Há muito o que ter em mente ao projetar um banco de dados, e poucos de nós conseguem se lembrar de todas as dicas e truques valiosos que aprendemos. Então, vamos dar uma olhada em alguns recursos online que apresentam dicas de design de banco de dados e práticas recomendadas. À medida que avançamos, compartilharei minhas próprias opiniões sobre as ideias apresentadas, com base em minha experiência em design de banco de dados.
Obviamente, este artigo não é uma lista exaustiva, mas tentei revisar e comentar uma seção cruzada de fontes. Felizmente, você encontrará as informações que melhor se adequam às suas necessidades e objetivos.
Como observação lateral, fiquei surpreso ao descobrir que muitos artigos relacionados às práticas de design de banco de dados tinham muito poucos exemplos; os recursos on-line que revisei para o artigo sobre erros e enganos tinham uma porcentagem maior deles. Essa falta é uma desvantagem, porque os exemplos são extremamente importantes para passar o ponto.
Dicas de banco de dados para designers experientes
Primeiro, vamos começar com as fontes que apresentam dicas avançadas de design de banco de dados e práticas recomendadas. Estes são para designers que já estão trabalhando em modelagem de dados e estão há algum tempo. Alguns artigos são direcionados a um nível mais intermediário, mas se eles discutem conceitos avançados, eu os incluí nesta lista.
Diretrizes de banco de dados (RDBMS/SQL)
por Steve Djajasaputra | SOA, Java, Desenvolvimento de Software – BlogSpot | 16 de janeiro de 2013
Este artigo do Sr. Djajasaputra é bastante impressionante:ele lista várias dicas para o esquema, índices e visualizações; ele também fornece uma convenção de nomenclatura bastante detalhada. E suas dicas continuam (e continuam). A amplitude é impressionante, mas quase não há exemplos. Alguns de seus pontos podem ser considerados discutíveis, mas no geral esta é uma apresentação muito sólida.
Em particular, fiquei impressionado que ele fornece uma regra precisa sobre o uso de chaves primárias naturais versus artificiais (ou seja, substitutas ou geradas). Ele mantém isso agradável e simples, especificando que devemos preferir uma chave natural porque é significativa. Ele também fornece diretrizes para o melhor uso de uma chave artificial – especificamente, quando a chave natural não é única ou quando você precisa alterar o valor da chave natural. Em suas próprias palavras:
Primeiro, prefira usar a chave natural, pois é mais significativa e evita duplicações (reutilize a coluna existente). Mas há casos em que você precisa de uma chave artificial:quando a chave natural não é única (por exemplo, nomes) ou se você precisa alterar o valor.
Como a lista de dicas dele é tão longa, não consigo me imaginar lembrando de todas. Mas cada seção pode ser referenciada quando você estiver trabalhando no design, desempenho, procedimentos armazenados e controle de versão do banco de dados. Há também uma seção sobre pontos específicos do Oracle que seriam úteis se você estiver trabalhando ou planejando oferecer suporte ao Oracle.
Em suma, este é um recurso muito valioso e abrangente.
9 dicas para um melhor design de banco de dados
por Jeffrey Edison | Blog Vertabelo | 22 de setembro de 2015
Vou entrar em um pouco de auto-promoção aqui.
Este artigo de 9 dicas para um melhor design de banco de dados é baseado na minha experiência como designer e arquiteto. Também encontrei insights adicionais pesquisando as melhores práticas de outros para design de banco de dados.
Minha lista representa alguns dos principais problemas que podem ocorrer ao trabalhar com modelos de dados. Organizei as dicas na ordem em que ocorrem durante o ciclo de vida do projeto (em vez de importância ou frequência com que surgem), pois isso seria mais útil, pelo menos na minha opinião. Os leitores podem seguir esta lista de verificação das melhores práticas ao longo do ciclo de vida de um projeto.
Do artigo:
Parafraseando Al Capone (ou John Van Buren, filho do 8º presidente dos EUA), “teste cedo, teste com frequência”. Dessa forma, você segue o caminho da Integração Contínua. Testar em um estágio inicial de desenvolvimento economiza tempo e dinheiro. Ao testar o banco de dados, o objetivo deve ser simular um ambiente de produção:“Um dia na vida do banco de dados”. Que volumes podem ser esperados? Quais interações do usuário são prováveis? Os casos limite estão sendo tratados?
Ao prestar atenção a essas dicas, descobri que os bancos de dados ficam mais bem projetados e mais robustos. Embora nenhuma dessas atividades demore muito tempo, cada uma delas pode ter um impacto enorme na qualidade do seu modelo de dados.
Espero que minha lista de dicas seja útil para designers intermediários e avançados.
20 práticas recomendadas de design de banco de dados
por Cagdas Basaraner | Saldo de código – BlogSpot | 24 de julho de 2011
O Sr. Basaraner nos apresenta uma lista interessante de 20 melhores práticas de design de banco de dados. Eu teria preferido que ele tivesse agrupado alguns deles; por exemplo, os primeiros quatro itens podem ser cobertos em “Use Good Noming Conventions”.
Além disso, ele afirma que usar um ID sintético gerado (inteiro) como a chave primária de todas as tabelas é uma prática recomendada. Na verdade, esse ainda é um assunto debatido, com argumentos a favor e contra. Algumas de suas melhores práticas são bastante genéricas, como “Para… sistemas de banco de dados de missão crítica [sic], use recuperação de desastres e serviço de segurança…” Não discordo desse ponto, mas é de alto nível.
No lado positivo, este artigo foi um dos poucos que mencionam o uso de uma estrutura de mapeamento relacional de objeto (ORM). Alguns comentaristas discordaram de como a dica foi redigida, mas pelo menos o uso de uma estrutura ORM é mencionado:
Use uma estrutura ORM (mapeamento relacional de objetos) (ou seja, Hibernate, iBatis ...) se o código do aplicativo for grande o suficiente. Problemas de desempenho de estruturas ORM podem ser tratados por parâmetros de configuração detalhados.
Ainda assim, esta lista poderia ter sido melhorada. Deve identificar claramente os pontos específicos de apenas algumas sistemas de gerenciamento de banco de dados (por exemplo, SQL Server). Estatísticas precisas sobre desempenho, heurística ou a importância de gastar tempo em design em vez de manutenção e redesign teria sido bom. Mais exemplos também eram necessários, mas isso é um problema para a maioria desses artigos.
Se você estiver trabalhando com o SQL Server, pensando em usar uma estrutura ORM ou precisando de uma lista de dicas com marcadores em vez de um artigo longo e detalhado, este artigo é para você.
(Observação:este artigo também apareceu em vários outros sites, incluindo CodeBuild, Java Code Geeks e DZone.)
Fundamentos de Design de Banco de Dados. 10 coisas que você absolutamente precisa fazer
por Michelle A. Poolet | SQL ServerPro | 1º de março de 2011
Uma parte das dicas da Sra. Poolet é bastante padrão e pode ser encontrada em muitos outros recursos, mas também existem alguns pontos bastante incomuns. Entre seus pontos genéricos, ela promove o uso de subtipos e supertipos (com os quais concordo plenamente), pois espelham o design orientado a objetos e podem ser facilmente compreendidos pelos desenvolvedores. Do artigo dela:
Não tenha medo de incluir entidades de supertipo e subtipo em seu design no CDM e em diante. Os subtipos representam classificações ou categorias do supertipo... Entidades são representadas como subtipos quando são necessárias mais de uma única palavra ou frase para categorizar a entidade.
Se uma categoria tiver vida própria, com atributos separados que descrevem como a categoria se parece e se comporta e relacionamentos separados com outras entidades, é hora de invocar a estrutura supertipo/subtipo . A falha em fazer isso inibirá uma compreensão completa dos dados e das regras de negócios que orientam a coleta de dados.
Alguns de seus comentários fazem referência específica ao MS SQL Server, mesmo que os comentários sejam, na verdade, questões genéricas. Um ponto principal que a Sra. Poolet faz é muito específico do SQL Server:“Armazenar código que toca os dados de um banco de dados como um procedimento armazenado”.
Isso é bom se você planeja oferecer suporte apenas a um único sistema de gerenciamento de banco de dados, como o SQL Server. Mas para implementações portáteis, isso não seria um bom conselho. Geralmente, eu projeto para portabilidade para pelo menos dois sistemas de gerenciamento com suporte a linguagem de procedimento armazenado diferente. Portanto, eu evitaria essa prática.
Este artigo é mais útil para pessoas que desenvolvem para SQL Server e se concentram no mercado americano (em vez de um sistema internacional). Como uma americana morando no exterior, no entanto, descobri que alguns de seus exemplos são um pouco “centrados nos EUA”. Por exemplo, um não americano pode não entender o que um Zip+4 domínio é e, portanto, não entenderia por que esse domínio deve ter uma característica NOT NULL.
Para ilustrar isso, fiz um modelo de dados para ambos os endereços americanos não americanos. Assumiremos que nosso modelo de dados pode exigir que as entidades sejam vinculadas a mais de um endereço:por exemplo, um para cobrança, outro para envio. O primeiro endereço seria associado a uma forma de pagamento; nesse caso, o endereço seria usado para verificar seu direito de autorizar esse pagamento. O endereço de entrega, obviamente, é onde o pedido será entregue.
Vamos criar um endereço americano como parte de um modelo de banco de dados de pedidos de clientes. (Nota:este não é um modelo completo, mas um exemplo de armazenamento de pedidos de produtos.)
A Wise Coders Solutions recomenda definir campos separados para números de casas e nomes de ruas e definir esses campos como NOT NULL; isso não permitiria qualquer endereço que não tivesse um número de casa e um nome de rua. Mas e as pessoas que usam caixas postais? Seus endereços são geralmente escritos como “PO Box 123”. Devemos forçá-los a colocar o número da caixa postal como o número da casa e “caixa postal” como o nome da rua? Eu não acho.
Em vez disso, usaremos um formulário com “Address Line 1” e “Address Line 2”. Várias pessoas argumentaram contra o uso de números em nomes de campos, mas para mim esta é uma solução bastante óbvia. Além disso, defini comprimentos máximos de campo (35 e 70 caracteres) que são típicos em pagamentos internacionais.
Observe que os designs dos EUA e de fora dos EUA têm um campo para regiões dentro de um país, mas o design dos EUA exige que uma abreviação de estado de 2 caracteres seja incluída. Além disso, observe que o design dos EUA não permite endereços em outros países.
Se você tiver dúvidas sobre o uso global de seu banco de dados, precisará pensar globalmente durante a fase de design. Nossos bancos de dados estão preparados para o uso multinacional de nossos aplicativos?
Lições aprendidas com o design ruim do data warehouse
por Michelle A. Poolet | SQL ServerPro | 15 de junho de 2009
Este artigo analisa o Data Warehouse (DWH) e alguns de seus problemas de design e implementação. Há um pequeno foco no SQL Server, mas é uma visão geral bastante ortodoxa do design para data warehousing e business intelligence. Ter buy-in e criar interfaces amigáveis pode não ser a dica mais útil, mas não discordo delas – só não acho que façam parte do design DWH.
A Sra. Poolet afirma que o processo extrair-transformar-carregar (ETL) deve realizar verificações de qualidade de dados e dados potencialmente “limpos” até que haja um padrão aceitável de qualidade de dados. Na minha opinião, isso corre o risco de criar um data warehouse que não espelha adequadamente as informações extraídas do sistema de origem. A limpeza de dados deve ser realizada nos sistemas de origem. O ETL deve apenas transformar os dados para que possam ser carregados no data warehouse.
Como nota positiva, a recomendação de reciclagem ou criação de rotinas ETL reutilizáveis é altamente relevante. Além disso, concordo com a Sra. Poolet sobre a escalabilidade. Seus comentários sobre gerenciamento de risco e conformidade, particularmente a Lei Sarbanes-Oxley, parecem bastante específicos; Presumo que estes vêm de sua área de negócios.
Finalmente, ela tem uma boa lista de verificação de pontos relacionados a dimensões, tabelas de fatos e escolhas de esquema durante o projeto OLAP (processamento analítico online). Estes parecem ser muito relevantes durante o processo de design do banco de dados. Eu gostaria que esta lista fosse mais longa, com mais detalhes ou exemplos, mas fiquei feliz que essas dicas práticas foram incluídas.
11 regras importantes de design de banco de dados que eu sigo
por Shivprasad Koirala | Projeto de Código | 25 de fevereiro de 2014
Eu realmente gosto do conselho sensato e claro no início deste artigo. Conceitos como “considerar a natureza do aplicativo” e “dividir seus dados em partes lógicas” estão no local. Essas são ajudas importantes ao criar seu modelo de dados. Como diz o Sr. Koirala:
Quando você inicia o design do banco de dados, a primeira coisa a analisar é a natureza do aplicativo para o qual você está projetando, seja ele transacional ou analítico. Você encontrará muitos desenvolvedores por padrão aplicando regras de normalização sem pensar na natureza do aplicativo e, posteriormente, entrar em problemas de desempenho e personalização.
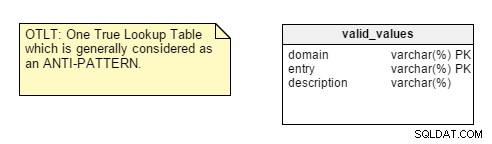
No entanto, há alguns pontos que não me deixam convencida. Por exemplo, centralize os pares Nome-Valor em uma única tabela. Esse design de One True Lookup Table (OTLT) é debatido, mas geralmente é considerado uma prática ruim ou pelo menos anti-padrão no design. Estou do lado do grupo anti-OTLT; essas tabelas apresentam vários problemas. Podemos empregar a analogia do desenvolvimento de software usando um único enumerador para representar todos os valores possíveis de todas as constantes possíveis como equivalente a essa prática.
Para lembrá-lo, a tabela OTLT normalmente se parece com isso, com entradas de vários domínios lançadas na mesma tabela. Concordo com o grupo anti-OTLT; essas tabelas apresentam vários problemas.
Além disso, alguns pontos parecem um pouco esotéricos, como “observar dados separados por separadores”. Embora este seja um ponto válido, não é um que eu costumo pensar ao criar um novo modelo de dados.
O Sr. Koirala tem alguns itens de design OLAP que geralmente não são mencionados em outras listas de práticas recomendadas. Sua inclusão de um design de dimensão e fato pode ser útil, mas também pode ser perigosa para designers iniciantes.
Este artigo é interessante se você estiver migrando do início para uma modelagem de dados mais avançada. Isso o ajudará a considerar a natureza analítica versus transacional de seus modelos futuros.
Big Data:cinco dicas simples de desempenho de design de banco de dados
por Dave Beulke | davebeulke. com | 19 de março de 2013

O artigo do Sr. Beulke analisa dicas de design com foco no desempenho. Ele mostra como verificar a normalização adequada:nem muito nem muito pouco. (A normalização excessiva terá um impacto negativo no desempenho do banco de dados.)
Além disso, usar chaves comerciais naturais em vez de chaves primárias geradas é um bom conselho quando você deseja evitar a conversão de uma chave comercial para um ID de linha gerado para cada acesso ao banco de dados.
Usar padrões de nomenclatura e tipos de coluna adequados também é um bom conselho. O ponto sobre o uso excessivo de colunas anuláveis é sólido:criar todas as colunas como anuláveis é um erro, mas definir uma coluna como anulável pode ser necessário para uma função de negócios específica. Nas palavras do próprio autor:
Todas as colunas são NULLable? Dentro das definições das colunas do banco de dados, bons domínios de dados, intervalos e valores devem ser analisados, avaliados e prototipados para o aplicativo de negócios. Ter bons valores padrão, um escopo limitado de valores e sempre um valor são os melhores para o desempenho e a lógica do aplicativo. Colunas NULLable são boas apenas quando os dados são desconhecidos ou ainda não têm um valor. Os dados de data de morte de alguém são o exemplo clássico de uma coluna NULLable porque são desconhecidos, a menos que já estejam mortos. Certifique-se de que seu design de banco de dados represente dados conhecidos e use apenas um mínimo de colunas NULLable.
As dicas do Sr. Beulke são todas muito sólidas, mesmo que um pouco sem originalidade. Eu teria gostado de mais itens de Big Data – afinal, esse é o título do artigo. No final, senti que o artigo carecia de profundidade e amplitude e não tinha exemplos para esclarecer os pontos. No entanto, ele oferece conselhos valiosos relacionados à normalização e chaves naturais.
10 práticas recomendadas de design de banco de dados
por Ann Todos | Aplicativos Corporativos Hoje | 15 de julho de 2014
Dez práticas recomendadas de design de banco de dados são apresentadas como uma série de slides. Ms. All inclui informações de desenvolvedores experientes, como Michael Blaha. Ele incentiva a reutilização de suas melhores práticas e padrões. Estes são entendidos e comprovados e, nesse sentido, preferíveis a modelos de dados que devem ser criados do zero. Do artigo da Sra. All:
Por exemplo, muitas vezes faço engenharia reversa de bancos de dados – bancos de dados de um aplicativo a ser substituído, bem como bancos de dados de aplicativos relacionados. Esses bancos de dados existentes geralmente não têm um modelo de dados disponível. Mas um modelo de dados está implícito no esquema de banco de dados e pode ser extraído pelo menos parcialmente com técnicas de engenharia reversa de banco de dados. … Existem representações de dados testadas e comprovadas que ocorrem com frequência e não precisam ser recriadas do zero.
Esta é uma pequena apresentação de slides que os designers de modelos de dados podem examinar rapidamente e coletar as dicas que ressoam com eles. Para mim, a dica de reutilização é uma das minhas favoritas.
Práticas recomendadas de banco de dados
por Cunningham &Cunningham, Inc.
Essas práticas recomendadas começaram bem, mas depois entraram em alguns problemas complicados. Não estou convencido de que o conselho oferecido esteja sempre no ponto.
No lado positivo, há descrições muito agradáveis de “melhores práticas” controversas, como sempre usar chaves substitutas geradas automaticamente e usar ou evitar procedimentos armazenados. Como um exemplo:
Um autor anterior escreveu:"Geralmente, evite PrimaryKeys que tenham significado. Nomes não são únicos, e muitos identificadores aparentemente únicos, como números de seguro social, na verdade não são, devido a problemas de confiabilidade de dados do mundo real." Em suma, esta é uma recomendação para sempre ter uma SurrogateKey gerada automaticamente (normalmente numérica) em vez de uma LogicalKey baseada em domínio. Esta é uma resposta bastante adequada para um problema complexo, embora seja suficiente em vários casos e seja pelo menos preferível a não ter nenhuma chave primária.
(Nota do autor:não consegui encontrar este “autor anterior” ao pesquisar essas duas frases no Google.)
E um link para um artigo resumido sobre os principais argumentos de cada lado do debate Auto Keys versus Domain Keys é fornecido.
Por outro lado, achei as dicas para “dividir sistema operacional, dados e logar em diferentes discos físicos” e “usar RAID” um pouco misteriosas. Não me interpretem mal – este é provavelmente um bom conselho em algumas circunstâncias, mas eu não o incluiria na minha lista dos 20 melhores.
Dicas de design de banco de dados
por Wise Coders
Existem algumas dicas únicas e interessantes nesta coleção, como uma recomendação para fechar as transações o mais rápido possível.
No entanto, não concordo completamente com todas as dicas de design aqui. Por exemplo:
Presume-se um campo 'Status' com valores 'Ativo', 'Inativo' e 'Inativo'. Você pode salvar o valor como o nome completo, mas isso pode ser ineficiente. Armazenar uma enumeração ou um char(1) com valores possíveis 'a', 'i', 'd', por exemplo, usará menos espaço no banco de dados.
Isso é controverso, para dizer o mínimo – outras fontes recomendam não empregar “códigos secretos” como este. Em vez disso, use uma tabela separada para armazenar esses códigos de status.
Além disso, as estatísticas associadas às dicas de desempenho são questionáveis e não há exemplos no artigo.
Em uma nota positiva, esta é uma boa lista curta de dicas que devem ser acessíveis a modeladores de banco de dados intermediários.
Recursos para designers de banco de dados iniciantes
Agora vamos examinar alguns artigos para aqueles que estão apenas começando no design de banco de dados.
Noções básicas de um bom design de banco de dados no desenvolvimento da Web
por Kayla Knight | Onextrapixel.com | 17 de março de 2011
Aqui ficamos um pouco mais avançados, com conselhos que vão desde a funcionalidade até as ferramentas de modelagem.
A Sra. Knight nos guia através de uma introdução ao design de banco de dados. Seu artigo é interessante porque enfatiza bancos de dados para desenvolvimento web. Mesmo assim, seus pontos são bastante universais e podem ser aplicados ao design de banco de dados em muitas situações.
O artigo começa pedindo que pensemos amplamente sobre a funcionalidade, não apenas sobre o banco de dados:
Pense fora do banco de dados. Tente pensar sobre o que o site precisará fazer. Por exemplo, se for necessário um site de associação, o primeiro instinto pode ser começar a pensar em todos os dados que cada usuário precisará armazenar. Esquece, isso é para depois. Em vez disso, anote que os usuários e suas informações precisarão ser armazenados no banco de dados e o que mais? O que esses membros precisarão fazer no site? Eles farão postagens, carregarão arquivos ou fotos ou enviarão mensagens? Em seguida, o banco de dados precisará de um local para arquivos/fotos, postagens e mensagens.
A partir daí, a Sra. Knight leva o leitor para as ferramentas de design de banco de dados e as etapas envolvidas no processo. Seu artigo dá exemplos e links para outros recursos.
Acho que este artigo seria uma ótima introdução para designers de banco de dados iniciantes e deve funcionar bem com as Geek Girls Series.
Explorando dicas de design de banco de dados
por Doug Lowe | Para Leigos
A lista de “Dummies” do Sr. Lowe é uma ampla série de dicas básicas de design. Você pode encontrar muitos deles em outros lugares, mas é útil tê-los em um só lugar. Você não encontrará nada único ou altamente controverso, exceto uma recomendação para usar procedimentos armazenados. Eu sempre questiono essa afirmação forte, pois estou muito preocupado com a portabilidade do modelo de dados para vários sistemas DBM.
Aqui está uma das dicas de bom senso do Sr. Lowe:
Evite campos com nomes como CustomerType, onde o valor do campo é uma das várias constantes que não são definidas em outro lugar no banco de dados, como R para Varejo ou W para Atacado. Você pode ter apenas esses dois tipos de clientes hoje, mas as necessidades do aplicativo podem mudar no futuro, exigindo um terceiro tipo de cliente.
Essas recomendações são mais apropriadas ao trabalhar com o SQL Server.
Cinco dicas simples de design de banco de dados
por Lamont Adams | TechRepublic | 25 de junho de 2001
A palavra-chave para este recurso é “simples”. Você pode encontrar essas informações, com mais explicações e exemplos, em outros artigos.
No entanto, o conselho do Sr. Adams de “Retirar as chaves do usuário” é um ponto interessante, raramente mencionado em outros lugares. Ele continua:
Ao decidir qual campo ou campos usar como chaves em uma tabela, sempre considere os campos que os usuários editarão. Geralmente é uma má ideia escolher um campo editável pelo usuário como chave.
O significado do Sr. Adams é que você deve considerar o requisito potencial do usuário para editar campos ao decidir quais campos usar como chaves. Eu gostaria de mais explicações sobre alternativas, como chaves sintéticas/geradas, mas o conceito é bom.
Eu discordei do ponto final. Ele recomenda um “fator de falsificação” para cada mesa que você projetar:
Não há muito pior do que descobrir, ou ser informado, que seu banco de dados “acabado” está faltando um campo para uma informação crucial. Em uma empresa em que trabalhei, isso era uma ocorrência tão comum que começamos a nos referir a “congelamento de banco de dados” como “descongelamento de banco de dados”.
Na minha opinião, isso é basicamente “adicionar alguns campos de texto extras ao final”. Isso parece contradizer algumas das outras dicas do Sr. Adams, especificamente aquelas relacionadas à compreensão das necessidades de negócios e ao uso de nomes significativos. Esses campos extras de falsificação seriam chamados apenas de algo como “extra1” ou “extra2”. Qual é a necessidade de negócios deles? E como são esses nomes significativos? Embora eu goste da maioria de suas dicas de design, esse “fator de fudge” não é algo que eu adira.
Design de banco de dados:menções honrosas
Obviamente, existem outros artigos que descrevem dicas de design de banco de dados e práticas recomendadas. Você pode encontrar material adicional nos seguintes links:
Design de banco de dados relacional:uma cartilha de melhores práticas | pelo Ethos Digital | 24 de dezembro de 2012
Práticas recomendadas para design de esquema de banco de dados (iniciantes) | por Jim Murphy | 28 de março de 2011
Melhores Práticas de TI:Projeto de Banco de Dados | pela Universidade de Nebraska-Lincoln
Recursos de design de banco de dados on-line:para onde você iria?
Como mencionado, esta lista definitivamente não pretende ser um exame exaustivo de todos os artigos de design de banco de dados na Internet. Em vez disso, identificamos vários artigos que consideramos úteis ou que têm um foco específico que você pode achar útil.
Sinta-se à vontade para recomendar artigos adicionais.