No ano passado, publiquei uma dica chamada Melhorar a eficiência do SQL Server alternando para INSTEAD OF Triggers.
A grande razão pela qual costumo favorecer um gatilho INSTEAD OF, particularmente nos casos em que espero muitas violações da lógica de negócios, é que parece intuitivo que seria mais barato impedir uma ação completamente do que ir em frente e executá-la (e log it!), apenas para usar um gatilho AFTER para excluir as linhas ofensivas (ou reverter toda a operação). Os resultados mostrados nessa dica demonstraram que esse era, de fato, o caso – e suspeito que seriam ainda mais pronunciados com mais índices não clusterizados afetados pela operação.
No entanto, isso foi em um disco lento e em um CTP inicial do SQL Server 2014. Ao preparar um slide para uma nova apresentação que farei este ano sobre gatilhos, descobri que em uma versão mais recente do SQL Server 2014 – combinado com hardware atualizado – era um pouco mais complicado demonstrar o mesmo delta no desempenho entre um gatilho AFTER e INSTEAD OF. Então comecei a descobrir por que, mesmo sabendo imediatamente que isso daria mais trabalho do que eu já tinha feito para um único slide.
Uma coisa que quero mencionar é que os gatilhos podem usar
tempdb de maneiras diferentes, e isso pode explicar algumas dessas diferenças. Um gatilho AFTER usa o armazenamento de versão para as pseudo-tabelas inseridas e excluídas, enquanto um gatilho INSTEAD OF faz uma cópia desses dados em uma tabela de trabalho interna. A diferença é sutil, mas vale a pena apontar. As Variáveis
Vou testar vários cenários, incluindo:
- Três acionadores diferentes:
- Um gatilho AFTER que exclui linhas específicas que falham
- Um gatilho AFTER que reverte toda a transação se alguma linha falhar
- Um gatilho INSTEAD OF que insere apenas as linhas que passam
- Diferentes modelos de recuperação e configurações de isolamento de instantâneos:
- CHEIO com SNAPSHOT ativado
- CHEIO com SNAPSHOT desativado
- SIMPLE com SNAPSHOT ativado
- SIMPLE com SNAPSHOT desativado
- Diferentes layouts de disco*:
- Dados no SSD, faça login no HDD de 7200 RPM
- Dados no SSD, faça login no SSD
- Dados no HDD de 7.200 RPM, faça login no SSD
- Dados em HDD de 7200 RPM, faça login em HDD de 7200 RPM
- Diferentes taxas de falha:
- 10%, 25% e 50% de taxa de falha em:
- Inserção de lote único de 20.000 linhas
- 10 lotes de 2.000 linhas
- 100 lotes de 200 linhas
- 1.000 lotes de 20 linhas
- 20.000 inserções singleton
*tempdbé um único arquivo de dados em um disco lento de 7200 RPM. Isso é intencional e visa amplificar quaisquer gargalos causados pelos vários usos detempdb. Pretendo revisitar este teste em algum momento quandotempdbestá em um SSD mais rápido. - 10%, 25% e 50% de taxa de falha em:
Ok, TL;DR já!
Se você quer apenas saber os resultados, pule para baixo. Tudo no meio é apenas um pano de fundo e uma explicação de como configurei e executei os testes. Não estou com o coração partido porque nem todos estarão interessados em todas as minúcias.
O cenário
Para esse conjunto específico de testes, o cenário da vida real é aquele em que um usuário escolhe um nome de tela e o gatilho é projetado para detectar casos em que o nome escolhido viola algumas regras. Por exemplo, não pode ser qualquer variação de "ninny-muggins" (você certamente pode usar sua imaginação aqui).
Eu criei uma tabela com 20.000 nomes de usuários exclusivos:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Então eu criei uma tabela que seria a fonte para meus "nomes impertinentes" para verificar. Neste caso, é apenas
ninny-muggins-00001 através de ninny-muggins-10000 :USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x; Criei essas tabelas no
model banco de dados para que toda vez que eu criar um banco de dados, ele exista localmente, e pretendo criar muitos bancos de dados para testar a matriz de cenários listada acima (em vez de apenas alterar as configurações do banco de dados, limpar o log etc.). Observe que, se você criar objetos no modelo para fins de teste, certifique-se de excluir esses objetos quando terminar. Como um aparte, vou deixar intencionalmente violações de chave e outros erros de manipulação de fora disso, fazendo a suposição ingênua de que o nome escolhido é verificado quanto à exclusividade muito antes de a inserção ser tentada, mas dentro da mesma transação (assim como o nome escolhido verificação contra a tabela de nomes impertinentes poderia ter sido feita com antecedência).
Para dar suporte a isso, também criei as três tabelas a seguir quase idênticas em
model , para fins de isolamento de teste:USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
E os três gatilhos a seguir, um para cada tabela:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Você provavelmente gostaria de considerar o tratamento adicional para notificar o usuário de que sua escolha foi revertida ou ignorada – mas isso também é deixado de fora para simplificar.
A configuração do teste
Criei dados de amostra representando as três taxas de falha que eu queria testar, alterando 10% para 25 e depois 50, e adicionando essas tabelas também ao
model :USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Cada tabela tem 20.000 linhas, com uma combinação diferente de nomes que serão aprovados e reprovados, e a coluna do número da linha facilita a divisão dos dados em diferentes tamanhos de lote para diferentes testes, mas com taxas de falha repetíveis para todos os testes.
Claro que precisamos de um lugar para capturar os resultados. Optei por usar um banco de dados separado para isso, executando cada teste várias vezes, simplesmente capturando a duração.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Eu preenchi o
dbo.Tests table com o script a seguir, para que eu pudesse executar diferentes partes para configurar os quatro bancos de dados para corresponder aos parâmetros de teste atuais. Observe que D:\ é um SSD, enquanto G:\ é um disco de 7200 RPM:TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Então foi simples executar todos os testes várias vezes:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10 No meu sistema, isso levou cerca de 6 horas, portanto, esteja preparado para deixar isso seguir seu curso ininterrupto. Além disso, verifique se você não tem conexões ativas ou janelas de consulta abertas no
model banco de dados, caso contrário, você pode receber este erro quando o script tentar criar um banco de dados:Msg 1807, Level 16, State 3
Não foi possível obter bloqueio exclusivo no banco de dados 'model'. Repita a operação mais tarde.
Resultados
Há muitos pontos de dados a serem observados (e todas as consultas usadas para derivar os dados são referenciadas no Apêndice). Lembre-se de que cada duração média indicada aqui é superior a 10 testes e está inserindo um total de 100.000 linhas na tabela de destino.
Gráfico 1 – Agregados gerais
O primeiro gráfico mostra as agregações gerais (duração média) para as diferentes variáveis isoladamente (portanto, *todos* os testes usando um gatilho AFTER que exclui, *todos* os testes usando um gatilho AFTER que reverte etc.).
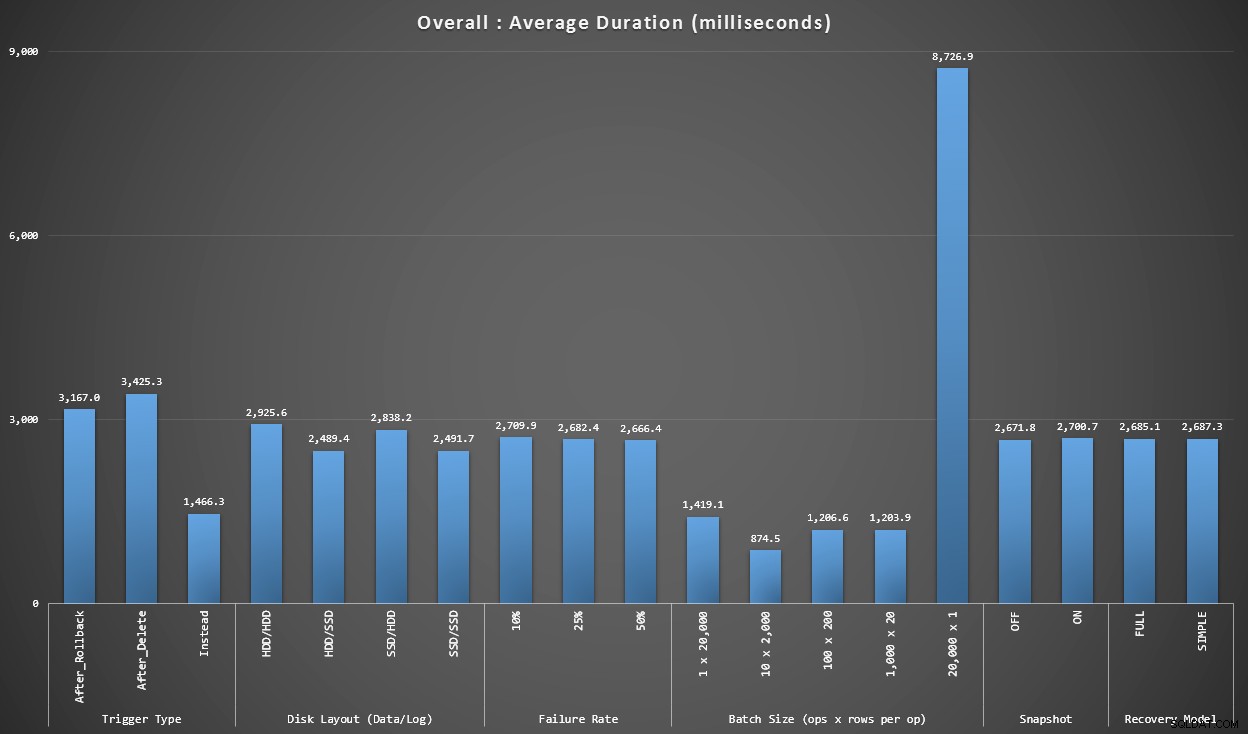
Duração média, em milissegundos, para cada variável isoladamente
Algumas coisas saltam para nós imediatamente:
- O acionador INSTEAD OF aqui é duas vezes mais rápido que os dois acionadores AFTER.
- Ter o log de transações no SSD fez um pouco de diferença. Localização do arquivo de dados muito menos.
- O lote de 20.000 inserções singleton foi de 7 a 8 vezes mais lento do que qualquer outra distribuição de lote.
- A inserção de lote único de 20.000 linhas foi mais lenta do que qualquer uma das distribuições não singleton.
- A taxa de falhas, o isolamento de instantâneos e o modelo de recuperação tiveram pouco ou nenhum impacto no desempenho.
Gráfico 2 – 10 melhores no geral
Este gráfico mostra os 10 resultados mais rápidos quando todas as variáveis são consideradas. Esses são todos os gatilhos INSTEAD OF em que a maior porcentagem de linhas falha (50%). Surpreendentemente, o mais rápido (embora não muito) tinha dados e log no mesmo HDD (não SSD). Há uma mistura de layouts de disco e modelos de recuperação aqui, mas todos os 10 tinham o isolamento de instantâneo ativado e os 7 principais resultados envolveram o tamanho do lote de 10 x 2.000 linhas.
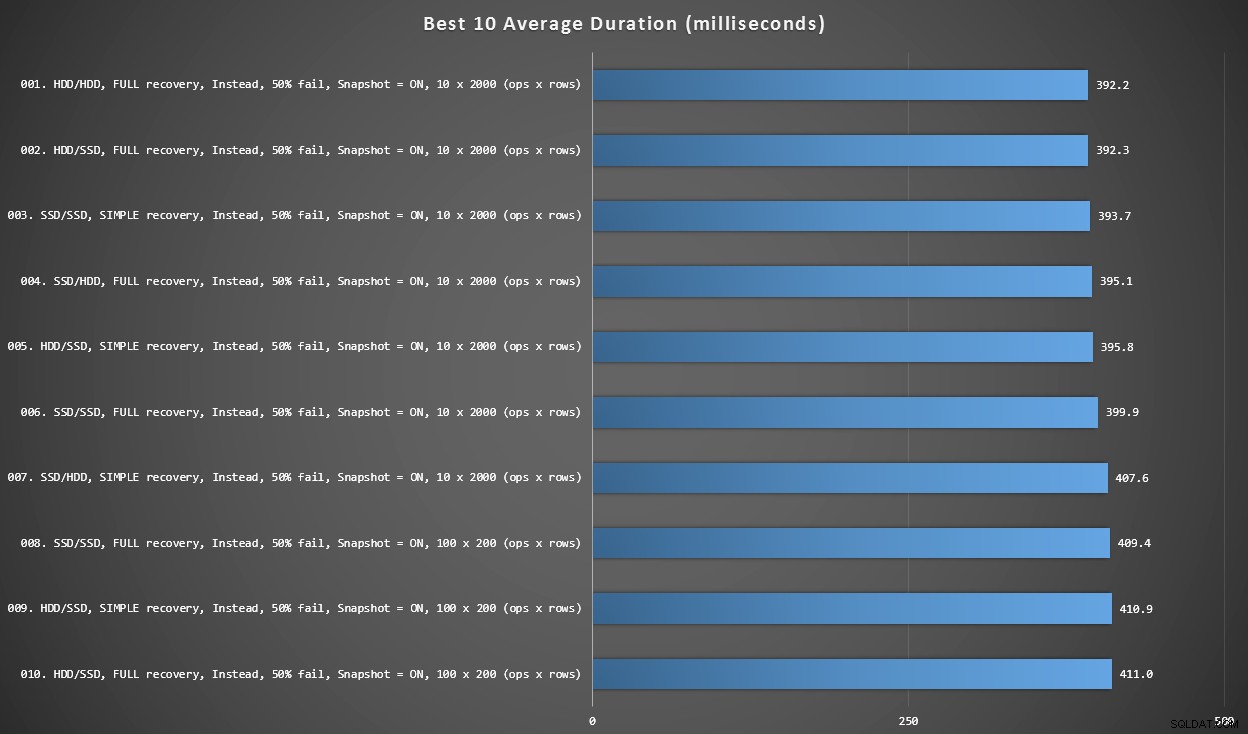
As 10 melhores durações, em milissegundos, considerando todas as variáveis
O gatilho AFTER mais rápido – uma variante ROLLBACK com 10% de taxa de falha no tamanho do lote de 100 x 200 linhas – veio na posição #144 (806 ms).
Gráfico 3 – Piores 10 no geral
Este gráfico mostra os 10 resultados mais lentos quando todas as variáveis são consideradas; todas são variantes AFTER, todas envolvem as 20.000 inserções singleton e todas têm dados e log no mesmo disco rígido lento.
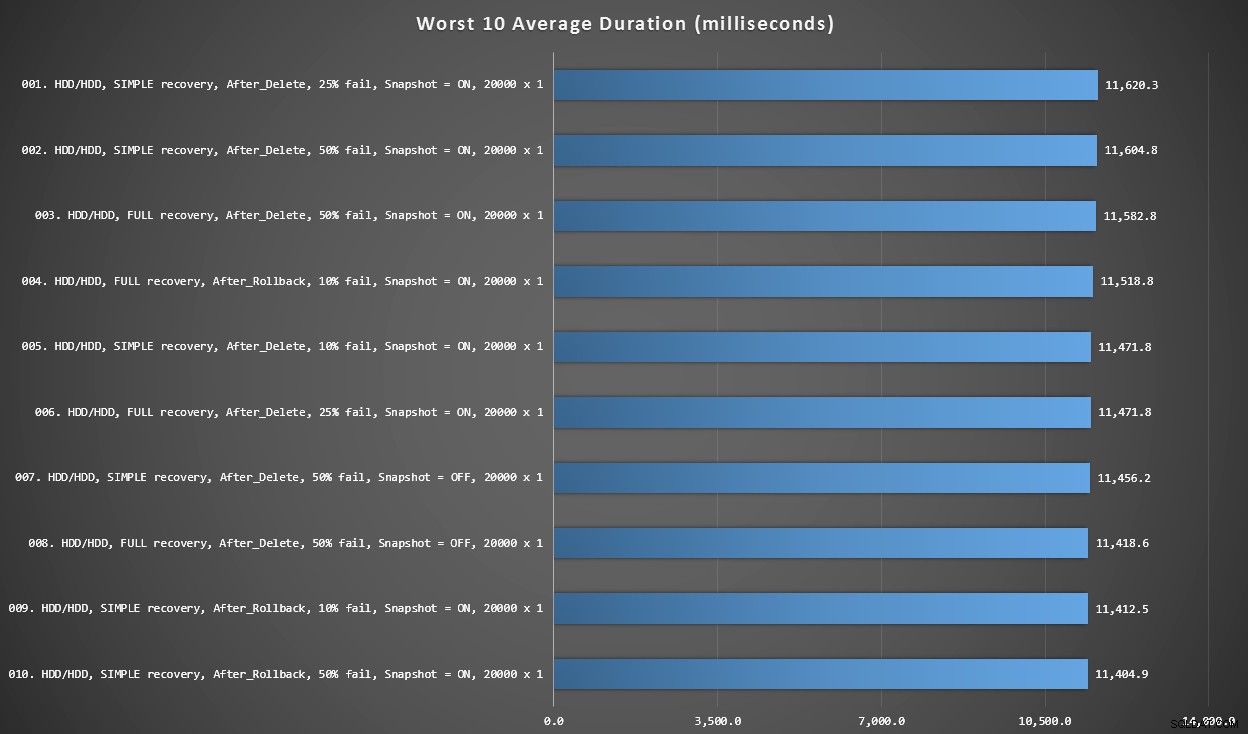
Piores 10 durações, em milissegundos, considerando todas as variáveis
O teste INSTEAD OF mais lento foi na posição #97, a 5.680 ms – um teste de inserção de 20.000 singletons em que 10% falharam. É interessante também observar que nem um único gatilho AFTER usando o tamanho de lote de inserção de 20.000 singletons se saiu melhor – na verdade, o 96º pior resultado foi um teste AFTER (delete) que chegou a 10.219 ms – quase o dobro do próximo resultado mais lento.
Gráfico 4 – Tipo de disco de registro, inserções singleton
Os gráficos acima nos dão uma ideia aproximada dos maiores pontos problemáticos, mas eles estão muito ampliados ou não são ampliados o suficiente. Este gráfico filtra os dados com base na realidade:na maioria dos casos, esse tipo de operação será uma inserção singleton. Eu pensei em dividi-lo pela taxa de falha e pelo tipo de disco em que o log está, mas apenas observe as linhas em que o lote é composto de 20.000 inserções individuais.
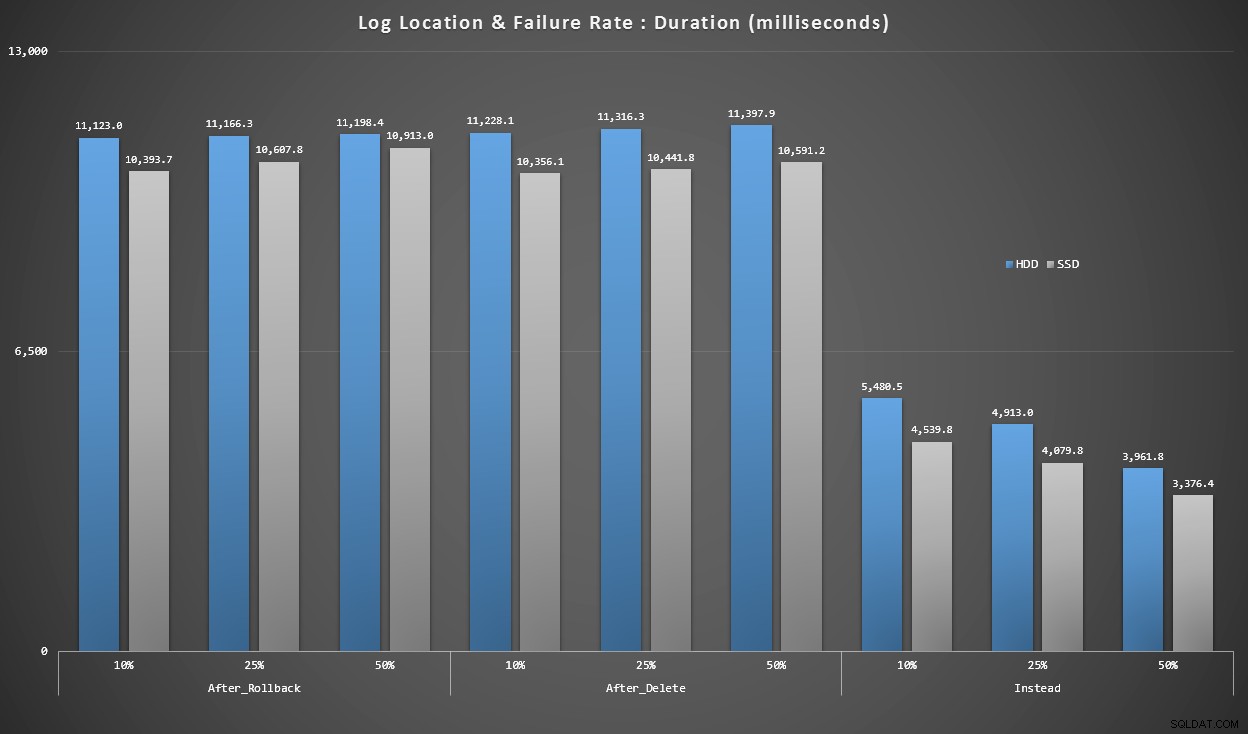
Duração, em milissegundos, agrupada por taxa de falha e localização do log, para 20.000 inserções individuais
Aqui vemos que todos os gatilhos AFTER estão em média no intervalo de 10 a 11 segundos (dependendo da localização do log), enquanto todos os gatilhos INSTEAD OF estão bem abaixo da marca de 6 segundos.
Conclusão
Até agora, parece claro para mim que o gatilho INSTEAD OF é um vencedor na maioria dos casos – em alguns casos mais do que em outros (por exemplo, à medida que a taxa de falha aumenta). Outros fatores, como o modelo de recuperação, parecem ter muito menos impacto no desempenho geral.
Se você tiver outras ideias sobre como dividir os dados, ou gostaria de uma cópia dos dados para realizar seu próprio corte e corte, por favor me avise. Se você quiser ajuda para configurar este ambiente para que possa executar seus próprios testes, também posso ajudar.
Embora este teste mostre que os gatilhos INSTEAD OF definitivamente valem a pena ser considerados, não é toda a história. Eu literalmente juntei esses gatilhos usando a lógica que achei que fazia mais sentido para cada cenário, mas o código do gatilho – como qualquer instrução T-SQL – pode ser ajustado para planos ideais. Em um post de acompanhamento, vou dar uma olhada em uma potencial otimização que pode tornar o gatilho AFTER mais competitivo.
Apêndice
Consultas usadas para a seção Resultados:
Gráfico 1 – Agregados gerais
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Gráfico 2 e 3 – 10 melhores e piores
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Gráfico 4 – Tipo de disco de registro, inserções singleton
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate; 


