Alta disponibilidade é uma alta porcentagem de tempo em que o sistema está funcionando e respondendo de acordo com as necessidades do negócio. Para sistemas de banco de dados de produção, normalmente é a prioridade mais alta mantê-lo próximo a 100%. Construímos clusters de banco de dados para eliminar todos os pontos únicos de falha. Se uma instância ficar indisponível, outro nó poderá receber a carga de trabalho e continuar a partir daí. Em um mundo perfeito, um cluster de banco de dados resolveria todos os nossos problemas de disponibilidade do sistema. Infelizmente, embora tudo pareça bom no papel, a realidade geralmente é diferente. Então, onde pode dar errado?
Os sistemas de banco de dados transacionais vêm com mecanismos de armazenamento sofisticados. Manter os dados consistentes em vários nós torna essa tarefa muito mais difícil. O clustering introduz uma série de novas variáveis que dependem muito da rede e da infraestrutura subjacente. Não é incomum que uma instância de banco de dados autônoma que estava funcionando bem em um único nó de repente tenha um desempenho ruim em um ambiente de cluster.
Entre o número de coisas que podem afetar a disponibilidade do cluster, os problemas de latência desempenham um papel crucial. No entanto, qual é a latência? Está relacionado apenas com a rede?
O termo "latência" na verdade se refere a vários tipos de atrasos ocorridos no processamento de dados. É quanto tempo leva para uma informação passar de um estágio para outro.
Nesta postagem do blog, veremos as duas principais soluções de alta disponibilidade para MySQL e MariaDB e como cada uma delas pode ser afetada por problemas de latência.
No final do artigo, analisamos os balanceadores de carga modernos e discutimos como eles podem ajudá-lo a resolver alguns tipos de problemas de latência.
Em um artigo anterior, meu colega Krzysztof Książek escreveu sobre "Lidar com redes não confiáveis ao criar uma solução de alta disponibilidade para MySQL ou MariaDB". Você encontrará dicas que podem ajudá-lo a projetar sua arquitetura de alta disponibilidade pronta para produção e evitar alguns dos problemas descritos aqui.
Replicação mestre-escravo para alta disponibilidade.
A replicação mestre-escravo do MySQL é provavelmente o tipo de cluster de banco de dados mais popular do planeta. Uma das principais coisas que você deseja monitorar durante a execução do cluster de replicação mestre-escravo é o atraso do escravo. Dependendo dos requisitos de sua aplicação e da forma como você utiliza seu banco de dados, a latência de replicação (lag escravo) pode determinar se os dados podem ser lidos do nó escravo ou não. Dados confirmados no mestre, mas ainda não disponíveis em um escravo assíncrono, significam que o escravo tem um estado mais antigo. Quando não for possível ler de um escravo, você precisaria ir para o mestre, e isso pode afetar o desempenho do aplicativo. Na pior das hipóteses, seu sistema não será capaz de lidar com toda a carga de trabalho em um mestre.
Atraso do escravo e dados obsoletos
Para verificar o status da replicação mestre-escravo, você deve iniciar com o comando abaixo:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Usando as informações acima, você pode determinar quão boa é a latência geral da replicação. Quanto menor o valor que você vê em "Seconds_Behind_Master", melhor a velocidade de transferência de dados para replicação.
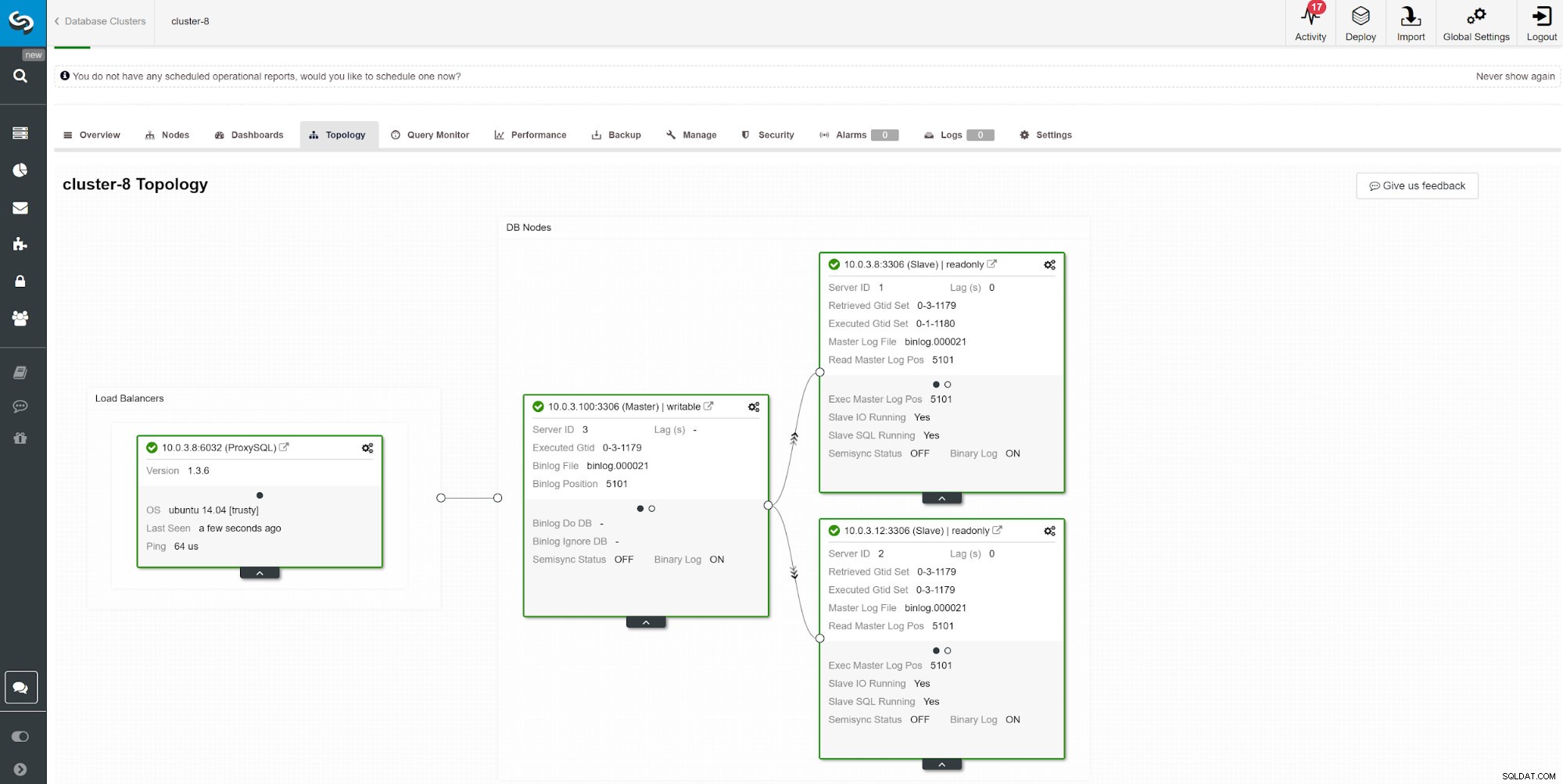 Outra maneira de monitorar o atraso do escravo é usar o monitoramento de replicação do ClusterControl. Nesta captura de tela, podemos ver o status de replicação do cluster mestre-escravo (2x) assíncrono com ProxySQL.
Outra maneira de monitorar o atraso do escravo é usar o monitoramento de replicação do ClusterControl. Nesta captura de tela, podemos ver o status de replicação do cluster mestre-escravo (2x) assíncrono com ProxySQL. Há uma série de coisas que podem afetar o tempo de replicação. O mais óbvio é o rendimento da rede e a quantidade de dados que você pode transferir. O MySQL vem com várias opções de configuração para otimizar o processo de replicação. Os parâmetros essenciais relacionados à replicação são:
- Aplicação paralela
- Algoritmo de relógio lógico
- Compressão
- Replicação seletiva mestre-escravo
- Modo de replicação
Aplicação paralela
Não é incomum iniciar o ajuste de replicação com a ativação da aplicação de processo paralelo. A razão para isso é que, por padrão, o MySQL usa log binário sequencial e um servidor de banco de dados típico vem com várias CPUs para usar.
Para contornar a aplicação de log sequencial, o MariaDB e o MySQL oferecem replicação paralela. A implementação pode diferir por fornecedor e versão. Por exemplo. O MySQL 5.6 oferece replicação paralela desde que um esquema separe as consultas, enquanto o MariaDB (a partir da versão 10.0) e o MySQL 5.7 podem lidar com a replicação paralela entre esquemas. Diferentes fornecedores e versões vêm com suas limitações e recursos, portanto, verifique sempre a documentação.
A execução de consultas por meio de threads escravos paralelos pode acelerar seu fluxo de replicação se você estiver gravando muito. No entanto, se você não estiver, seria melhor manter a replicação tradicional de thread único. Para habilitar o processamento paralelo, altere o slave_parallel_workers para o número de threads de CPU que você deseja envolver no processo. Recomenda-se manter o valor inferior ao número de threads de CPU disponíveis.
A replicação paralela funciona melhor com as confirmações de grupo. Para verificar se você tem commits de grupo acontecendo, execute a seguinte consulta.
show global status like 'binlog_%commits';Quanto maior a razão entre esses dois valores, melhor.
Relógio lógico
O slave_parallel_type=LOGICAL_CLOCK é uma implementação de um algoritmo de relógio Lamport. Ao usar um escravo multithread, esta variável especifica o método usado para decidir quais transações podem ser executadas em paralelo no escravo. A variável não tem efeito nos escravos para os quais o multithreading não está habilitado, portanto, certifique-se de que slave_parallel_workers esteja definido como maior que 0.
Os usuários do MariaDB também devem verificar o modo otimista introduzido na versão 10.1.3, pois também pode fornecer melhores resultados.
GTID
O MariaDB vem com sua própria implementação do GTID. A sequência do MariaDB consiste em um domínio, servidor e transação. Os domínios permitem replicação de várias origens com IDs distintos. Diferentes IDs de domínio podem ser usados para replicar a porção de dados fora de ordem (em paralelo). Contanto que esteja tudo bem para o seu aplicativo, isso pode reduzir a latência da replicação.
A técnica semelhante se aplica ao MySQL 5.7, que também pode usar o mestre multifonte e os canais de replicação independentes.
Compressão
A energia da CPU está ficando menos cara ao longo do tempo, portanto, usá-la para compactação de log binário pode ser uma boa opção para muitos ambientes de banco de dados. O parâmetro slave_compressed_protocol diz ao MySQL para usar compressão se tanto o master quanto o slave suportarem. Por padrão, este parâmetro está desabilitado.
A partir do MariaDB 10.2.3, eventos selecionados no log binário podem ser compactados opcionalmente, para salvar as transferências de rede.
Formatos de replicação
O MySQL oferece vários modos de replicação. Escolher o formato de replicação correto ajuda a minimizar o tempo de transmissão de dados entre os nós do cluster.
Replicação multimestre para alta disponibilidade
Alguns aplicativos não podem operar com dados desatualizados.
Nesses casos, convém impor consistência nos nós com replicação síncrona. Manter os dados síncronos requer um plugin adicional e, para alguns, a melhor solução do mercado para isso é o Galera Cluster.
O cluster Galera vem com a API wsrep que é responsável por transmitir transações para todos os nós e executá-las de acordo com uma ordenação de todo o cluster. Isso bloqueará a execução de consultas subsequentes até que o nó tenha aplicado todos os conjuntos de gravação de sua fila do aplicador. Embora seja uma boa solução para consistência, você pode atingir algumas limitações de arquitetura. Os problemas comuns de latência podem estar relacionados a:
- O nó mais lento do cluster
- Escalonamento horizontal e operações de gravação
- Clusters geolocalizados
- Ping alto
- Tamanho da transação
O nó mais lento do cluster
Por design, o desempenho de gravação do cluster não pode ser superior ao desempenho do nó mais lento do cluster. Inicie a revisão do cluster verificando os recursos da máquina e verifique os arquivos de configuração para garantir que todos sejam executados nas mesmas configurações de desempenho.
Paralelização
Os threads paralelos não garantem melhor desempenho, mas podem acelerar a sincronização de novos nós com o cluster. O status wsrep_cert_deps_distance nos informa o possível grau de paralelização. É o valor da distância média entre os valores de sequência mais altos e mais baixos que podem ser aplicados em paralelo. Você pode usar a variável de status wsrep_cert_deps_distance para determinar o número máximo possível de encadeamentos escravos.
Escala horizontal
Ao adicionar mais nós no cluster, temos menos pontos que podem falhar; no entanto, as informações precisam passar por várias instâncias até serem confirmadas, o que multiplica os tempos de resposta. Se você precisar de gravações escaláveis, considere uma arquitetura baseada em fragmentação. Uma boa solução pode ser um mecanismo de armazenamento Spider.
Em alguns casos, para reduzir as informações compartilhadas entre os nós do cluster, você pode considerar ter um gravador por vez. É relativamente fácil de implementar usando um balanceador de carga. Ao fazer isso manualmente, certifique-se de ter um procedimento para alterar o valor do DNS quando o nó do gravador ficar inativo.
Clusters geolocalizados
Embora o Galera Cluster seja síncrono, é possível implantar um Galera Cluster em data centers. A replicação síncrona como o MySQL Cluster (NDB) implementa um commit de duas fases, onde as mensagens são enviadas para todos os nós em um cluster em uma fase de 'preparação' e outro conjunto de mensagens é enviado em uma fase de 'commit'. Essa abordagem geralmente não é adequada para nós geograficamente díspares, devido às latências no envio de mensagens entre nós.
Ping alto
O Galera Cluster com as configurações padrão não lida bem com a alta latência de rede. Se você tiver uma rede com um nó que mostra um tempo de ping alto, considere alterar os parâmetros evs.send_window e evs.user_send_window. Essas variáveis definem o número máximo de pacotes de dados em replicação por vez. Para configurações de WAN, a variável pode ser definida com um valor consideravelmente maior que o valor padrão de 2. É comum defini-la como 512. Esses parâmetros fazem parte de wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Tamanho da transação
Uma das coisas que você precisa considerar ao executar o Galera Cluster é o tamanho da transação. Encontrar o equilíbrio entre o tamanho da transação, o desempenho e o processo de certificação Galera é algo que você deve estimar em sua inscrição. Você pode encontrar mais informações sobre isso no artigo How to Improve Performance of Galera Cluster for MySQL or MariaDB by Ashraf Sharif.
Leituras de consistência causal do balanceador de carga
Mesmo com o risco minimizado de problemas de latência de dados, a replicação assíncrona padrão do MySQL não pode garantir consistência. Ainda é possível que os dados ainda não sejam replicados para o escravo enquanto seu aplicativo os estiver lendo a partir daí. A replicação síncrona pode resolver esse problema, mas tem limitações de arquitetura e pode não atender aos requisitos do aplicativo (por exemplo, gravações em massa intensivas). Então, como superá-lo?
A primeira etapa para evitar a leitura de dados obsoletos é tornar o aplicativo ciente do atraso de replicação. Geralmente é programado no código do aplicativo. Felizmente, existem balanceadores de carga de banco de dados modernos com suporte de roteamento de consulta adaptável com base no rastreamento de GTID. Os mais populares são ProxySQL e Maxscale.
ProxySQL 2.0
O ProxySQL Binlog Reader permite que o ProxySQL saiba em tempo real qual GTID foi executado em cada servidor MySQL, slaves e master. Graças a isso, quando um cliente executa uma leitura que precisa fornecer leituras de consistência causal, o ProxySQL sabe imediatamente em qual servidor a consulta pode ser executada. Se por algum motivo as gravações ainda não foram executadas em nenhum escravo, o ProxySQL saberá que o gravador foi executado no mestre e enviará a leitura para lá.
Maxscale 2.3
O MariaDB introduziu leituras casuais no Maxscale 2.3.0. A maneira como funciona é semelhante ao ProxySQL 2.0. Basicamente, quando causal_reads estão habilitadas, quaisquer leituras subsequentes realizadas em servidores escravos serão feitas de forma a evitar que o atraso de replicação afete os resultados. Caso o escravo não tenha alcançado o mestre dentro do tempo configurado, a consulta será repetida no mestre.