A adição de um índice filtrado pode ter efeitos colaterais surpreendentes em consultas existentes, mesmo quando parece que o novo índice filtrado não tem relação alguma. Esta postagem analisa um exemplo que afeta as instruções DELETE que resulta em desempenho ruim e aumento do risco de deadlock.
Ambiente de teste
A seguinte tabela será utilizada ao longo deste post:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Esta próxima instrução cria 499.999 linhas de dados de amostra:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Isso usa uma tabela Numbers como fonte de inteiros consecutivos de 1 a 499.999. Caso você não tenha um desses em seu ambiente de teste, o código a seguir pode ser usado para criar eficientemente um contendo inteiros de 1 a 1.000.000:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); A base dos testes posteriores será excluir linhas da tabela de teste para uma StartDate específica. Para tornar o processo de identificação de linhas para exclusão mais eficiente, adicione este índice não clusterizado:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Os dados de amostra
Depois que essas etapas forem concluídas, a amostra ficará assim:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID; 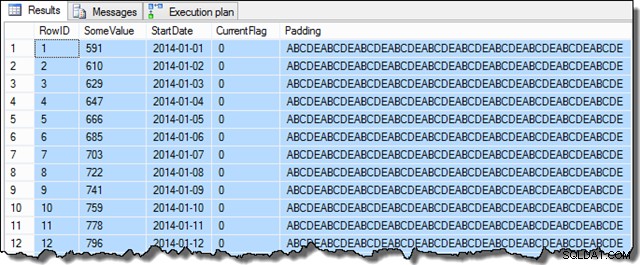
Os dados da coluna SomeValue podem ser ligeiramente diferentes devido à geração pseudo-aleatória, mas essa diferença não é importante. No geral, os dados de amostra contêm 16.129 linhas para cada uma das 31 datas StartDate em janeiro de 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate; 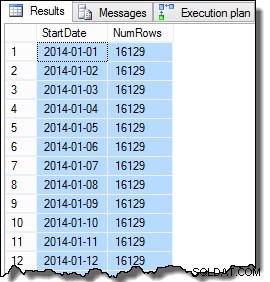
A última etapa que precisamos realizar para tornar os dados um pouco realistas é definir a coluna CurrentFlag como true para o RowID mais alto para cada StartDate. O script a seguir realiza essa tarefa:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; O plano de execução para esta atualização apresenta uma combinação Segment-Top para localizar com eficiência o RowID mais alto por dia:

Observe como o plano de execução tem pouca semelhança com a forma escrita da consulta. Este é um ótimo exemplo de como o otimizador funciona a partir da especificação lógica do SQL, em vez de implementar o SQL diretamente. Caso você esteja se perguntando, o Eager Table Spool nesse plano é necessário para a Proteção do Dia das Bruxas.
Excluindo um dia de dados
Ok, então com as preliminares concluídas, a tarefa em mãos é excluir linhas para uma determinada StartDate. Esse é o tipo de consulta que você pode executar rotineiramente na data mais antiga em uma tabela, onde os dados chegaram ao fim de sua vida útil.
Tomando 1 de janeiro de 2014 como nosso exemplo, a consulta de exclusão de teste é simples:
DELETE dbo.Data WHERE StartDate = '20140101';
O plano de execução também é bastante simples, embora valha a pena olhar com um pouco de detalhe:

Análise do plano
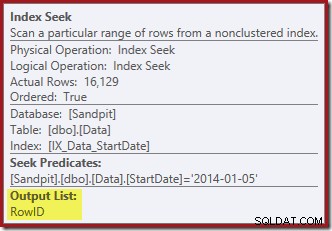
A Busca de Índice na extrema direita usa o índice não clusterizado para localizar linhas para o valor StartDate especificado. Ele retorna apenas os valores RowID que encontra, conforme a dica de ferramenta do operador confirma:
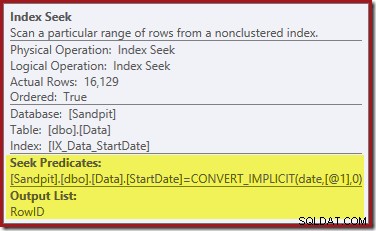
Se você estiver se perguntando como o índice StartDate consegue retornar o RowID, lembre-se de que RowID é o índice clusterizado exclusivo da tabela, portanto, ele é incluído automaticamente no índice não clusterizado StartDate.
O próximo operador no plano é o Clustered Index Delete. Isso usa o valor RowID encontrado pelo Index Seek para localizar as linhas a serem removidas.
O operador final no plano é um Index Delete. Isso remove as linhas do índice não clusterizado
IX_Data_StartDate que estão relacionados ao RowID removido pela exclusão de índice clusterizado. Para localizar essas linhas no índice não clusterizado, o processador de consulta precisa de StartDate (a chave para o índice não clusterizado). Lembre-se que o Index Seek original não retornou a Data de Início, apenas o RowID. Então, como o processador de consultas obtém a StartDate para a exclusão do índice? Nesse caso específico, o otimizador pode ter notado que o valor StartDate é uma constante e otimizado, mas não foi isso que aconteceu. A resposta é que o operador Clustered Index Delete lê o valor StartDate para a linha atual e o adiciona ao fluxo. Compare a lista de saída da exclusão de índice clusterizada mostrada abaixo, com a da busca de índice logo acima:
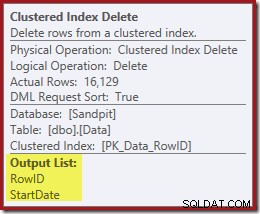
Pode parecer surpreendente ver um operador Excluir lendo dados, mas é assim que funciona. O processador de consulta sabe que terá que localizar a linha no índice clusterizado para excluí-la, portanto, pode adiar a leitura das colunas necessárias para manter os índices não clusterizados até esse momento, se puder.
Adicionar um índice filtrado
Agora imagine que alguém tem uma consulta crucial nesta tabela que está tendo um desempenho ruim. O DBA útil realiza uma análise e adiciona o seguinte índice filtrado:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; O novo índice filtrado tem o efeito desejado na consulta problemática e todos ficam satisfeitos. Observe que o novo índice não faz referência à coluna StartDate, portanto, não esperamos que isso afete nossa consulta de exclusão do dia.
Excluindo um dia com o índice filtrado em vigor
Podemos testar essa expectativa excluindo os dados pela segunda vez:
DELETE dbo.Data WHERE StartDate = '20140102';
De repente, o plano de execução mudou para uma varredura de índice em cluster paralelo:

Observe que não há um operador Index Delete separado para o novo índice filtrado. O otimizador optou por manter esse índice dentro do operador Clustered Index Delete. Isso é destacado no SQL Sentry Plan Explorer como mostrado acima ("+1 índices não clusterizados") com detalhes completos na dica de ferramenta:
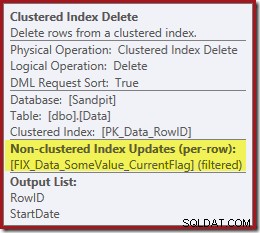
Se a tabela for grande (pense no data warehouse), essa mudança para uma varredura paralela pode ser muito significativa. O que aconteceu com o bom Index Seek em StartDate e por que um índice filtrado completamente não relacionado mudou as coisas de forma tão dramática?
Encontrando o problema
A primeira pista vem da observação das propriedades do Clustered Index Scan:
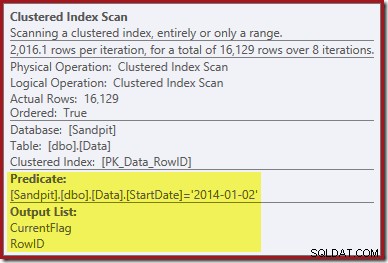
Além de localizar valores RowID para o operador Clustered Index Delete para excluir, esse operador agora está lendo os valores CurrentFlag. A necessidade dessa coluna não é clara, mas pelo menos começa a explicar a decisão de verificar:a coluna CurrentFlag não faz parte do nosso índice não clusterizado StartDate.
Podemos confirmar isso reescrevendo a consulta de exclusão para forçar o uso do índice não clusterizado StartDate:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; O plano de execução está mais próximo de sua forma original, mas agora apresenta um Key Lookup:
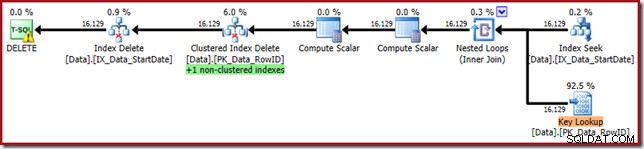
As propriedades Key Lookup confirmam que este operador está recuperando os valores CurrentFlag:
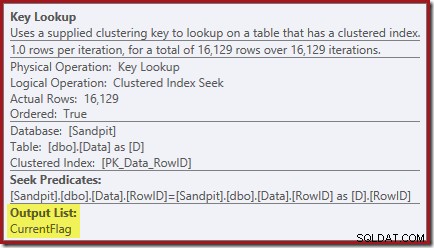
Você também deve ter notado os triângulos de advertência nos dois últimos planos. Estes são avisos de índice ausentes:
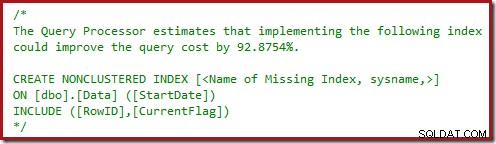
Esta é mais uma confirmação de que o SQL Server gostaria de ver a coluna CurrentFlag incluída no índice não clusterizado. A razão para a mudança para uma Verificação de Índice Agrupado paralela agora está clara:o processador de consulta decide que a verificação da tabela será mais barata do que realizar as Pesquisas de Chave.
Sim, mas por quê?
Isso tudo é muito estranho. No plano de execução original, o SQL Server conseguia ler dados de coluna extras necessários para manter índices não clusterizados no operador Clustered Index Delete. O valor da coluna CurrentFlag é necessário para manter o índice filtrado, então por que o SQL Server não o trata da mesma maneira?
A resposta curta é que pode, mas apenas se o índice filtrado for mantido em um operador de exclusão de índice separado. Podemos forçar isso para a consulta atual usando o sinalizador de rastreamento não documentado 8790. Sem esse sinalizador, o otimizador escolhe se deseja manter cada índice em um operador separado ou como parte da operação da tabela base.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
O plano de execução volta a buscar o índice não clusterizado StartDate:
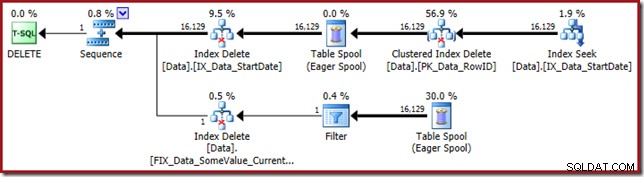
O Index Seek retorna apenas valores RowID (sem CurrentFlag):
E a exclusão de índice clusterizado lê as colunas necessárias para manter os índices não clusterizados, incluindo CurrentFlag:
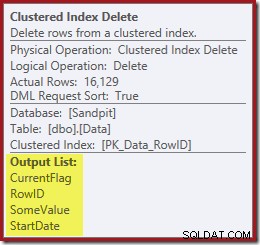
Esses dados são gravados avidamente em um spool de tabela, que é reproduzido para cada índice que precisa de manutenção. Observe também o operador Filter explícito antes do operador Index Delete para o índice filtrado.
Outro padrão a ser observado
Esse problema nem sempre resulta em uma verificação de tabela em vez de uma busca de índice. Para ver um exemplo disso, adicione outro índice à tabela de teste:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Observe que este índice não filtrada e não envolve a coluna StartDate. Agora tente uma consulta de exclusão de dia novamente:
DELETE dbo.Data WHERE StartDate = '20140104';
O otimizador agora vem com este monstro:
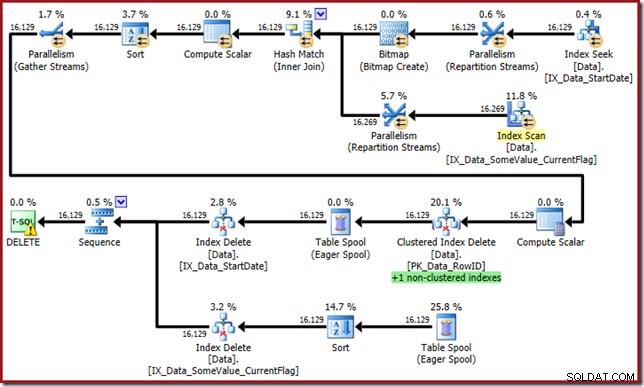
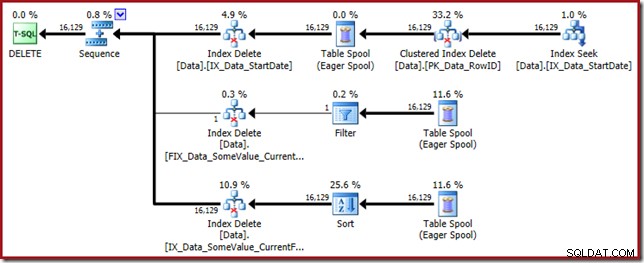
Esse plano de consulta tem um alto fator de surpresa, mas a causa raiz é a mesma. A coluna CurrentFlag ainda é necessária, mas agora o otimizador escolhe uma estratégia de interseção de índice para obtê-la em vez de uma varredura de tabela. O uso do sinalizador de rastreamento força um plano de manutenção por índice e a sanidade é novamente restaurada (a única diferença é uma repetição de spool extra para manter o novo índice):
Somente índices filtrados causam isso
Esse problema ocorre apenas se o otimizador optar por manter um índice filtrado em um operador de exclusão de índice clusterizado. Índices não filtrados não são afetados, como mostra o exemplo a seguir. A primeira etapa é descartar o índice filtrado:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Agora precisamos escrever a consulta de uma forma que convença o otimizador a manter todos os índices no Clustered Index Delete. Minha escolha para isso é usar uma variável e uma dica para diminuir as expectativas de contagem de linhas do otimizador:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); O plano de execução é:
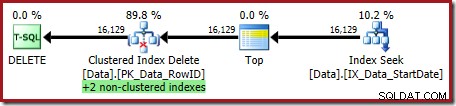
Ambos os índices não clusterizados são mantidos pela exclusão de índice clusterizado:
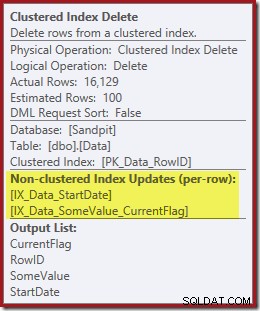
O Index Seek retorna apenas o RowID:
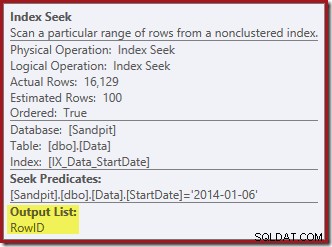
As colunas necessárias para a manutenção do índice são recuperadas internamente pelo operador delete; esses detalhes não são expostos na saída do plano de exibição (portanto, a lista de saída do operador de exclusão estaria vazia). Eu adicionei um
OUTPUT cláusula à consulta para mostrar o Clustered Index Delete mais uma vez retornando dados que não recebeu em sua entrada: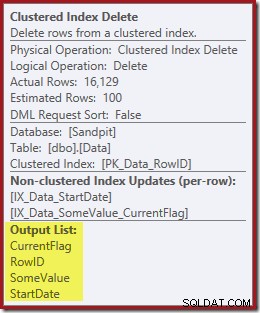
Considerações finais
Esta é uma limitação difícil de contornar. Por um lado, geralmente não queremos usar sinalizadores de rastreamento não documentados em sistemas de produção.
A 'correção' natural é adicionar as colunas necessárias para a manutenção do índice filtrado a todos índices não clusterizados que podem ser usados para localizar linhas a serem excluídas. Esta não é uma proposta muito atraente, de vários pontos de vista. Outra alternativa é simplesmente não usar índices filtrados, mas isso também não é o ideal.
Meu sentimento é que o otimizador de consulta deve considerar uma alternativa de manutenção por índice para índices filtrados automaticamente, mas seu raciocínio parece estar incompleto nesta área no momento (e baseado em heurísticas simples em vez de custear adequadamente por índice/por linha alternativas).
Para colocar alguns números em torno dessa declaração, o plano de verificação de índice clusterizado paralelo escolhido pelo otimizador chegou a 5,5 unidades em meus testes. A mesma consulta com o sinalizador de rastreamento estima um custo de 1,4 unidades. Com o terceiro índice em vigor, o plano de interseção de índice paralelo escolhido pelo otimizador teve um custo estimado de 4,9 , enquanto o plano de sinalizador de rastreamento chegou em 2,7 unidades (todos os testes no SQL Server 2014 RTM CU1 build 12.0.2342 sob o modelo de estimativa de cardinalidade 120 e com o sinalizador de rastreamento 4199 habilitado).
Considero isso como um comportamento que deve ser melhorado. Você pode votar para concordar ou discordar de mim neste item do Connect.



