O SQL Server 2014 trouxe muitos recursos novos que DBAs e desenvolvedores esperavam testar e usar em seus ambientes, como o índice Columnstore em cluster atualizável, durabilidade atrasada e extensões de pool de buffers. Um recurso pouco discutido são as estatísticas incrementais. A menos que você use particionamento, esse não é um recurso que você pode implementar. Mas se você tiver tabelas particionadas em seu banco de dados, as estatísticas incrementais podem ter sido algo que você esperava ansiosamente.
Observação:Benjamin Nevarez abordou alguns conceitos básicos relacionados a estatísticas incrementais em sua postagem de fevereiro de 2014, Estatísticas incrementais do SQL Server 2014. E embora não tenha mudado muito na forma como esse recurso funciona desde sua postagem e o lançamento de abril de 2014, parecia um bom momento para investigar como a habilitação de estatísticas incrementais pode ajudar no desempenho da manutenção.
As estatísticas incrementais às vezes são chamadas de estatísticas de nível de partição, e isso ocorre porque, pela primeira vez, o SQL Server pode criar automaticamente estatísticas específicas de uma partição. Um dos desafios anteriores com o particionamento era que, embora você pudesse ter 1 para n partições para uma tabela, havia apenas uma (1) estatística que representava a distribuição de dados em todas essas partições. Você pode criar estatísticas filtradas para a tabela particionada – uma estatística para cada partição – para fornecer ao otimizador de consulta melhores informações sobre a distribuição de dados. Mas esse era um processo manual e exigia um script para criá-los automaticamente para cada nova partição.
No SQL Server 2014, você usa o
STATISTICS_INCREMENTAL opção para que o SQL Server crie essas estatísticas em nível de partição automaticamente. No entanto, essas estatísticas não são usadas como você imagina. Mencionei anteriormente que, antes de 2014, você poderia criar estatísticas filtradas para fornecer ao otimizador melhores informações sobre as partições. Essas estatísticas incrementais? Eles não são usados atualmente pelo otimizador. O otimizador de consulta ainda usa apenas o histograma principal que representa a tabela inteira. (Post a vir que irá demonstrar isso!)
Então, qual é o objetivo das estatísticas incrementais? Se você assumir que apenas os dados na partição mais recente estão sendo alterados, o ideal é atualizar apenas as estatísticas dessa partição. Você pode fazer isso agora com estatísticas incrementais – e o que acontece é que as informações são então mescladas de volta ao histograma principal. O histograma de toda a tabela será atualizado sem ter que ler toda a tabela para atualizar as estatísticas, e isso pode ajudar no desempenho de suas tarefas de manutenção.
Configuração
Começaremos criando uma função e esquema de partição e, em seguida, uma nova tabela que particionaremos. Observe que criei um grupo de arquivos para cada função de partição, como você faria em um ambiente de produção. Você pode criar o esquema de partição no mesmo grupo de arquivos (por exemplo,
PRIMARY ) se você não puder descartar facilmente seu banco de dados de teste. Cada grupo de arquivos também tem alguns GB de tamanho, pois adicionaremos quase 400 milhões de linhas. USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Antes de adicionarmos os dados, criaremos o índice clusterizado e observaremos que a sintaxe inclui o
WITH (STATISTICS_INCREMENTAL = ON) opção:/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
O que é interessante notar aqui é que se você olhar para o
ALTER TABLE entrada no MSDN, não inclui esta opção. Você só o encontrará no ALTER INDEX entrada... mas isso funciona. Se você quiser seguir a documentação ao pé da letra, execute:/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Depois que o índice clusterizado for criado para o esquema de partição, carregaremos nossos dados e verificaremos quantas linhas existem por partição (observe que isso leva mais de 7 minutos no meu laptop, você pode querer adicionar menos linhas dependendo de quanto armazenamento (e tempo) você tem disponível):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number]; 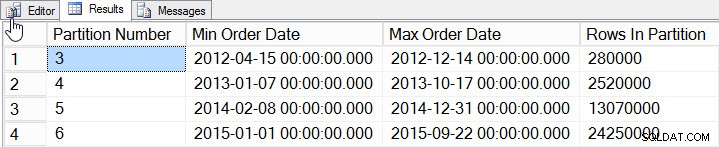 Dados por partição
Dados por partição Adicionamos dados de 2012 a 2015, com significativamente mais dados em 2014 e 2015. Vamos ver como são nossas estatísticas:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]); 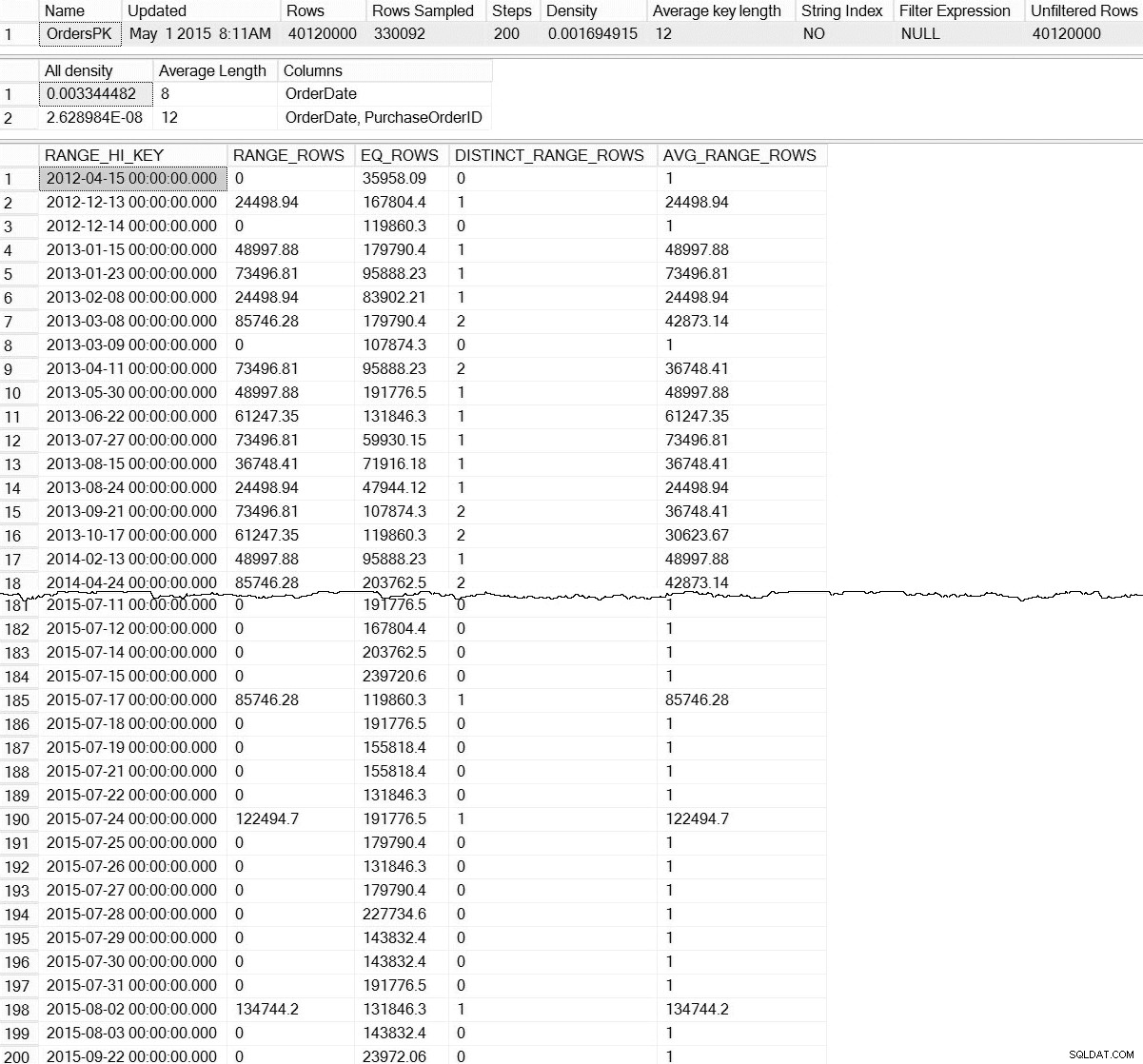 Saída DBCC SHOW_STATISTICS para dbo.Orders (clique para ampliar)
Saída DBCC SHOW_STATISTICS para dbo.Orders (clique para ampliar) Com o padrão
DBCC SHOW_STATISTICS comando, não temos nenhuma informação sobre estatísticas no nível da partição. Não tema; não estamos completamente condenados – existe uma função de gerenciamento dinâmico não documentada, sys.dm_db_stats_properties_internal . Lembre-se de que não documentado significa que não há suporte (não há entrada do MSDN para o DMF) e que pode ser alterado a qualquer momento sem nenhum aviso da Microsoft. Dito isso, é um bom começo para ter uma ideia do que existe para nossas estatísticas incrementais:SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];  Informações do histograma de dm_db_stats_properties_internal (clique para ampliar)
Informações do histograma de dm_db_stats_properties_internal (clique para ampliar) Isso é muito mais interessante. Aqui podemos ver a prova de que existem estatísticas em nível de partição (e mais). Como este DMF não está documentado, temos que fazer alguma interpretação. Por hoje, vamos nos concentrar nas primeiras sete linhas da saída, onde a primeira linha representa o histograma de toda a tabela (observe as
rows valor de 40 milhões), e as linhas subsequentes representam os histogramas para cada partição. Infelizmente, o partition_number valor neste histograma não se alinha com o número da partição de sys.dm_db_index_physical_stats para particionamento à direita (ele se correlaciona corretamente para particionamento à esquerda). Observe também que essa saída também inclui o last_updated e modification_counter colunas, que são úteis na solução de problemas e podem ser usadas para desenvolver scripts de manutenção que atualizam de forma inteligente as estatísticas com base na idade ou nas modificações de linha. Minimizar a manutenção necessária
O principal valor das estatísticas incrementais neste momento é a capacidade de atualizar estatísticas para uma partição e fazer com que elas sejam mescladas no histograma em nível de tabela, sem precisar atualizar a estatística de toda a tabela (e, portanto, ler toda a tabela). Para ver isso em ação, primeiro vamos atualizar as estatísticas da partição que contém os dados de 2015, partição 5, e vamos registrar o tempo gasto e fazer um instantâneo do
sys.dm_io_virtual_file_stats DMF antes e depois para ver quanta E/S ocorre:SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Saída:
Tempos de execução do SQL Server:
tempo de CPU =203 ms, tempo decorrido =240 ms.
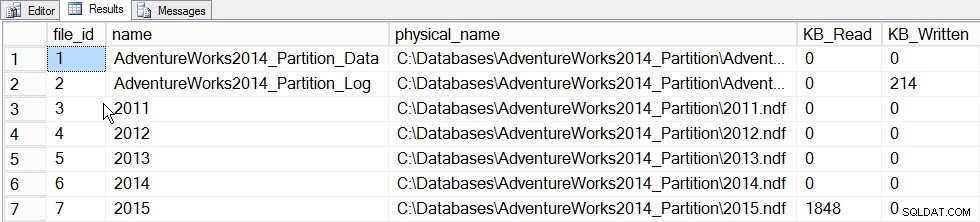 Dados do File_stats após atualizar uma partição
Dados do File_stats após atualizar uma partição Se observarmos o
sys.dm_db_stats_properties_internal saída, vemos que last_updated alterado para o histograma de 2015 e o histograma em nível de tabela (assim como alguns outros nós, que é para investigação posterior): Informações de histograma atualizadas de dm_db_stats_properties_internal
Informações de histograma atualizadas de dm_db_stats_properties_internal Agora vamos atualizar as estatísticas com um
FULLSCAN para a tabela, e vamos fazer um snapshot de file_stats antes e depois novamente:SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Saída:
Tempos de execução do SQL Server:
tempo de CPU =12720 ms, tempo decorrido =13646 ms
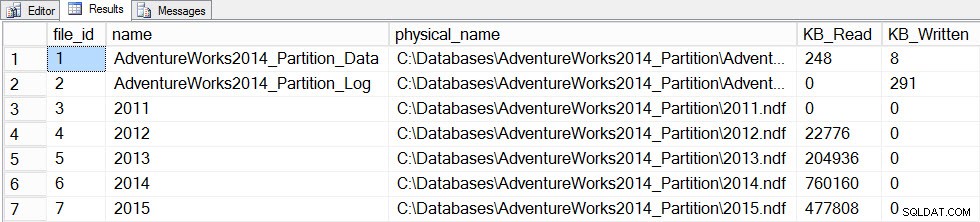 Arquivos de dados após atualização com uma varredura completa
Arquivos de dados após atualização com uma varredura completa A atualização levou muito mais tempo (13 segundos versus algumas centenas de milissegundos) e gerou muito mais E/S. Se verificarmos
sys.dm_db_stats_properties_internal novamente, descobrimos que last_updated alterado para todos os histogramas: Informações do histograma de dm_db_stats_properties_internal após uma varredura completa
Informações do histograma de dm_db_stats_properties_internal após uma varredura completa Resumo
Embora as estatísticas incrementais ainda não sejam usadas pelo otimizador de consulta para fornecer informações sobre cada partição, elas fornecem um benefício de desempenho ao gerenciar estatísticas para tabelas particionadas. Se as estatísticas precisarem ser atualizadas apenas para partições selecionadas, apenas elas poderão ser atualizadas. As novas informações são então mescladas no histograma em nível de tabela, fornecendo ao otimizador informações mais atuais, sem o custo de ler a tabela inteira. No futuro, esperamos que essas estatísticas em nível de partição sejam ser usado pelo otimizador. Fique atento…