Os índices de hash são parte integrante dos bancos de dados. Se você já usou um banco de dados, é provável que você os tenha visto em ação sem nem perceber.
Os índices de hash diferem no trabalho de outros tipos de índices porque armazenam valores em vez de ponteiros para registros localizados em um disco. Isso garante uma pesquisa e inserção mais rápidas no índice. É por isso que os índices de hash são frequentemente usados como chaves primárias ou identificadores exclusivos.
Compreendendo os índices de hash
Um índice de hash é um tipo de índice que é mais comumente usado no gerenciamento de dados. Normalmente é criado em uma coluna que contém valores exclusivos, como uma chave primária ou endereço de e-mail. O principal benefício de usar índices de hash é seu desempenho rápido.
O conceito por trás desses índices pode ser sofisticado para alguém que nunca ouviu falar deles antes. No entanto, é importante entender os índices de hash se você precisar entender como os bancos de dados funcionam. É necessário para resolver problemas comuns relacionados a bancos de dados e sua velocidade.
A boa notícia é que com um pouco de paciência e um celular desligado, você pode dominar os índices de hash com certeza! Então, vamos dar uma olhada melhor.
Rápido e fácil
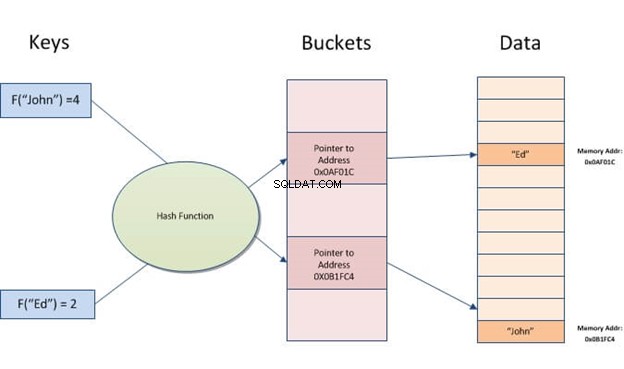
Um índice de hash é uma estrutura de dados que pode ser usada para acelerar consultas de banco de dados. Ele funciona convertendo registros de entrada em uma matriz de buckets. Cada bucket tem o mesmo número de registros que todos os outros buckets da tabela. Assim, não importa quantos valores diferentes você tenha para uma coluna específica, cada linha sempre será mapeada para um bucket.
Índices de hash permitem pesquisas rápidas em dados armazenados em tabelas. Eles funcionam criando uma chave de índice a partir do valor e, em seguida, localizando-a com base no hash resultante. É útil quando há muitas entradas com valores semelhantes ou duplicados, pois ele só precisa comparar chaves em vez de examinar todos os registros.
Isso não foi rápido nem fácil? Para entender como os índices de hash funcionam e por que eles são tão poderosos, você precisa entender o que significa hash.
Hashing é pegar uma informação (uma string) e transformá-la em um endereço ou ponteiro para acesso rápido mais tarde.
A ideia do hashing é que os dados sejam atribuídos a um pequeno número. Quando você está pesquisando os dados, você não precisa realmente peneirar as massas. Em vez disso, basta procurar esse número. O exemplo mais simples é Ctrl+F-ing a palavra que você está procurando em um texto em vez de ler dezenas de páginas você mesmo.
Para que servem os índices de hash?
Um índice de hash é uma maneira de acelerar o processo de pesquisa. Com índices tradicionais, você precisa examinar todas as linhas para garantir que sua consulta seja bem-sucedida. Mas com índices de hash, esse não é o caso!
Cada chave do índice contém apenas uma linha dos dados da tabela e usa o algoritmo de indexação chamado hashing que atribui a eles uma localização única na memória, eliminando todas as outras chaves com valores duplicados antes de encontrar o que está procurando.
Os índices de hash são uma das muitas maneiras de organizar dados em um banco de dados. Eles funcionam pegando entradas e usando-as como uma chave para armazenamento em um disco. Essas chaves ou valores de hash , pode ser qualquer coisa, desde comprimentos de string até caracteres na entrada.
Os índices de hash são mais comumente usados ao consultar entradas específicas com atributos específicos. Por exemplo, pode encontrar todas as letras A com mais de 10 cm. Você pode fazer isso rapidamente criando uma função de índice de hash.
Os índices de hash fazem parte do sistema de banco de dados PostgreSQL. Este sistema foi desenvolvido para aumentar a velocidade e o desempenho. Os índices de hash podem ser usados em conjunto com outros tipos de índice, como B-tree ou GiST.
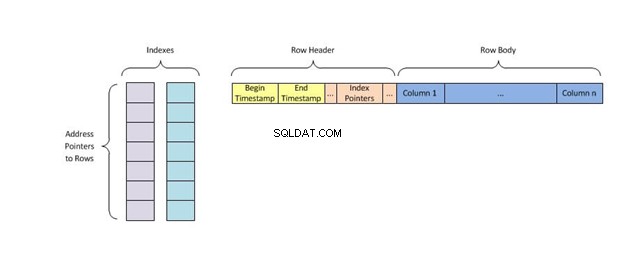
Um índice de hash armazena chaves dividindo-as em pedaços menores chamados buckets, onde cada bucket recebe um número de ID inteiro para recuperá-lo rapidamente ao pesquisar a localização de uma chave na tabela de hash. Os buckets são armazenados sequencialmente em um disco para que os dados que contêm possam ser acessados rapidamente.
Mais explicações técnicas podem ser encontradas nesta página (clique com o botão direito do mouse e escolha “Traduzir para inglês”).
Vantagens
A principal vantagem do uso de índices de hash é que eles permitem acesso rápido ao recuperar o registro pelo valor da chave. Geralmente é útil para consultas com uma condição de igualdade. Além disso, usar benchmarks de hash não exigirá muito espaço de armazenamento. Assim, é uma ferramenta eficaz, mas não sem inconvenientes.
Desvantagens
Os índices de hash são uma estrutura de indexação relativamente nova com o potencial de fornecer benefícios significativos de desempenho. Você pode pensar neles como uma extensão das árvores de busca binária (BSTs).
Os índices de hash funcionam armazenando dados em buckets com base em seus valores de hash, o que permite a recuperação rápida e eficiente dos dados. Eles são garantidos para estar em ordem.
No entanto, é impossível armazenar chaves duplicadas em um bucket. Portanto, sempre haverá alguma sobrecarga. Mas até agora, os prós de usar índices de hash superam os contras.
Como tudo funciona com um pouco mais de profundidade?
Vamos fazer uma demonstração aviasales banco de dados para obter uma compreensão mais profunda de como os índices de hash funcionam.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Aqui você pode ver como estamos implementando índices de hash compilando dados em conjuntos.
Este é um exemplo fácil, mas observe que as limitações vêm com menos infraestrutura de código. Pode haver falta de acesso ao log WAL ou incapacidade de recuperar índices (índices?) após uma falha. Além disso, os índices podem não participar da replicação – é porque o PostgreSQL está desatualizado. No entanto, assim como no Python, você recebe avisos que geralmente permitem evitar erros.
Você pode dar uma olhada mais profunda nesses índices se estiver suficientemente intrigado. Para isso, estamos criando uma inspeção de página instância de extensão.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Se você quiser inspecionar completamente o código, comece com README.
Resumo
Os índices de hash são uma estrutura de dados que agiliza o processo de busca de informações em grandes bancos de dados. Eles trabalham dividindo os dados em pedaços menores e depois classificando-os. Assim, quando você procura por algo, pode encontrá-lo muito mais rápido.
Se você quiser procurar mais coisas, há recursos para DYOR. Além disso, fique de olho em nossos novos artigos, que estão saindo mais rápido do que você pode pressionar Ctrl+F a palavra “hash” nesta página. Espero que isto ajude!