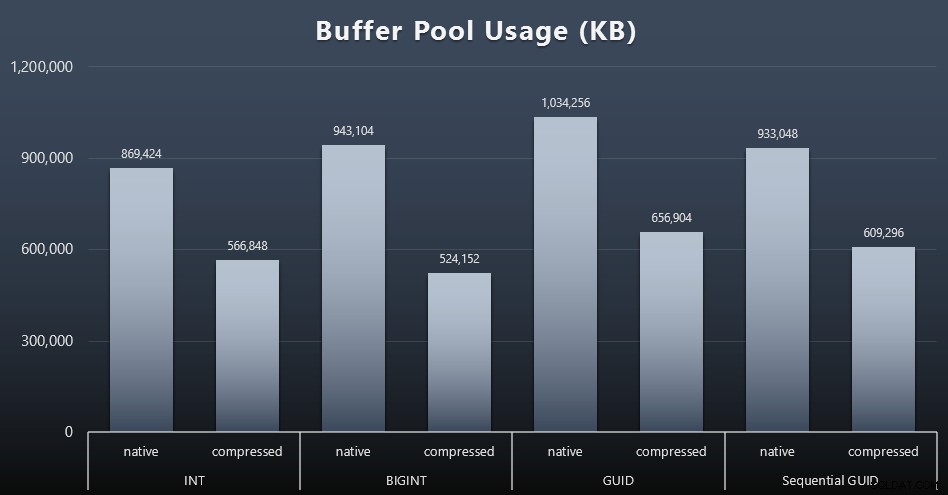
Embora a maior parte deste gráfico não seja surpreendente – GUID ocupa mais espaço que BIGINT, BIGINT mais que INT – achei interessante que um GUID Sequencial ocupasse menos espaço que um BIGINT, mesmo sem compactação. Fiz uma anotação para realizar algumas análises forenses em nível de página para determinar que tipo de eficiência está ocorrendo aqui nos bastidores.
Uso do tempdb
Não tenho certeza do que estava esperando aqui, mas após cada carga de trabalho, reuni o conteúdo dos três DMVs de uso de espaço relacionados ao tempdb,
sys.dm_db_file|session|task_space_usage . O único que parecia mostrar alguma volatilidade com base no tipo de dados foi sys.dm_db_file_space_usage extent_allocation_page_count de . Isso mostra que - pelo menos na minha configuração e nessa carga de trabalho específica - os GUIDs colocarão o tempdb em um treino um pouco mais completo (clique para ampliar):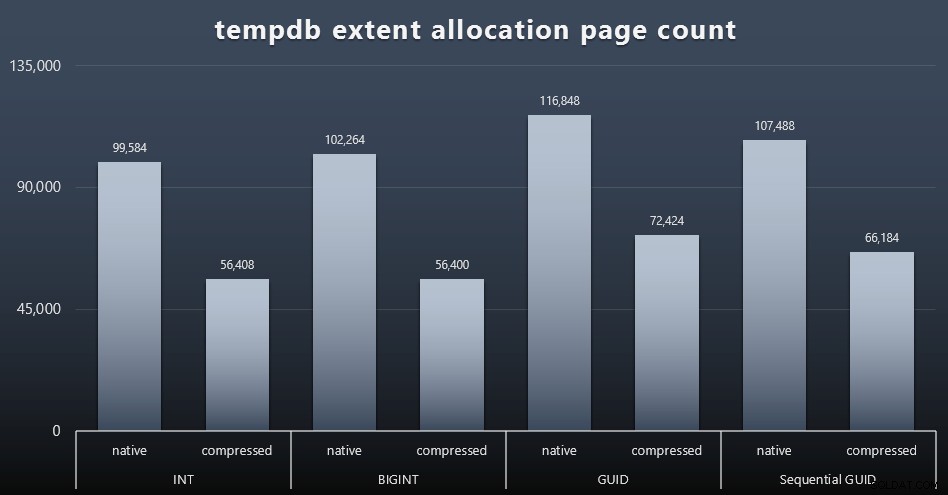
Divisões de página "ruins"
Uma das coisas que eu queria medir era o impacto nas divisões de página – não divisões de página normais (quando você adiciona uma nova página), mas quando você realmente precisa mover dados entre páginas para liberar espaço para mais linhas. Jonathan Kehayias fala sobre isso com mais detalhes em sua postagem no blog, "Tracking Problematic Pages Splits in SQL Server 2012 Extended Events – No Really This Time!", que também fornece a base para a sessão Extended Events que usei para capturar os dados:
CREATE EVENT SESSION [BadPageSplits] ON SERVER ADD EVENT sqlserver.transaction_log (WHERE operação =11 AND database_id =10) ADD TARGET package0.histogram ( SET filtering_event_name ='sqlserver.transaction_log', source_type =0, source ='alloc_unit_id' ); SESSÃO DO EVENTO DO GOALTER [BadPageSplits] NO ESTADO DO SERVIDOR =START;GO
E a consulta que usei para plotar:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name ='BadPageSplits' AND t.target_name ='histograma' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.alloc_unit_idINNER JOIN sys.partitions AS p ON au. container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id =t.[object_id]GROUP BY t.name; E aqui estão os resultados (clique para ampliar):
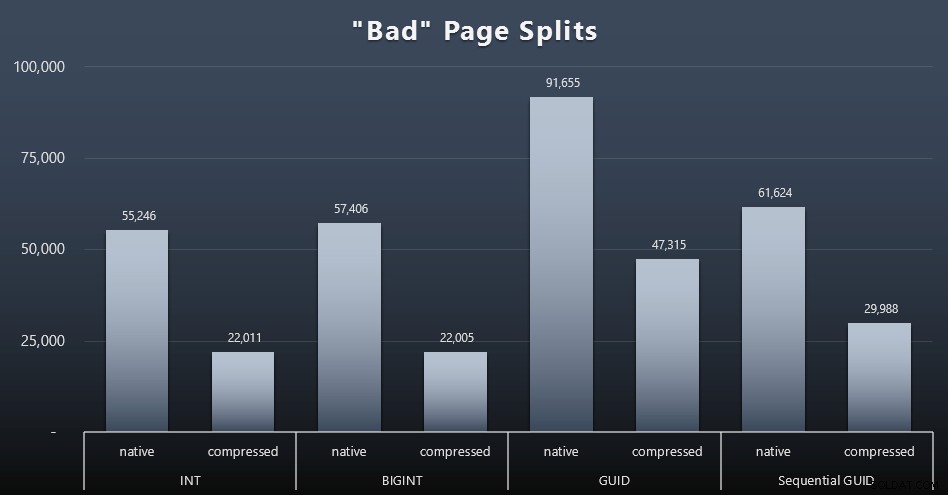
Embora eu já tenha notado que no meu cenário (onde estou executando em SSDs rápidos) a diferença indiscutível na atividade de E/S não afeta diretamente o tempo de execução geral, essa ainda é uma métrica que você deve considerar - principalmente se você não tem SSDs ou se sua carga de trabalho já está vinculada a E/S.
Conclusão
Embora esses testes tenham aberto meus olhos um pouco mais sobre como as percepções de longa duração que tive foram alteradas por hardware mais moderno, ainda sou totalmente contra o desperdício de espaço no disco ou na memória. Embora eu tenha tentado demonstrar algum equilíbrio e deixar os GUIDs brilharem, há muito pouco aqui do ponto de vista do desempenho para oferecer suporte à mudança de INT/BIGINT para qualquer forma de UNIQUEIDENTIFIER - a menos que você precise por outros motivos menos tangíveis (como criar a chave em o aplicativo ou manter valores de chave exclusivos em sistemas diferentes). Um resumo rápido, mostrando que NEWID() é a pior escolha em muitas das métricas em que houve uma diferença substancial (e na maioria desses casos, NEWSEQUENTIALID() ficou em segundo lugar):
| Métrica | Limpar perdedor(es)? |
|---|---|
| Inserções não contestadas | – desenhar – |
| Carga de trabalho simultânea | – desenhar – |
| Consultas individuais – população | INT (compactado) |
| Consultas individuais – Paginação | NEWID() / NEWSEQUENTIALID() |
| Consultas individuais – atualização | INT (nativo) / BIGINT (compactado) |
| Consultas individuais – DEPOIS do gatilho | – desenhar – |
| Espaço em disco | NOVO() |
| Fragmentação de índice em cluster | NOVO() |
| Uso do conjunto de buffers | NOVO() |
| Uso do tempdb | NOVO() |
| Divisões de página "ruins" | NOVO() |
Tabela 2:Maiores perdedores
Sinta-se à vontade para testar essas coisas por si mesmo; Posso montar meu conjunto completo de scripts se você quiser executá-los em seu próprio ambiente. O objetivo sem fôlego de todo este post é bastante simples:há muitas métricas importantes a serem consideradas além do impacto previsível no espaço em disco, portanto, não deve ser usado sozinho como um argumento em qualquer direção.
Agora, não quero que essa linha de pensamento fique restrita às chaves, per se. Isso realmente deve ser pensado sempre que qualquer escolha de tipo de dados estiver sendo feita. Vejo
datetime sendo escolhido com frequência, por exemplo, quando apenas uma date ou smalldatetime é preciso. Em tabelas transacionais, isso também pode gerar muito espaço em disco desperdiçado, e isso também atinge alguns desses outros recursos. Em um teste futuro, gostaria de comparar os resultados de uma tabela muito maior (> 2 bilhões de linhas). Eu posso simular isso com INT definindo a semente de identidade para -2 bilhões, permitindo cerca de 4 bilhões de linhas. E gostaria que as comparações de carga de trabalho e espaço em disco/memória envolvessem mais de uma única tabela, pois uma das vantagens de uma chave estreita é quando essa chave é representada em dezenas de tabelas relacionadas. Eu estava monitorando eventos de crescimento automático, mas não havia nenhum, já que o banco de dados era pré-dimensionado grande o suficiente para acomodar o crescimento e não pensei em medir o uso real do log dentro do arquivo de log existente, então gostaria de testar novamente com os padrões para tamanho de log e crescimento automático, e desta vez medindo
DBCC SQLPERF(LOGSPACE); . Também seria interessante cronometrar reconstruções e medir o uso de log como resultado dessas operações. Por fim, gostaria de tornar a E/S um fator mais relevante encontrando um servidor com discos rígidos mecânicos – sei que existem muitos por aí, mas em algumas lojas eles são bem escassos. 


