Eu tive muitas conversas recentemente sobre tipos de cargas de trabalho – especificamente para entender se uma carga de trabalho é parametrizada, ad hoc ou uma mistura. É uma das coisas que analisamos durante uma auditoria de integridade, e Kimberly tem uma ótima consulta de seu cache do plano e otimização para cargas de trabalho adhoc que fazem parte do nosso kit de ferramentas. Copiei a consulta abaixo e, se você nunca a executou em nenhum de seus ambientes de produção antes, definitivamente encontre algum tempo para fazê-lo.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Se eu executar esta consulta em um ambiente de produção, podemos obter uma saída como a seguinte:
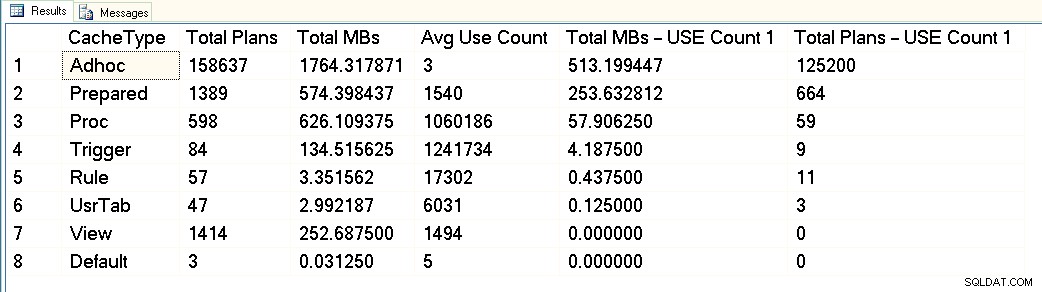
A partir desta captura de tela, você pode ver que temos cerca de 3 GB no total dedicados ao cache do plano, e desses 1,7 GB são para os planos de mais de 158.000 consultas ad hoc. Desses 1,7 GB, aproximadamente 500 MB são usados para 125.000 planos que executam UM tempo apenas. Cerca de 1 GB do cache do plano é para planos preparados e de procedimento, e eles ocupam apenas cerca de 300 MB de espaço. Mas observe a contagem média de uso – bem mais de 1 milhão para procedimentos. Ao olhar para essa saída, eu classificaria essa carga de trabalho como mista – algumas consultas parametrizadas, algumas adhoc.
A postagem do blog de Kimberly discute opções para gerenciar um cache de plano preenchido com muitas consultas ad hoc. O inchaço do cache do plano é apenas um problema com o qual você precisa lidar quando tem uma carga de trabalho ad hoc e, neste post, quero explorar o efeito que isso pode ter na CPU como resultado de todas as compilações que precisam ocorrer. Quando uma consulta é executada no SQL Server, ela passa por compilação e otimização, e há sobrecarga associada a esse processo, que frequentemente se manifesta como custo de CPU. Quando um plano de consulta estiver no cache, ele poderá ser reutilizado. As consultas parametrizadas podem acabar reutilizando um plano que já está em cache, pois o texto da consulta é exatamente o mesmo. Quando uma consulta ad hoc é executada, ela só reutilizará o plano no cache se tiver o valor exato mesmo texto e valores de entrada .
Configuração
Para nossos testes vamos gerar uma string aleatória em TSQL e concatená-la a uma consulta para que cada execução tenha um valor literal diferente. Eu envolvi isso em um procedimento armazenado que chama a consulta usando Dynamic String Execution (EXEC @QueryString), então ele se comporta como uma instrução adhoc. Chamá-lo de dentro de um procedimento armazenado significa que podemos executá-lo um número conhecido de vezes.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
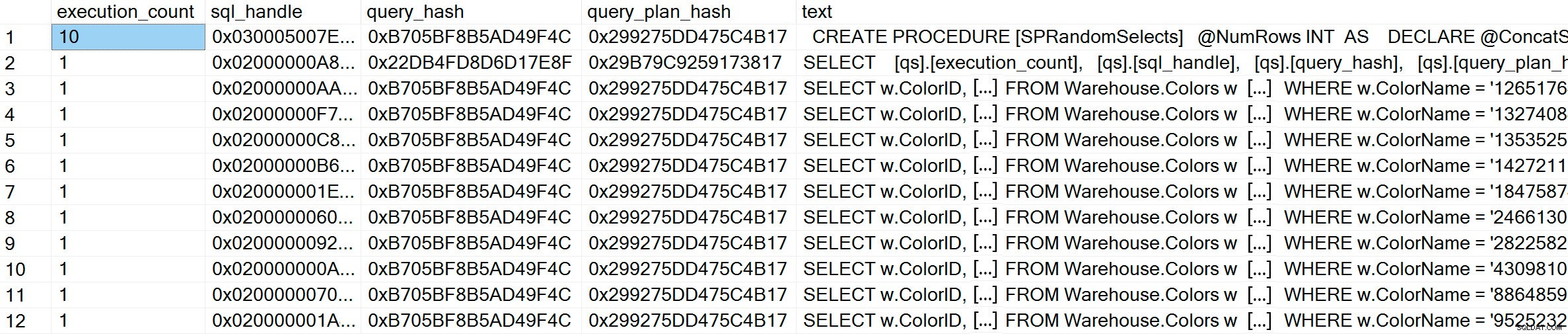
GO Após a execução, se verificarmos o cache do plano, podemos ver que temos 10 entradas únicas, cada uma com uma execução_contagem de 1 (amplie a imagem se necessário para ver os valores exclusivos do predicado):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Agora criamos um procedimento armazenado quase idêntico que executa a mesma consulta, mas parametrizada:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO Dentro do cache do plano, além das 10 consultas ad hoc, vemos uma entrada para a consulta parametrizada que foi executada 10 vezes. Como a entrada é parametrizada, mesmo que strings muito diferentes sejam passadas para o parâmetro, o texto da consulta é exatamente o mesmo:
Teste
Agora que entendemos o que acontece no cache do plano, vamos criar mais carga. Usaremos um arquivo de linha de comando que chama o mesmo arquivo .sql em 10 threads diferentes, com cada arquivo chamando o procedimento armazenado 10.000 vezes. Limparemos o cache do plano antes de começar e capturaremos o Total CPU% e as compilações SQL/s com PerfMon enquanto os scripts são executados.
Conteúdo do arquivo Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Conteúdo do arquivo .sql parametrizado:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Exemplo de arquivo de comando (visualizado no Bloco de Notas) que chama o arquivo .sql:
Exemplo de arquivo de comando (visualizado no Bloco de Notas) que cria 10 threads, cada um chamando o arquivo Run_Adhoc.cmd:
Depois de executar cada conjunto de consultas 100.000 vezes no total, se observarmos o cache do plano, veremos o seguinte:

Existem mais de 10.000 planos ad hoc no cache de planos. Você pode se perguntar por que não há um plano para todas as 100.000 consultas ad hoc executadas, e isso tem a ver com o funcionamento do cache do plano (seu tamanho baseado na memória disponível, quando os planos não usados estão vencidos etc.). O importante é que assim existem muitos planos ad hoc, em comparação com o que vemos para o resto dos tipos de cache.
Os dados do PerfMon, representados graficamente abaixo, são mais reveladores. A execução das 100.000 consultas parametrizadas foi concluída em menos de 15 segundos, e houve um pequeno pico em Compilações/s no início, que é quase imperceptível no gráfico. O mesmo número de execuções ad hoc levou pouco mais de 60 segundos para ser concluído, com compilações/segando perto de 2.000 antes de cair para mais de 1.000 em torno da marca de 45 segundos, com CPU perto ou em 100% na maior parte do tempo.
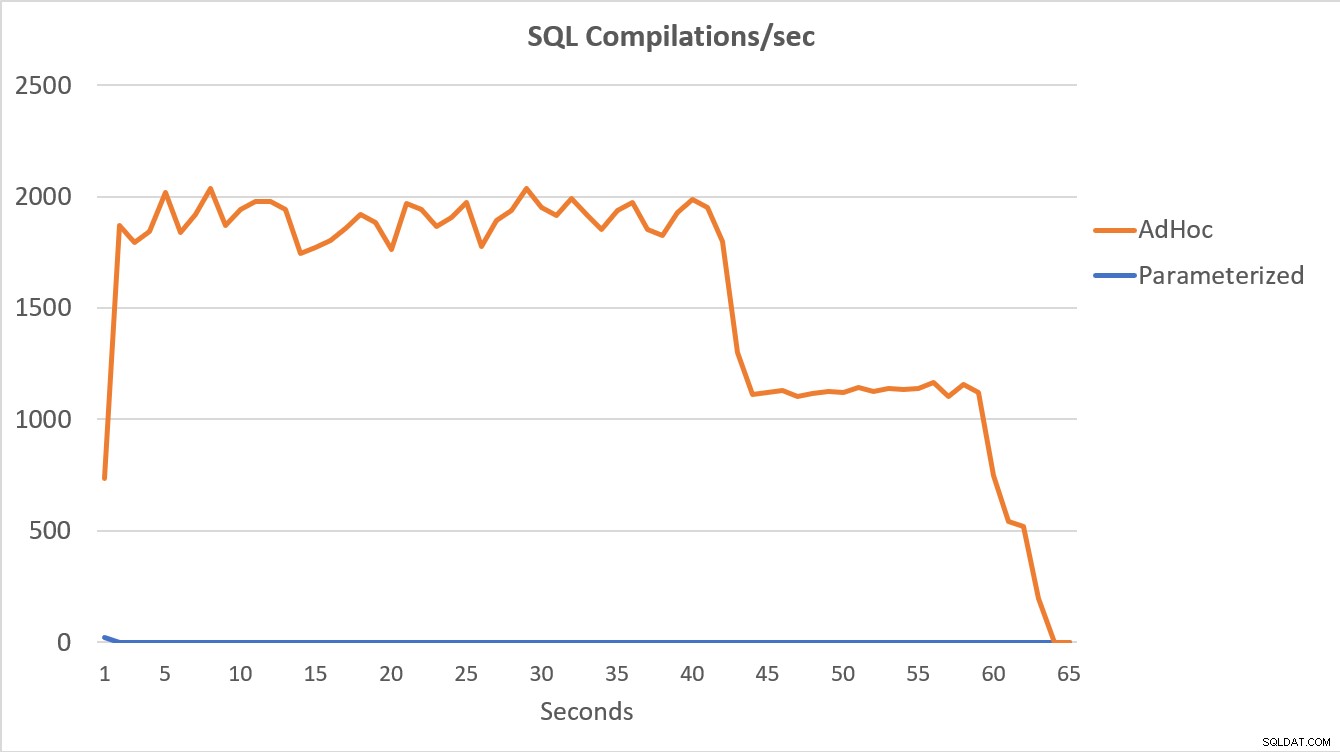
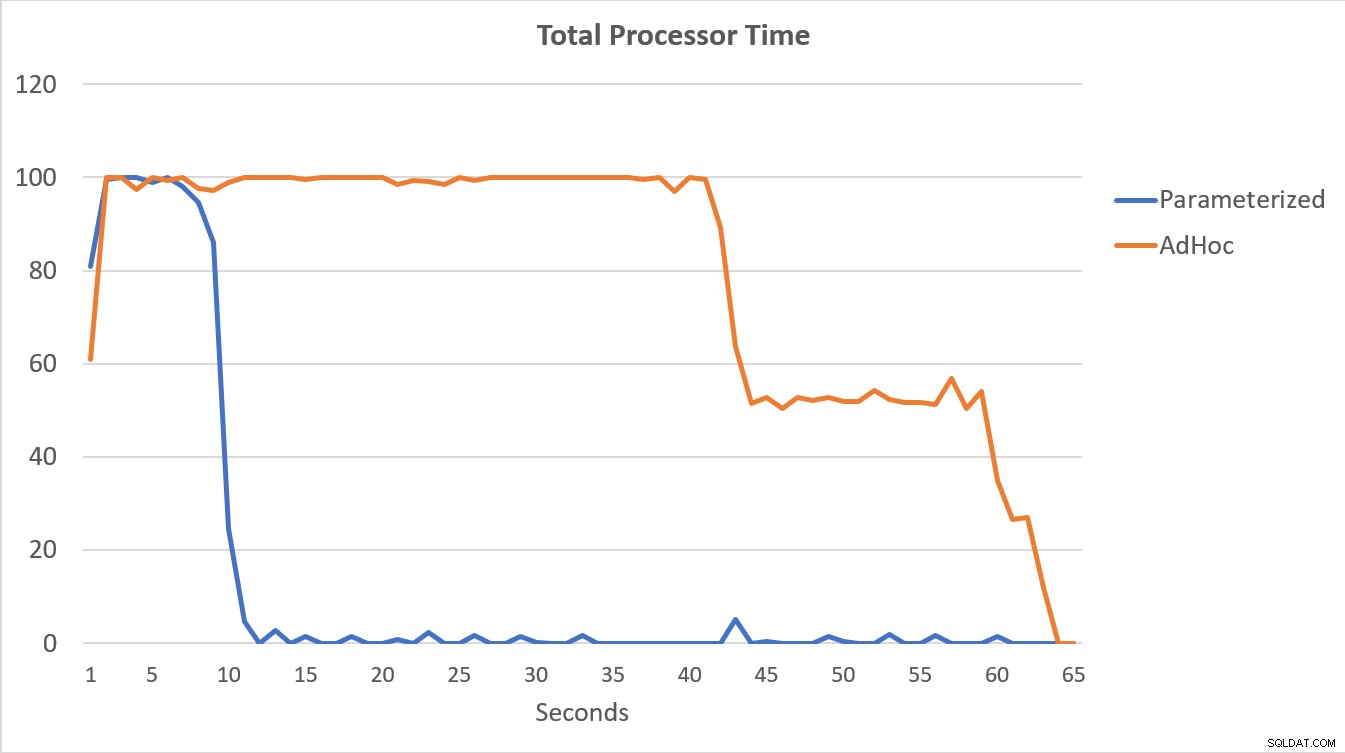
Resumo
Nosso teste foi extremamente simples, pois enviamos apenas variações para um consulta adhoc, enquanto em um ambiente de produção, poderíamos ter centenas ou milhares de variações diferentes para centenas ou milhares de diferentes consultas ad hoc. O impacto no desempenho dessas consultas ad hoc não é apenas o inchaço do cache do plano que ocorre, embora olhar para o cache do plano seja um ótimo ponto de partida se você não estiver familiarizado com o tipo de carga de trabalho que possui. Um alto volume de consultas ad hoc pode conduzir compilações e, portanto, CPU, que às vezes pode ser mascarada pela adição de mais hardware, mas pode chegar um ponto em que a CPU se torna um gargalo. Se você acha que isso pode ser um problema, ou um possível problema, em seu ambiente, procure identificar quais consultas ad hoc estão sendo executadas com mais frequência e veja quais opções você tem para parametrizá-las. Não me entenda mal – existem problemas potenciais com consultas parametrizadas (por exemplo, estabilidade do plano devido à distorção de dados), e esse é outro problema que você pode ter que resolver. Independentemente da sua carga de trabalho, é importante entender que raramente há um método de “definir e esquecer” para codificação, configuração, manutenção etc. executar de forma confiável. Uma das tarefas de um DBA é acompanhar essa mudança e gerenciar o desempenho da melhor forma possível – seja relacionado a desafios de desempenho ad hoc ou parametrizados.



