Introdução
Recentemente, encontramos um problema de desempenho interessante em um de nossos bancos de dados SQL Server que processam transações a uma taxa séria. A tabela de transações usada para capturar essas transações tornou-se uma tabela quente. Como resultado, o problema apareceu na camada de aplicação. Era um tempo limite intermitente da sessão que procurava postar transações.
Isso acontecia porque uma sessão normalmente “segurava” a tabela e causava uma série de bloqueios espúrios no banco de dados.
A primeira reação de um administrador de banco de dados típico seria identificar a sessão de bloqueio primária e encerrá-la com segurança. Isso era seguro porque normalmente era uma instrução SELECT ou uma sessão ociosa.
Houve também outras tentativas de resolver o problema:
- Limpando a mesa. Esperava-se que isso garantisse um bom desempenho, mesmo que a consulta tivesse que varrer uma tabela inteira.
- Ativar o nível de isolamento READ COMMITTED SNAPSHOT para reduzir o impacto das sessões de bloqueio.
Neste artigo, tentaremos recriar uma versão simplista do cenário e usá-la para mostrar como a indexação simples pode resolver situações como essa quando bem feita.
Duas Tabelas Relacionadas
Dê uma olhada na Listagem 1 e na Listagem 2. Elas mostram as versões simplificadas das tabelas envolvidas no cenário em consideração.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
A Listagem 3 mostra um gatilho que insere quatro linhas em TranDetails tabela para cada linha inserida no TranLog tabela.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Participar da consulta
É comum encontrar tabelas de transações suportadas por tabelas grandes. O objetivo é manter transações muito mais antigas ou armazenar os detalhes dos registros resumidos na primeira tabela. Pense nisso como pedidos e detalhes do pedido tabelas típicas em bancos de dados de exemplo do SQL Server. No nosso caso, estamos considerando o TranLog e TranDetails mesas.
Em circunstâncias normais, as transações preenchem essas duas tabelas ao longo do tempo. Em termos de relatórios ou consultas simples, a consulta realizará uma junção nessas duas tabelas. Essa junção capitalizará uma coluna comum entre as tabelas.
Primeiro, preenchemos a tabela usando a consulta na Listagem 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
Em nosso exemplo, a coluna comum usada pela junção é o TranID coluna:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Você pode ver as duas consultas de amostra simples que usam uma junção para recuperar registros de TranLog e TranDetails .
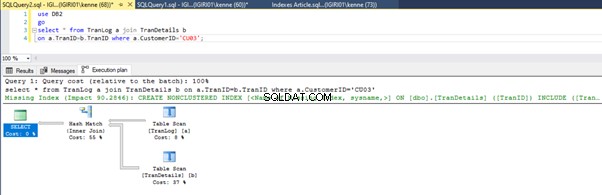
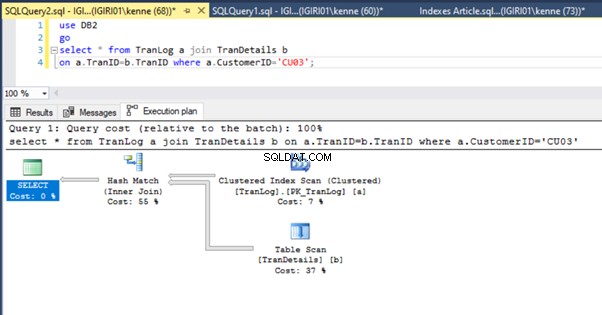
Quando executamos as consultas na Listagem 5, em ambos os casos, temos que fazer uma varredura completa em ambas as tabelas (veja as Figuras 1 e 2). A parte dominante de cada consulta são as operações físicas. Ambos são junções internas. No entanto, a Listagem 5a usa uma Correspondência de hash join, enquanto a Listagem 5b usa um Nested Loop Junte-se. Nota:A Listagem 5a retorna 4.000 linhas enquanto a Listagem 4b retorna 4 linhas.
Três etapas de ajuste de desempenho
A primeira otimização que fazemos é introduzir um índice (uma chave primária, para ser exato) no TranID coluna do TranLog tabela:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
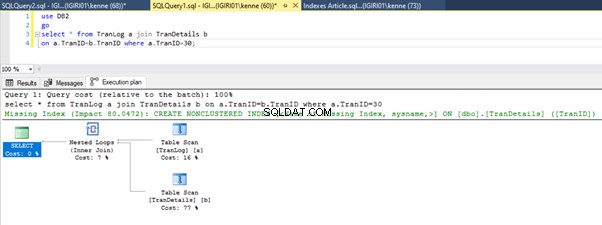
As Figuras 3 e 4 mostram que o SQL Server utiliza esse índice em ambas as consultas, fazendo uma varredura na Listagem 5a e uma busca na Listagem 5b.
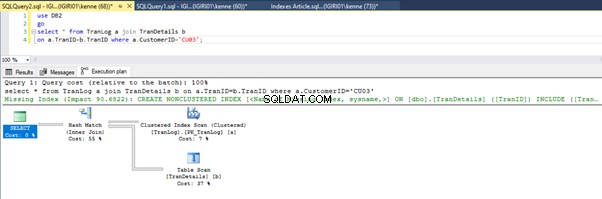
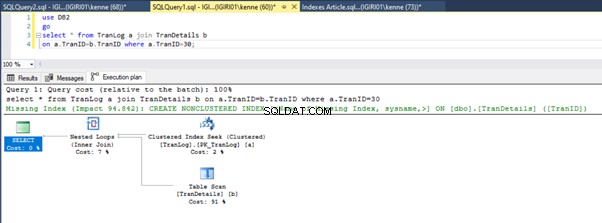
Temos uma busca de índice na Listagem 5b. Isso acontece por causa da coluna envolvida no predicado da cláusula WHERE – TranID. É nessa coluna que aplicamos um índice.
Em seguida, introduzimos uma chave estrangeira no TranID coluna dos TranDetails tabela (Listagem 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Isso não muda muito no plano de execução. A situação é praticamente a mesma mostrada anteriormente nas Figuras 3 e 4.
Em seguida, introduzimos um índice na coluna de chave estrangeira:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
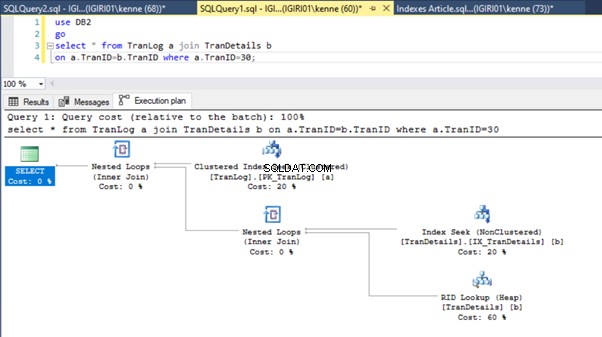
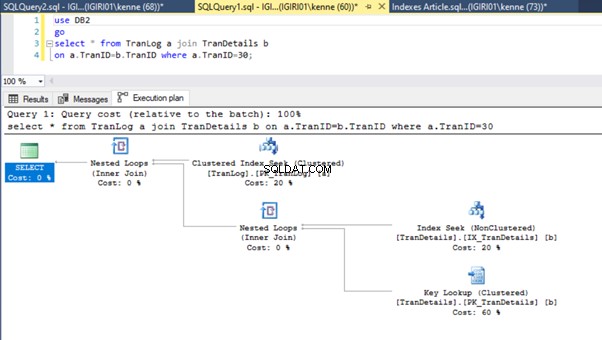
Essa ação altera drasticamente o plano de execução da Listagem 5b (consulte a Figura 6). Vemos mais índice procura acontecer. Além disso, observe a pesquisa RID na Figura 6.
As pesquisas RID em heaps geralmente acontecem na ausência de uma chave primária. Um heap é uma tabela sem chave primária.
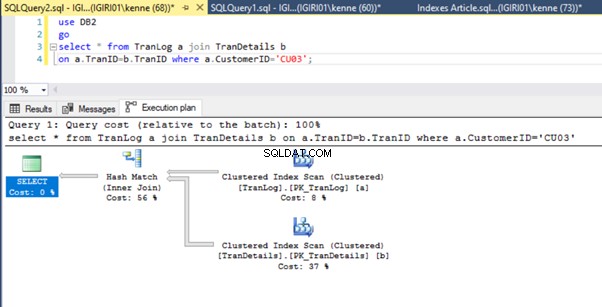
Por fim, adicionamos uma chave primária ao TranDetails tabela. Isso elimina a varredura de tabela e a pesquisa de heap RID nas Listagens 5a e 5b, respectivamente (consulte as Figuras 7 e 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Conclusão
A melhoria de desempenho introduzida pelos índices é bem conhecida até mesmo pelo DBA iniciante. No entanto, queremos salientar que você precisa observar atentamente como as consultas usam índices.
Além disso, a ideia é estabelecer a solução no caso particular em que temos as consultas de junção entre Log de transações tabelas e Detalhes da transação mesas.
Geralmente faz sentido impor o relacionamento entre essas tabelas usando uma chave e introduzir índices nas colunas de chave primária e estrangeira.
Ao desenvolver aplicativos que usam esse design, os desenvolvedores devem ter em mente os índices e relacionamentos necessários no estágio de design. Ferramentas modernas para especialistas em SQL Server tornam esses requisitos muito mais fáceis de cumprir. Você pode criar o perfil de suas consultas usando a ferramenta especializada Query Profiler. Faz parte da solução profissional multifuncional dbForge Studio para SQL Server desenvolvida pela Devart para tornar a vida do DBA mais simples.