Muitas pessoas usam estatísticas de espera como parte de sua metodologia geral de solução de problemas de desempenho, assim como eu, então a pergunta que eu queria explorar neste post é sobre os tipos de espera associados à sobrecarga do observador. Por sobrecarga do observador, quero dizer o impacto na taxa de transferência de carga de trabalho do SQL Server causado pelo SQL Profiler, rastreamentos do lado do servidor ou sessões de eventos estendidos. Para saber mais sobre o assunto da sobrecarga do observador, veja as duas postagens a seguir do meu colega Jonathan Kehayias :
- Medindo a “sobrecarga do observador” do SQL Trace versus eventos estendidos
- Impacto do evento estendido query_post_execution_showplan no SQL Server 2012
Portanto, neste post, gostaria de analisar algumas variações da sobrecarga do observador e ver se podemos encontrar tipos de espera consistentes associados à degradação medida. Há várias maneiras pelas quais os usuários do SQL Server implementam o rastreamento em seus ambientes de produção, portanto, seus resultados podem variar, mas eu queria abranger algumas categorias amplas e relatar o que encontrei:
- Uso da sessão do SQL Profiler
- Uso de rastreamento do lado do servidor
- Uso de rastreamento do lado do servidor, gravando em um caminho de E/S lento
- Uso de eventos estendidos com um destino de buffer de anel
- Uso de eventos estendidos com um destino de arquivo
- Uso de eventos estendidos com um destino de arquivo em um caminho de E/S lento
- Uso de eventos estendidos com um destino de arquivo em um caminho de E/S lento sem perda de evento
Você provavelmente pode pensar em outras variações sobre o tema e convido você a compartilhar quaisquer descobertas interessantes sobre a sobrecarga do observador e as estatísticas de espera como um comentário neste post.
Linha de base
Para o teste, usei uma máquina virtual VMware com quatro vCPUs e 4 GB de RAM. Meu convidado de máquina virtual estava em SSDs OCZ Vertex. O sistema operacional era o Windows Server 2008 R2 Enterprise e a versão do SQL Server é 2012, SP1 CU4.
Quanto à “carga de trabalho”, estou usando uma consulta somente leitura em um loop no banco de dados de amostra de crédito de 2008, definido como GO 10.000.000 vezes.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Também estou executando essa consulta por meio de 16 sessões simultâneas. O resultado final no meu sistema de teste é 100% de utilização da CPU em todas as vCPUs no convidado virtual e uma média de 14.492 solicitações em lote por segundo em um período de 2 minutos.
Em relação ao rastreamento de eventos, em cada teste usei o
Showplan XML Statistics Profile para os testes de rastreamento do SQL Profiler e do lado do servidor – e query_post_execution_showplan para sessões de eventos estendidos. Os eventos do plano de execução são muito caros, e é justamente por isso que eu os escolhi para que eu pudesse ver se em circunstâncias extremas eu poderia ou não derivar temas do tipo espera. Para testar o acúmulo de tipo de espera durante um período de teste, usei a consulta a seguir. Nada extravagante - apenas limpando as estatísticas, aguardando 2 minutos e coletando as 10 principais acumulações de espera para a instância do SQL Server durante o período de teste de degradação:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Observe que não estou filtrando os tipos de espera em segundo plano que normalmente são filtrados, e isso ocorre porque eu não queria eliminar algo que normalmente é benigno - mas nessa circunstância realmente aponta para uma área real para investigar mais.
Sessão do SQL Profiler
A tabela a seguir mostra as solicitações em lote anteriores e posteriores por segundo ao habilitar um rastreamento de rastreamento do SQL Profiler local
Showplan XML Statistics Profile (executando na mesma VM que a instância do SQL Server):| Solicitações de lote de linha de base por segundo (média de 2 minutos) | Solicitações de lote de sessão do SQL Profiler por segundo (média de 2 minutos) |
|---|---|
| 14.492 | 1.416 |
Você pode ver que o rastreamento do SQL Profiler causa uma queda significativa na taxa de transferência.
Quanto ao tempo de espera acumulado no mesmo período, os principais tipos de espera foram os seguintes (assim como o restante dos testes neste artigo, fiz algumas execuções de teste e a saída foi geralmente consistente):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWRITE | 67.142 | 1.149.824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 313 | 180.449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.086 |
| LAZYWRITER_SLEEP | 120 | 120.059 |
| DIRTY_PAGE_POLL | 1.198 | 120.038 |
| HADR_WORK_QUEUE | 12 | 120.015 |
| LOGMGR_QUEUE | 937 | 120.011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
O tipo de espera que salta para mim é
TRACEWRITE – que é definido pelos Manuais Online como um tipo de espera que “ocorre quando o provedor de rastreamento do conjunto de linhas SQL Trace aguarda um buffer livre ou um buffer com eventos a serem processados”. O restante dos tipos de espera se parece com os tipos de espera em segundo plano padrão que normalmente seriam filtrados do seu conjunto de resultados. Além disso, falei sobre um problema semelhante com rastreamento excessivo em um artigo em 2011 chamado sobrecarga do Observer – os perigos do rastreamento excessivo – então eu estava familiarizado com esse tipo de espera às vezes apontando corretamente para problemas de sobrecarga do observador. Agora, nesse caso específico sobre o qual escrevi no blog, não era o SQL Profiler, mas outro aplicativo usando o provedor de rastreamento de conjunto de linhas (ineficientemente). Rastreamento do lado do servidor
Isso foi para o SQL Profiler, mas e a sobrecarga de rastreamento do lado do servidor? A tabela a seguir mostra as solicitações de lote antes e depois por segundo ao habilitar uma gravação de rastreamento do lado do servidor local em um arquivo:
| Solicitações de lote de linha de base por segundo (média de 2 minutos) | Solicitações em lote do SQL Profiler por segundo (média de 2 minutos) |
|---|---|
| 14.492 | 4.015 |
Os principais tipos de espera foram os seguintes (fiz algumas execuções de teste e a saída foi consistente):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.015 |
| SLEEP_TASK | 253 | 180.871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.046 |
| HADR_WORK_QUEUE | 12 | 120.042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.021 |
| XE_DISPATCHER_WAIT | 3 | 120.006 |
| AGUARDE | 1 | 120.000 |
| LOGMGR_QUEUE | 931 | 119.993 |
| DIRTY_PAGE_POLL | 1.193 | 119.958 |
| XE_TIMER_EVENT | 55 | 119.954 |
Desta vez não vemos
TRACEWRITE (estamos usando um provedor de arquivos agora) e o outro tipo de espera relacionado a rastreamento, o não documentado SQLTRACE_INCREMENTAL_FLUSH_SLEEP subiu – mas em comparação com o primeiro teste, tem um tempo de espera acumulado muito semelhante (120.046 vs. 120.006) – e minha colega Erin Stellato (@erinstellato) falou sobre esse tipo de espera específico em seu post Descobrindo quando as estatísticas de espera foram apagadas pela última vez . Portanto, olhando para os outros tipos de espera, nenhum está se destacando como uma bandeira vermelha confiável. Rastreamento do lado do servidor gravando em um caminho de E/S lento
E se colocarmos o arquivo de rastreamento do lado do servidor em um disco lento? A tabela a seguir mostra as solicitações de lote antes e depois por segundo ao habilitar um rastreamento do lado do servidor local que grava em um arquivo em um pendrive:
| Solicitações de lote de linha de base por segundo (média de 2 minutos) | Solicitações em lote do SQL Profiler por segundo (média de 2 minutos) |
|---|---|
| 14.492 | 260 |
Como podemos ver – o desempenho é significativamente degradado – mesmo em comparação com o teste anterior.
Os principais tipos de espera foram os seguintes:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351.174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.273 | 299.995 |
| SLEEP_TASK | 240 | 194.264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181.458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125.007 |
| LAZYWRITER_SLEEP | 63 | 124.437 |
| LOGMGR_QUEUE | 941 | 120.559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120.516 |
| AGUARDE | 1 | 120.515 |
| DIRTY_PAGE_POLL | 1.204 | 120.513 |
Um tipo de espera que salta para este teste é o não documentado
SQLTRACE_FILE_BUFFER . Não muito documentado neste, mas com base no nome, podemos fazer um palpite (especialmente devido à configuração desse teste específico). Eventos estendidos para o destino do buffer de anel
Em seguida, vamos revisar as descobertas para os equivalentes da sessão do Extended Event. Eu usei a seguinte definição de sessão:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
A tabela a seguir mostra as solicitações de lote antes e depois por segundo ao habilitar uma sessão XE com um destino de buffer de anel (capturando o
query_post_execution_showplan evento):| Solicitações de lote de linha de base por segundo (média de 2 minutos) | Solicitações em lote do SQL Profiler por segundo (média de 2 minutos) |
|---|---|
| 14.492 | 4.737 |
Os principais tipos de espera foram os seguintes:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299.992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.006 |
| SLEEP_TASK | 240 | 181.739 |
| LAZYWRITER_SLEEP | 120 | 120.219 |
| HADR_WORK_QUEUE | 12 | 120.038 |
| DIRTY_PAGE_POLL | 1.198 | 120.035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.011 |
| LOGMGR_QUEUE | 936 | 120.008 |
| AGUARDE | 1 | 120.001 |
Nada saltou como relacionado ao XE, apenas “ruído” da tarefa em segundo plano.
Eventos estendidos para um destino de arquivo
Que tal alterar a sessão para usar um destino de arquivo em vez de um destino de buffer de anel? A tabela a seguir mostra as solicitações de lote antes e depois por segundo ao habilitar uma sessão XE com um destino de arquivo em vez de um destino de buffer de anel:
| Solicitações de lote de linha de base por segundo (média de 2 minutos) | Solicitações em lote do SQL Profiler por segundo (média de 2 minutos) |
|---|---|
| 14.492 | 4.299 |
Os principais tipos de espera foram os seguintes:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.103 | 299.996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 253 | 180.663 |
| LAZYWRITER_SLEEP | 120 | 120.187 |
| HADR_WORK_QUEUE | 12 | 120.029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| AGUARDE | 1 | 120.001 |
| XE_TIMER_EVENT | 59 | 119.966 |
| LOGMGR_QUEUE | 935 | 119.957 |
Nada, com exceção de
XE_TIMER_EVENT , saltou como relacionado ao XE. O Wait Type Repository de Bob Ward refere-se a este como seguro para ignorar, a menos que haja algo possivelmente errado - mas, realisticamente, você notaria esse tipo de espera geralmente benigno se estivesse em 9º lugar em seu sistema durante uma degradação de desempenho? E se você já estiver filtrando por causa de sua natureza normalmente benigna? Eventos estendidos para um destino de arquivo de caminho de E/S lento
Agora, e se eu colocar o arquivo em um caminho de E/S lento? A tabela a seguir mostra as solicitações de lote antes e depois por segundo ao habilitar uma sessão XE com um destino de arquivo em um pendrive:
| Solicitações de lote de linha de base por segundo (média de 2 minutos) | Solicitações em lote do SQL Profiler por segundo (média de 2 minutos) |
|---|---|
| 14.492 | 4.386 |
Os principais tipos de espera foram os seguintes:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.046 |
| SLEEP_TASK | 253 | 180.719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.427 |
| LAZYWRITER_SLEEP | 120 | 120.190 |
| HADR_WORK_QUEUE | 12 | 120.025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| AGUARDE | 1 | 120.002 |
| DIRTY_PAGE_POLL | 1.197 | 119.977 |
| XE_TIMER_EVENT | 59 | 119.949 |
Novamente, nada relacionado ao XE saltando, exceto para o
XE_TIMER_EVENT . Eventos estendidos para um destino de arquivo de caminho de E/S lento, sem perda de evento
A tabela a seguir mostra as solicitações de lote antes e depois por segundo ao habilitar uma sessão XE com um destino de arquivo em um pendrive, mas desta vez sem permitir a perda de eventos (EVENT_RETENTION_MODE=NO_EVENT_LOSS) – o que não é recomendado e você verá nos resultados por que isso pode ser:
| Solicitações de lote de linha de base por segundo (média de 2 minutos) | Solicitações em lote do SQL Profiler por segundo (média de 2 minutos) |
|---|---|
| 14.492 | 539 |
Os principais tipos de espera foram os seguintes:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8.773 | 1.707.845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 337 | 180.446 |
| LAZYWRITER_SLEEP | 120 | 120.032 |
| DIRTY_PAGE_POLL | 1.198 | 120.026 |
| HADR_WORK_QUEUE | 12 | 120.009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
| AGUARDE | 1 | 120.000 |
| XE_TIMER_EVENT | 59 | 119.944 |
Com a redução extrema da taxa de transferência, vemos
XE_BUFFERMGR_FREEBUF_EVENT salte para a posição número um em nossos resultados de tempo de espera acumulados. Este é documentado nos Manuais Online, e a Microsoft nos informa que esse evento está associado a sessões XE configuradas para nenhuma perda de evento e onde todos os buffers da sessão estão cheios. Impacto do Observador
Deixando de lado os tipos de espera, foi interessante observar o impacto que cada método de observação teve na capacidade de nossa carga de trabalho de processar solicitações em lote:
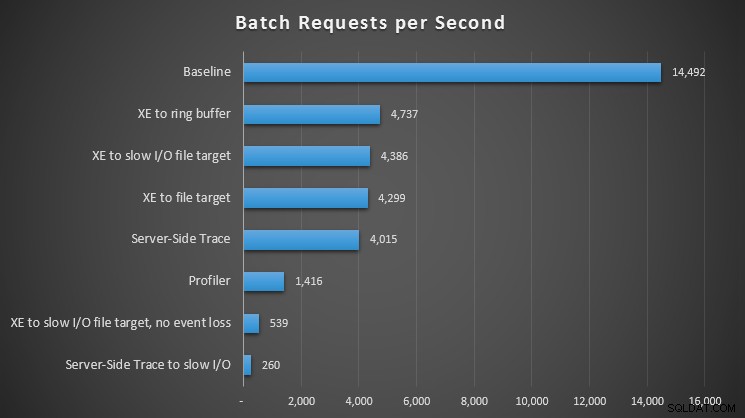
Impacto de diferentes métodos de observação em solicitações de lote por segundo
Para todas as abordagens, houve um acerto significativo – mas não chocante – em comparação com nossa linha de base (sem observação); a maior dor, no entanto, foi sentida ao usar o Profiler, ao usar o Rastreamento do lado do servidor para um caminho de E/S lento ou Eventos estendidos para um destino de arquivo em um caminho de E/S lento – mas somente quando configurado para nenhuma perda de evento. Com a perda de eventos, essa configuração realmente foi executada no mesmo nível de um destino de arquivo para um caminho de E/S rápido, presumivelmente porque foi capaz de descartar muito mais eventos.
Resumo
Eu não testei todos os cenários possíveis e certamente existem outras combinações interessantes (sem mencionar comportamentos diferentes com base na versão do SQL Server), mas a principal conclusão que tiro dessa exploração é que você não pode sempre confiar em um acúmulo óbvio de tipo de espera ponteiro ao enfrentar um cenário de sobrecarga do observador. Com base nos testes desta postagem, apenas três dos sete cenários manifestaram um tipo de espera específico que poderia ajudar a apontar na direção certa. Mesmo assim – esses testes estavam em um sistema controlado – e muitas vezes as pessoas filtram os tipos de espera mencionados acima como tipos de plano de fundo benignos – para que você não os veja.
Diante disso, o que você pode fazer? Para degradação de desempenho sem sintomas claros ou óbvios, recomendo ampliar o escopo para perguntar sobre rastreamentos e sessões XE (como um aparte – também recomendo ampliar seu escopo se o sistema estiver virtualizado ou tiver opções de energia incorretas). Por exemplo, como parte da solução de problemas de um sistema, verifique
sys.[traces] e sys.[dm_xe_sessions] para ver se algo está sendo executado no sistema que é inesperado. É uma camada extra para o que você precisa se preocupar, mas fazer algumas validações rápidas pode economizar uma quantidade significativa de tempo.