As alterações na representação interna de tabelas particionadas entre o SQL Server 2005 e o SQL Server 2008 resultaram em planos de consulta e desempenho aprimorados na maioria dos casos (especialmente quando a execução paralela está envolvida). Infelizmente, as mesmas alterações fizeram com que algumas coisas que funcionavam bem no SQL Server 2005 de repente não funcionassem tão bem no SQL Server 2008 e posterior. Esta postagem analisa um exemplo em que o otimizador de consulta do SQL Server 2005 produziu um plano de execução superior em comparação com versões posteriores.
Tabela de amostra e dados
Os exemplos nesta postagem usam a seguinte tabela e dados particionados:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Layout de dados particionados
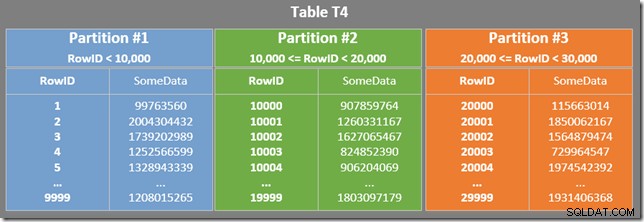
Nossa tabela tem um índice clusterizado particionado. Nesse caso, a chave de cluster também serve como chave de particionamento (embora isso não seja um requisito, em geral). O particionamento resulta em unidades de armazenamento físico separadas (conjuntos de linhas) que o processador de consulta apresenta aos usuários como uma entidade única.
O diagrama abaixo mostra as três primeiras partições da nossa tabela (clique para ampliar):
O índice não clusterizado é particionado da mesma maneira (está “alinhado”):

Cada partição do índice não clusterizado abrange um intervalo de valores RowID. Dentro de cada partição, os dados são ordenados por SomeData (mas os valores RowID não serão ordenados em geral).
O problema MIN/MAX
É razoavelmente conhecido que
MIN e MAX as agregações não otimizam bem em tabelas particionadas (a menos que a coluna que está sendo agregada também seja a coluna de particionamento). Essa limitação (que ainda existe no SQL Server 2014 CTP 1) foi escrita muitas vezes ao longo dos anos; minha cobertura favorita está neste artigo de Itzik Ben-Gan. Para ilustrar brevemente o problema, considere a seguinte consulta:SELECT MIN(SomeData) FROM dbo.T4;
O plano de execução no SQL Server 2008 ou superior é o seguinte:

Esse plano lê todas as 150.000 linhas do índice e um Stream Aggregate calcula o valor mínimo (o plano de execução é essencialmente o mesmo se solicitarmos o valor máximo). O plano de execução do SQL Server 2005 é um pouco diferente (embora não melhor):
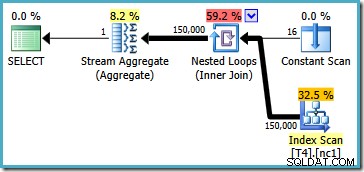
Esse plano itera sobre os números de partição (listados na Verificação Constante) verificando completamente uma partição de cada vez. Todas as 150.000 linhas ainda são eventualmente lidas e processadas pelo Stream Aggregate.
Reveja a tabela particionada e os diagramas de índice e pense em como a consulta pode ser processada de forma mais eficiente em nosso conjunto de dados. O índice não clusterizado parece uma boa opção para resolver a consulta porque contém valores SomeData em uma ordem que pode ser explorada ao calcular a agregação.
Agora, o fato de o índice ser particionado complica um pouco:cada partição do índice é ordenado pela coluna SomeData, mas não podemos simplesmente ler o valor mais baixo de qualquer particular partição para obter a resposta certa para toda a consulta.
Uma vez que a natureza essencial do problema é compreendida, um ser humano pode ver que uma estratégia eficiente seria encontrar o valor mais baixo de SomeData em cada partição do índice e, em seguida, obtenha o valor mais baixo dos resultados por partição.
Esta é essencialmente a solução que Itzik apresenta em seu artigo; reescrever a consulta para calcular um agregado por partição (usando
APPLY sintaxe) e, em seguida, agregue novamente sobre esses resultados por partição. Usando essa abordagem, o MIN reescrito query produz este plano de execução (veja o artigo de Itzik para a sintaxe exata):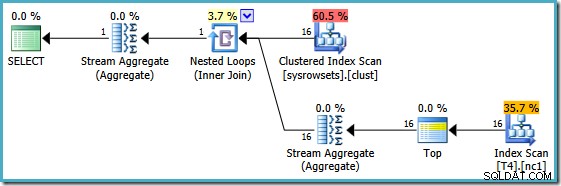
Este plano lê números de partição de uma tabela de sistema e recupera o valor mais baixo de SomeData em cada partição. O Stream Aggregate final apenas calcula o mínimo sobre os resultados por partição.
O recurso importante neste plano é que ele lê uma linha única de cada partição (explorando a ordem de classificação do índice dentro de cada partição). É muito mais eficiente do que o plano do otimizador que processou todas as 150.000 linhas da tabela.
MIN e MAX em uma única partição
Agora considere a seguinte consulta para encontrar o valor mínimo na coluna SomeData, para um intervalo de valores RowID contidos em uma única partição :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Vimos que o otimizador tem problemas com
MIN e MAX em várias partições, mas esperamos que essas limitações não se apliquem a uma única consulta de partição. A partição única é aquela limitada pelos valores RowID 10.000 e 20.000 (consulte a definição da função de particionamento). A função de particionamento foi definida como
RANGE RIGHT , portanto, o valor do limite de 10.000 pertence à partição nº 2 e o limite de 20.000 pertence à partição nº 3. O intervalo de valores RowID especificado por nossa nova consulta está, portanto, contido apenas na partição 2. Os planos de execução gráfica para esta consulta têm a mesma aparência em todas as versões do SQL Server a partir de 2005:
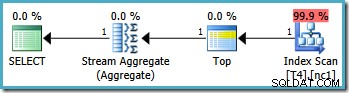
Análise do plano
O otimizador pegou o intervalo RowID especificado no
WHERE cláusula e a comparou com a definição da função de partição para determinar que apenas a partição 2 do índice não clusterizado precisava ser acessada. As propriedades do plano do SQL Server 2005 para o Index Scan mostram claramente o acesso de partição única: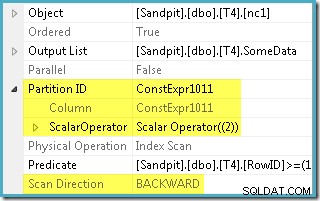
A outra propriedade destacada é a Direção de Varredura. A ordem da verificação difere dependendo se a consulta está procurando o valor mínimo ou máximo de SomeData. O índice não clusterizado é ordenado (por partição, lembre-se) em valores crescentes de SomeData, de modo que a direção do Index Scan é
FORWARD se a consulta solicitar o valor mínimo e BACKWARD se o valor máximo for necessário (a captura de tela acima foi tirada do MAX plano de consulta). Há também um Predicado residual na Varredura de Índice para verificar se os valores de RowID varridos da partição 2 correspondem ao
WHERE predicado da oração. O otimizador assume que os valores RowID são distribuídos de forma bastante aleatória por meio do índice não clusterizado, portanto, espera encontrar a primeira linha que corresponda ao WHERE predicado de cláusula muito rapidamente. O diagrama de layout de dados particionado mostra que os valores RowID são realmente distribuídos aleatoriamente no índice (que é ordenado pela coluna SomeData, lembre-se):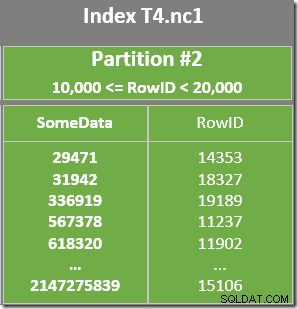
O operador Top no plano de consulta limita a Varredura do Índice a uma única linha (da extremidade inferior ou superior do índice, dependendo da Direção da Varredura). As varreduras de índice podem ser problemáticas em planos de consulta, mas o operador Top o torna uma opção eficiente aqui:a varredura só pode produzir uma linha e depois para. A combinação de varredura de índice superior e ordenada executa efetivamente uma busca para o valor mais alto ou mais baixo no índice que também corresponde ao
WHERE predicados de cláusula. Um Stream Aggregate também aparece no plano para garantir que um NULL é gerado caso nenhuma linha seja retornada pelo Index Scan. Escalar MIN e MAX agregados são definidos para retornar um NULL quando a entrada é um conjunto vazio. No geral, essa é uma estratégia muito eficiente, e os planos têm um custo estimado de apenas 0,0032921 unidades como resultado. Até agora tudo bem.
O problema do valor do limite
Este próximo exemplo modifica a extremidade superior do intervalo RowID:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Observe que a consulta exclui o valor de 20.000 usando um operador "menor que". Lembre-se de que o valor 20.000 pertence à partição 3 (não à partição 2) porque a função de partição é definida como
RANGE RIGHT . O SQL Server 2005 otimizador lida com essa situação corretamente, produzindo o plano de consulta de partição única ideal, com um custo estimado de 0,0032878 :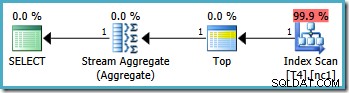
No entanto, a mesma consulta produz um plano diferente no SQL Server 2008 e posterior (incluindo SQL Server 2014 CTP 1):
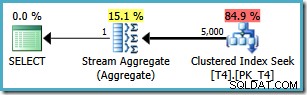
Agora temos uma Busca de Índice Agrupado (em vez da combinação desejada de Varredura de Índice e Operador Superior). Todas as 5.000 linhas que correspondem a
WHERE cláusula são processados por meio do Stream Aggregate neste novo plano de execução. O custo estimado deste plano é 0,0199319 unidades – mais de seis vezes o custo do plano SQL Server 2005. Causa
Os otimizadores do SQL Server 2008 (e posteriores) não obtêm a lógica interna correta quando um intervalo faz referência, mas exclui , um valor de limite pertencente a uma partição diferente. O otimizador pensa incorretamente que várias partições serão acessadas e conclui que não pode usar a otimização de partição única para
MIN e MAX agregados. Soluções alternativas
Uma opção é reescrever a consulta usando os operadores>=e <=para não referenciar um valor de limite de outra partição (mesmo para excluí-lo!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Isso resulta no plano ideal, tocando em uma única partição:
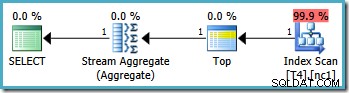
Infelizmente, nem sempre é possível especificar valores de limite corretos dessa maneira (dependendo do tipo de coluna de particionamento). Um exemplo disso é com tipos de data e hora em que é melhor usar intervalos semiabertos. Outra objeção a essa solução alternativa é mais subjetiva:a função de particionamento exclui um limite do intervalo, portanto, parece mais natural escrever a consulta também usando a sintaxe de intervalo meio aberto.
Uma segunda solução alternativa é especificar o número da partição explicitamente (e mantendo o intervalo meio aberto):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Isso produz o plano ideal, ao custo de exigir um predicado extra e depender do usuário para descobrir qual deve ser o número da partição.
É claro que seria melhor se os otimizadores de 2008 e posteriores produzissem o mesmo plano ideal do SQL Server 2005. Em um mundo perfeito, uma solução mais abrangente também abordaria o caso de várias partições, tornando desnecessária a solução alternativa descrita por Itzik.