Estou no processo de organizar minha casa (muito tarde no verão para tentar passar como limpeza de primavera). Você sabe, limpar armários, vasculhar os brinquedos das crianças e organizar o porão. É um processo doloroso. Quando nos mudamos para nossa casa há 10 anos, tínhamos muito espaço. Agora sinto que há coisas em todos os lugares, e fica mais difícil encontrar o que realmente estou procurando e leva cada vez mais tempo para limpar e organizar.
Isso soa como qualquer banco de dados que você gerencia?
Muitos clientes com os quais trabalhei lidam com a limpeza de dados como uma reflexão tardia. No momento da implementação, todos querem salvar tudo. “Nunca sabemos quando podemos precisar.” Depois de um ou dois anos, alguém percebe que há muitas coisas extras no banco de dados, mas agora as pessoas têm medo de se livrar delas. “Precisamos verificar com o Jurídico para ver se podemos excluí-lo.” Mas ninguém verifica com o Jurídico, ou se alguém o faz, o Jurídico volta aos proprietários da empresa para perguntar o que manter, e então o projeto é interrompido. “Não podemos chegar a um consenso sobre o que pode ser excluído.” O projeto é esquecido e, depois de dois ou quatro anos, o banco de dados é de repente um terabyte, difícil de gerenciar, e as pessoas culpam todos os problemas de desempenho no tamanho do banco de dados. Você ouve as palavras “particionamento” e “banco de dados de arquivamento” e, às vezes, apenas exclui um monte de dados, o que tem seus próprios problemas.
Idealmente, você deve decidir sobre sua estratégia de eliminação antes da implementação ou nos primeiros seis a doze meses de entrada em operação. Mas já que passamos desse estágio, vamos ver o impacto que esses dados extras podem ter.
Metodologia de teste
Para definir o cenário, fiz uma cópia do banco de dados Credit e o restaurei na minha instância do SQL Server 2012. Eu eliminei os três índices não clusterizados existentes e adicionei dois dos meus próprios:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Em seguida, aumentei o número de linhas na tabela para 14,4 milhões, reinserindo o conjunto original de linhas várias vezes, modificando ligeiramente as datas:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Por fim, configurei um equipamento de teste para executar uma série de instruções no banco de dados quatro vezes cada. As declarações seguem abaixo:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Antes de cada instrução que eu executei
DBCC DROPCLEANBUFFERS; GO
para limpar o pool de buffers. Obviamente, isso não é algo para ser executado em um ambiente de produção. Eu fiz isso aqui para fornecer um ponto de partida consistente para cada teste.
Após cada execução, aumentei o tamanho da tabela dbo.charge inserindo as 14,4 milhões de linhas com as quais comecei, mas aumentei o charge_dt em um ano para cada execução. Por exemplo:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Após a adição de 14,4 milhões de linhas, executei novamente o equipamento de teste. Repeti isso seis vezes, essencialmente adicionando seis “anos” de dados. A tabela dbo.charge começou com dados de 1999 e, após as inserções repetidas, continha dados até 2005.
Resultados
Os resultados das execuções podem ser vistos aqui:
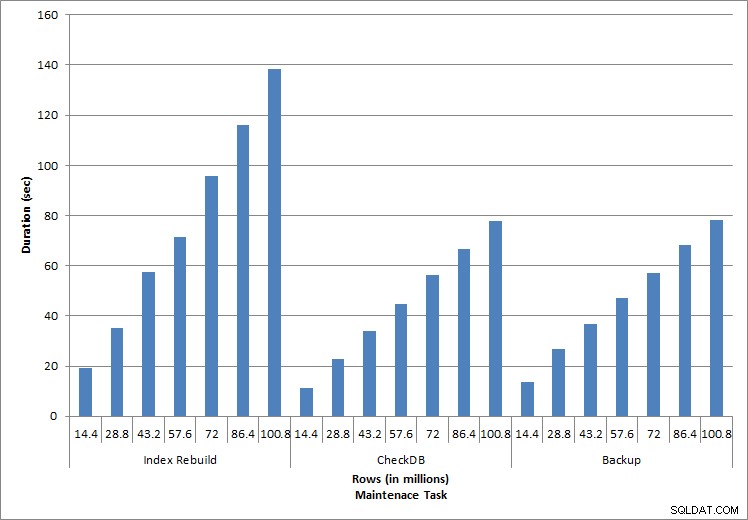
Duração para tarefas de manutenção
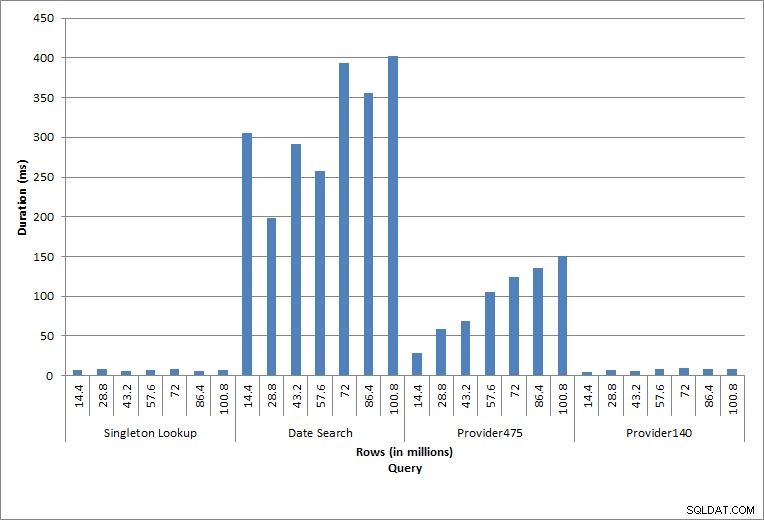
Duração das consultas
As instruções individuais executadas refletem a atividade típica do banco de dados. Reconstruções de índice, verificações de integridade e backups fazem parte da manutenção regular do banco de dados. As consultas na tabela de cobrança representam uma pesquisa singleton, bem como três variações de varreduras de intervalo específicas para os dados na tabela.
Recriações de índice, CHECKDB e backups
Conforme esperado para as tarefas de manutenção, os valores de duração e de E/S aumentaram à medida que mais linhas foram adicionadas ao banco de dados. O tamanho do banco de dados aumentou em um fator de 10 e, embora as durações não tenham aumentado na mesma proporção, foi observado um aumento consistente. Cada tarefa de manutenção levou inicialmente menos de 20 segundos para ser concluída, mas à medida que mais linhas foram adicionadas, a duração das tarefas aumentou para quase 1 minuto e 20 segundos para 100 milhões de linhas (e para mais de 2 minutos para a reconstrução do índice). Isso reflete o tempo adicional necessário para o SQL Server concluir a tarefa devido a dados adicionais.
Pesquisa de singleton
A consulta em dbo.charge para um charge_no específico sempre produzia uma linha – e teria produzido uma linha independentemente do valor usado, pois charge_no é uma identidade única. Há variação mínima para esta pesquisa. À medida que as linhas são continuamente adicionadas à tabela, o índice pode aumentar em profundidade em um ou dois níveis (mais à medida que a tabela se torna mais ampla), adicionando, portanto, alguns IOs, mas esta é uma pesquisa singleton com muito poucos IOs.
Verificações de intervalo
A consulta de um intervalo de datas (charge_dt) foi modificada após cada inserção para pesquisar os dados do ano mais recente de julho (por exemplo, '2005-07-01' a '2005-07-01' para o último conjunto de testes), mas retornou pouco mais de 1,2 milhão de linhas de cada vez. Em um cenário do mundo real, não esperaríamos que o mesmo número de linhas fosse retornado para o mesmo mês, ano após ano, nem esperaríamos que o mesmo número de linhas fosse retornado para cada mês em um ano. Mas a contagem de linhas pode permanecer no mesmo intervalo entre os meses, com pequenos aumentos ao longo do tempo. Existem flutuações na duração dessa consulta, mas uma revisão dos dados de E/S capturados de sys.dm_io_virtual_file_stats mostra consistência no número de leituras.
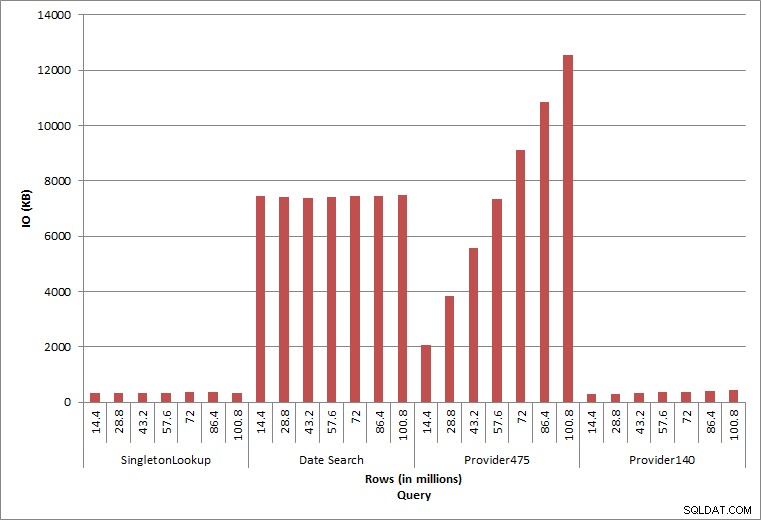
E/S de consulta
As duas consultas finais, para dois valores diferentes de provider_no, mostram o verdadeiro efeito de manter os dados. Na tabela dbo.charge inicial, o provider_no 475 tinha mais de 126.000 linhas e o provider_no 140 tinha mais de 1.700 linhas. Para cada 14,4 milhões de linhas adicionadas, aproximadamente o mesmo número de linhas para cada provider_no foi adicionado. Em um ambiente de produção, esse tipo de distribuição de dados não é incomum, e as consultas para esses dados podem ter um bom desempenho nos primeiros anos da solução, mas podem degradar com o tempo à medida que mais linhas são adicionadas. A duração da consulta aumenta em um fator de cinco (de 31 ms para 153 ms) entre a execução inicial e final para provider_no 475. Embora esse impacto possa não parecer significativo, observe o aumento paralelo no IO (acima). Se esta for uma consulta executada com alta frequência e/ou houver consultas semelhantes executadas com frequência regular, a carga adicional pode aumentar e afetar o uso geral dos recursos. Além disso, considere o impacto ao trabalhar com tabelas que têm bilhões de linhas e são usadas em consultas com junções complexas e o impacto em suas tarefas de manutenção regulares – e extremamente críticas. Por fim, leve em consideração o tempo de recuperação. Seu plano de recuperação de desastres deve ser baseado em tempos de restauração e, à medida que o tamanho do banco de dados aumenta, o banco de dados levará mais tempo para ser restaurado em sua totalidade. Se você não estiver testando e cronometrando suas restaurações regularmente, a recuperação de um desastre pode demorar mais do que você pensava.
Resumo
Os exemplos mostrados aqui são ilustrações simples do que pode acontecer quando uma estratégia de arquivamento de dados não é determinada durante a implementação do banco de dados e há muitos outros cenários para explorar e testar. Dados antigos que raramente são acessados, ou nunca, afetam mais do que apenas o espaço em disco. Isso pode afetar o desempenho da consulta e a duração das tarefas de manutenção. Como um DBA gerenciando vários bancos de dados em uma instância, um banco de dados que contém dados históricos pode afetar o desempenho e as tarefas de manutenção de outros bancos de dados. Além disso, se os relatórios forem executados em relação a dados históricos, isso pode causar estragos no ambiente OLTP já ocupado.
Desde o início, é fundamental que a vida útil dos dados em um banco de dados seja determinada e um plano de ação implementado. Para algumas soluções, é necessário manter todos os dados para sempre. Nesse caso, empregue estratégias para manter o tamanho do banco de dados gerenciável, por exemplo:arquive os dados em uma tabela separada ou banco de dados separado regularmente. Caso os dados não precisem ser armazenados por anos e anos, implemente uma estratégia de limpeza que remova os dados regularmente. Dessa forma, você pode jogar fora os brinquedos que não são mais usados, roupas que não servem mais e lixo aleatório que você não usa a cada três meses... em vez de uma vez a cada 10 anos.