Estamos explorando a migração de um banco de dados Oracle de uma instância do EC2 para um RDS de serviço gerenciado. No primeiro de quatro artigos, “Migrando um banco de dados Oracle do AWS EC2 para o AWS RDS, Parte 1”, criamos instâncias de banco de dados no EC2 e RDS. No segundo artigo, “Migrando um banco de dados Oracle do AWS EC2 para o AWS RDS, parte 2”, criamos um usuário do IAM para migração de banco de dados e também criamos uma tabela de banco de dados para migrar. Apenas no segundo artigo, criamos uma instância de replicação e endpoints de replicação. No terceiro artigo, “Migrando um banco de dados Oracle do AWS EC2 para o AWS RDS, Parte 3”, criamos uma tarefa de migração para migrar as alterações existentes. Neste artigo de continuação, migraremos as alterações contínuas dos dados. Este artigo tem as seguintes seções:
- Criando e executando uma tarefa de replicação para migrar alterações contínuas
- Adicionando registros complementares
- Adicionando uma tabela a uma instância de banco de dados Oracle no EC2
- Adicionando dados da tabela
- Explorando a tabela de banco de dados replicada
- Descartando e recarregando dados
- Parando e iniciando uma tarefa
- Exclusão de bancos de dados
- Conclusão
Criação e execução de uma tarefa de replicação para migrar alterações contínuas
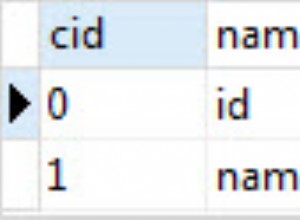
Nas subseções a seguir, criaremos uma tarefa para replicar as mudanças em andamento. Para demonstrar a replicação contínua, devemos primeiro iniciar a tarefa e, posteriormente, criar uma tabela e adicionar dados. Elimine a tabela DVOHRA.WLSLOG , como mostrado na Figura 1; estaremos criando a mesma tabela para demonstrar a replicação contínua.

Figura 1: Eliminando a Tabela DVOHRA.WLSLOG
Adicionando Log Suplementar
Serviço de migração de banco de dados requer que o log complementar seja habilitado para habilitar a captura de dados de alteração (CDC) que é usada para replicar alterações em andamento. O log complementar é o processo de armazenamento de informações sobre quais linhas de dados em uma tabela foram alteradas. O log suplementar adiciona dados de coluna suplementares ou extras em arquivos de log de redo sempre que uma atualização em uma tabela é executada. As colunas que foram alteradas são registradas como dados suplementares em arquivos de redo log junto com uma chave de identificação, que pode ser a chave primária ou o índice exclusivo. Se uma tabela não tiver uma chave primária ou um índice exclusivo, todas as colunas escalares serão registradas nos arquivos de redo log para identificar exclusivamente uma linha de dados, o que pode aumentar o tamanho dos arquivos de redo log. O Oracle Database oferece suporte aos seguintes tipos de log suplementar:
- Registro suplementar mínimo: Apenas a quantidade mínima de dados exigida pelo LogMiner para as alterações de DML é registrada nos arquivos de redo log.
- Registro de chave de identificação no nível do banco de dados: Diferentes tipos de registro de chave de identificação de nível de banco de dados são suportados—ALL, PRIMARY KEY, UNIQUE e FOREIGN KEY. Com o nível ALL, todas as colunas (exceto LOBs, Longs e ADTs) são registradas em arquivos de redo log. Para PRIMARY KEY, somente colunas de chave primária são armazenadas em arquivos de log de redo quando uma linha contendo uma chave primária é atualizada; não é necessário que uma coluna de chave primária seja atualizada. O tipo FOREIGN KEY armazena apenas as chaves estrangeiras de uma linha em arquivos de redo log quando qualquer um dos arquivos de log vermelhos é atualizado. O tipo UNIQUE armazena apenas as colunas em uma chave composta exclusiva ou índice de bitmap quando qualquer coluna na chave composta exclusiva ou índice de bitmap for alterada.
- Registro complementar no nível da tabela: Especifica no nível da tabela quais colunas são armazenadas em arquivos de log de redo. O registro de chave de identificação em nível de tabela suporta os mesmos níveis do registro de chave de identificação em nível de banco de dados; TODOS, CHAVE PRIMÁRIA, ÚNICA e CHAVE ESTRANGEIRA. No nível da tabela, os grupos de log complementares definidos pelo usuário também são suportados, o que permite que um usuário defina quais colunas devem ser logadas de forma complementar. Os grupos de log complementares definidos pelo usuário podem ser condicionais ou incondicionais.
Para replicação contínua, precisamos definir o log complementar mínimo e o log complementar no nível da tabela para TODAS as colunas.
No SQL*Plus, execute a seguinte instrução para definir o log complementar mínimo:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
A saída é a seguinte:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; Database altered.
Para localizar o status do log complementar mínimo, execute a instrução a seguir. E, se a saída tiver um valor de coluna SUPPLEME como YES, o log complementar mínimo será ativado.
SQL> SELECT supplemental_log_data_min FROM v$database; SUPPLEME -------- YES
A configuração do registro suplementar mínimo e a verificação da saída de status são mostradas na Figura 2.
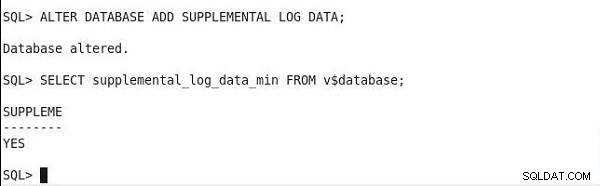
Figura 2: Configurando e Verificando o Log Suplementar Mínimo
Também devemos definir o registro de chave de identificação em nível de tabela quando adicionarmos dados de tabela e tabela para demonstrar a replicação contínua após o início da tarefa. Se adicionarmos dados de tabela e tabela antes de criar e iniciar uma tarefa, não poderemos demonstrar a replicação contínua.
Para criar uma tarefa para replicação contínua, clique em Criar tarefa , como mostrado na Figura 3.

Figura 3: Tarefas>Criar tarefa
Em Criar tarefa assistente, especifique um nome e uma descrição da tarefa e selecione a instância de replicação, o endpoint de origem e o endpoint de destino, conforme mostrado na Figura 4. Selecione Tipo de migração como Migrar dados existentes e replicar alterações em andamento .
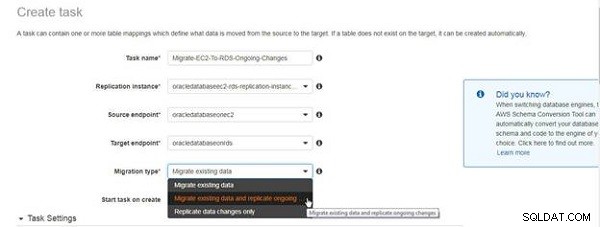
Figura 4: Selecionando o tipo de migração para replicação contínua
Uma mensagem mostrada na Figura 5 indica que o log complementar deve ser ativado para replicação contínua. A mensagem não é para indicar que o log complementar não foi ativado, mas apenas como um lembrete. Já ativamos o log complementar. Marque a caixa de seleção Iniciar tarefa ao criar .
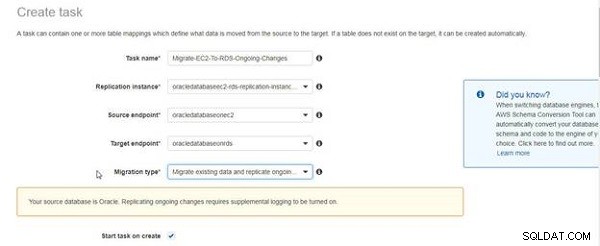
Figura 5: Mensagem sobre o requisito de log complementar para replicar alterações em andamento
As Configurações de tarefas são os mesmos para migrar apenas os dados existentes (consulte a Figura 6).
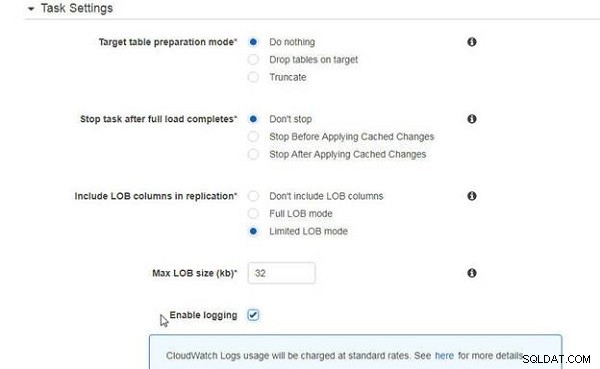
Figura 6: Configurações da tarefa
Para mapeamentos de tabela, é necessária pelo menos uma regra de seleção. Adicione uma regra de seleção para incluir todas as tabelas no DVOHRA tabela, como mostrado na Figura 7.
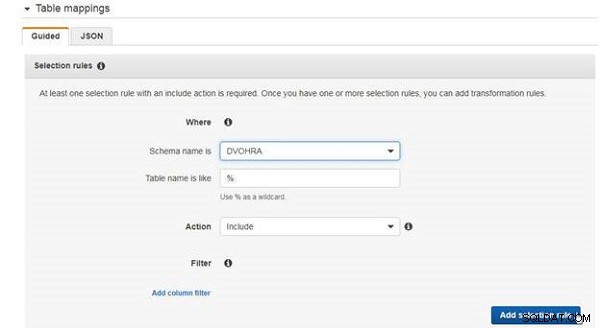
Figura 7: Adicionando uma regra de seleção
A regra de seleção adicionada é mostrada na Figura 8.
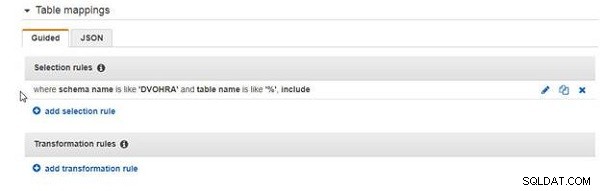
Figura 8: Regra de seleção
Clique em Criar tarefa para criar a tarefa, conforme mostrado na Figura 9.
Figura 9: Criar tarefa
Uma nova tarefa é adicionada com status como Criando , como mostrado na Figura 10.

Figura 10: Tarefa adicionada com status Criando
Quando as regras de seleção e transformação para todos os dados existentes forem aplicadas e os dados migrados, o status da tarefa se tornará Carregamento concluído, replicação em andamento (ver Figura 11).

Figura 11: Carregamento concluído, replicação em andamento
As Estatísticas da tabela A guia não lista nenhuma tabela como tendo sido migrada ou replicada, conforme mostrado na Figura 12.
Figura 12: Estatísticas da tabela
Para explorar os logs do CloudWatch, clique em Logs guia e clique no link, conforme mostrado na Figura 13.
Figura 13: Histórico
Os logs do CloudWatch são exibidos, conforme mostrado na Figura 14. A última entrada nos logs é sobre o início da replicação. A tarefa de replicação em andamento não termina após carregar os dados existentes, se houver, mas continua em execução.
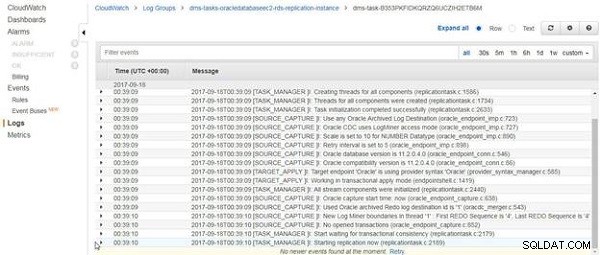
Figura 14: Registros do CloudWatch
Adicionando uma tabela a uma instância de banco de dados Oracle no EC2
Em seguida, crie uma tabela e adicione dados de tabela para demonstrar a replicação contínua. Execute as duas instruções a seguir juntas para que o log complementar no nível da tabela seja definido quando a tabela for criada. Modifique o script para tornar o esquema diferente.
CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY, category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns;
O log complementar no nível da tabela é definido quando a tabela é criada.
SQL> CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY,category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns; Table created. SQL> Table altered.
A saída é mostrada no SQL*Plus na Figura 15.
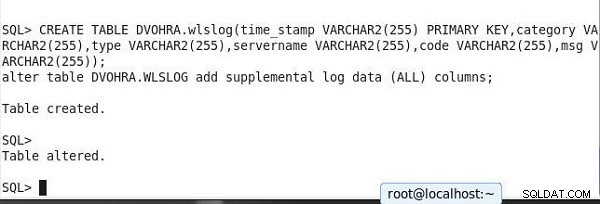
Figura 15: Criando Tabela e definindo Log Suplementar
Até agora, criamos apenas a tabela e não adicionamos nenhum dado da tabela. O DDL da tabela é migrado, conforme indicado pelas estatísticas da tabela na Figura 16.
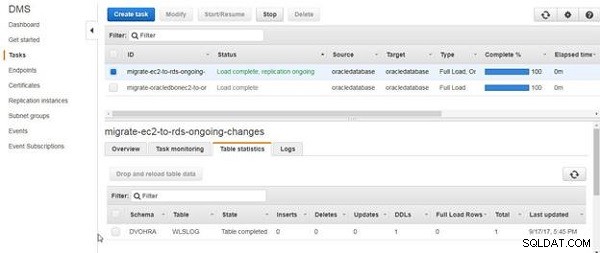
Figura 16: DDLs para tabela migrada
Adicionando dados da tabela
Em seguida, execute o seguinte script SQL para adicionar dados à tabela criada. Modifique o script para tornar o esquema diferente.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:16-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000365','Server
state changed to STANDBY');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:17-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to STARTING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:18-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to ADMIN');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:19-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RESUMING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:20-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000361','Started WebLogic
AdminServer');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:21-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RUNNING');
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
Em seguida, execute a instrução Commit.
SQL> COMMIT; Commit complete.
Explorando a tabela de banco de dados replicada
As estatísticas da Tabela listam as inserções como o número de linhas de dados adicionadas, conforme mostrado na Figura 17.
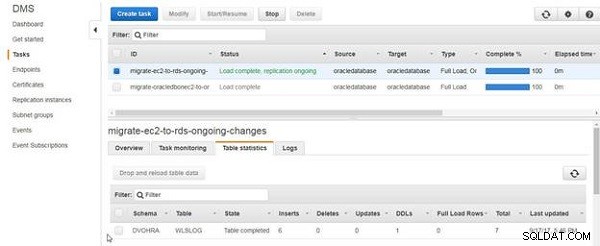
Figura 17: Lista de estatísticas da tabela 6 inserções
A tarefa continua a ser executada após a replicação das alterações em andamento. Adicione outra linha de dados.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:22-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000360','Server
started in RUNNING mode');
1 row created.
SQL> COMMIT;
Commit complete.
SQL>
Clique em Atualizar dados do servidor, conforme mostrado na Figura 18.
Figura 18: Atualizar dados do servidor
O número total de estatísticas de inserções na tabela se torna 7, conforme mostrado na Figura 19.
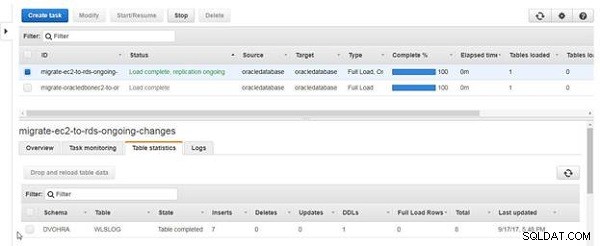
Figura 19: Estatísticas de tabela com inserções como 7
Descartando e recarregando dados
Para descartar e recarregar dados da tabela, clique em Descartar e recarregar dados da tabela , como mostrado na Figura 20.
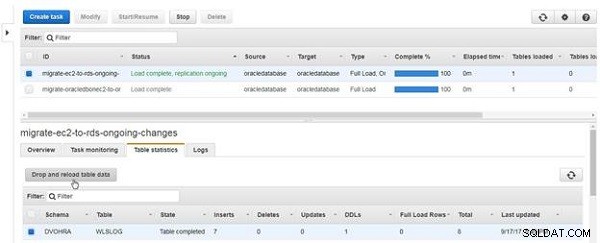
Figura 20: Soltar e recarregar dados da tabela
Clique em Atualizar dados do servidor (ver Figura 21).
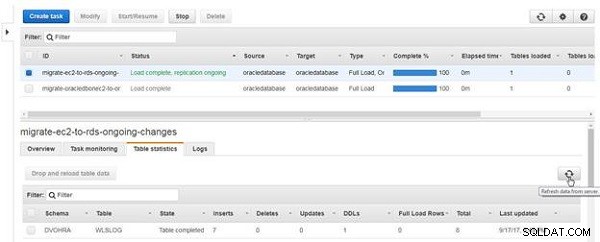
Figura 21: Atualizar dados do servidor
O ícone e o Estado coluna para a tabela indica que a tabela está sendo recarregada, conforme mostrado na Figura 22.
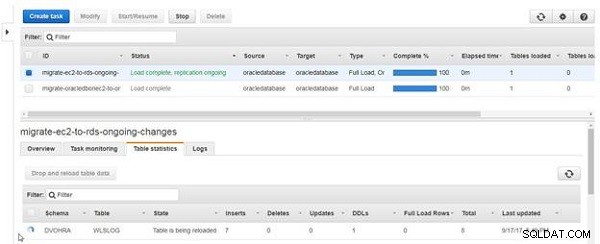
Figura 22: A tabela está sendo recarregada
Quando o recarregamento da tabela for concluído, a coluna Estado da tabela se tornará Tabela concluída , conforme mostrado na Figura 23. Após recarregar os dados da tabela, as Linhas de carregamento completo exibe um valor de 7 e Inserts é 0 porque um recarregamento não é uma replicação em andamento, mas um carregamento completo.
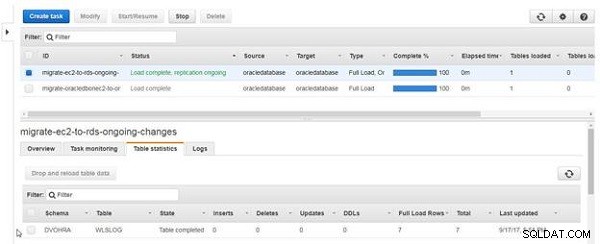
Figura 23: Recarregamento de tabela concluído
Como os dados da tabela são descartados e recarregados e os dados da tabela de origem não foram alterados, os logs do CloudWatch incluem a mensagem "Algumas alterações do banco de dados de origem não tiveram impacto quando aplicadas ao banco de dados de destino", conforme mostrado na Figura 24.
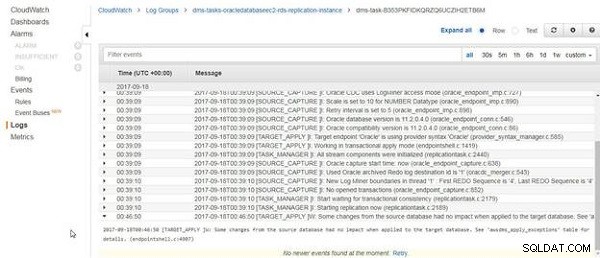
Figura 24: Algumas alterações do banco de dados de origem não tiveram impacto quando aplicadas ao banco de dados de destino
Quando o recarregamento do DVOHRA.wlslog tabela foi concluída, a mensagem “Carregamento concluído para a tabela DVOHRA.wlslog. 7 linhas recebidas” é exibida, conforme mostrado na Figura 25.
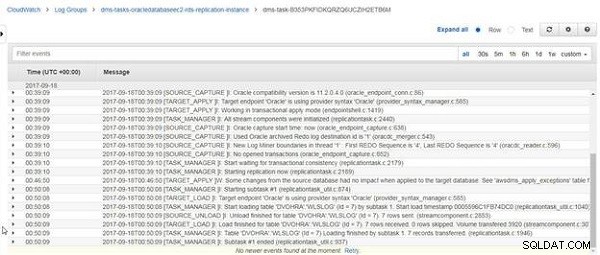
Figura 25: Mensagem de log do CloudWatch para carregamento concluído
Parando e iniciando uma tarefa
Uma tarefa do tipo que inclui replicação contínua não é interrompida sozinha, a menos que ocorra um erro. Para interromper a tarefa, clique em Parar (ver Figura 26).
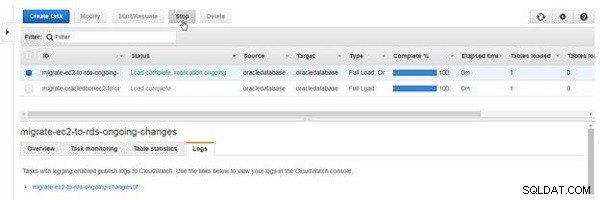
Figura 26: Parando uma tarefa
Em Parar tarefa caixa de diálogo, clique em Parar , conforme mostrado na Figura 27.
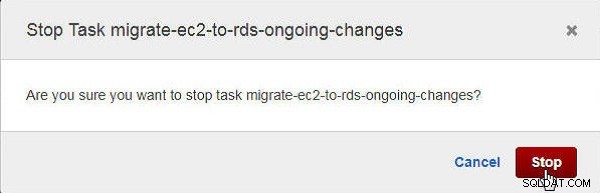
Figura 27: Caixa de diálogo de confirmação para interromper uma tarefa
O status da tarefa se torna Parando , conforme mostrado na Figura 28.
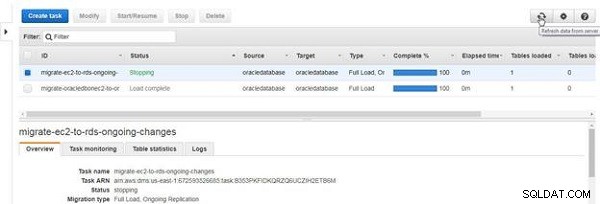
Figura 28: Parando uma tarefa
Quando uma tarefa é interrompida, o status se torna Parado , conforme mostrado na Figura 29.
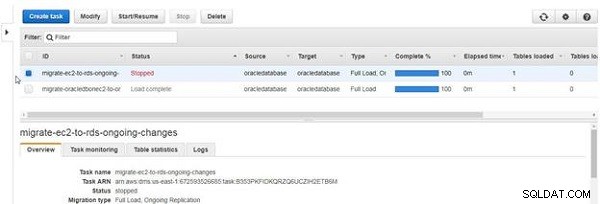
Figura 29: Tarefa interrompida
Para iniciar uma tarefa interrompida, clique em Iniciar/Retomar , como mostrado na Figura 30.
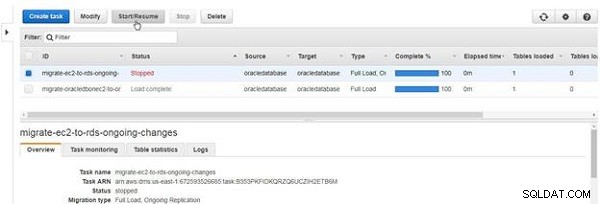
Figura 30: Iniciar ou retomar uma tarefa
Em Iniciar tarefa caixa de diálogo, clique em Iniciar para iniciar a tarefa a partir do ponto parado (consulte a Figura 31). A outra opção é reiniciar a tarefa.
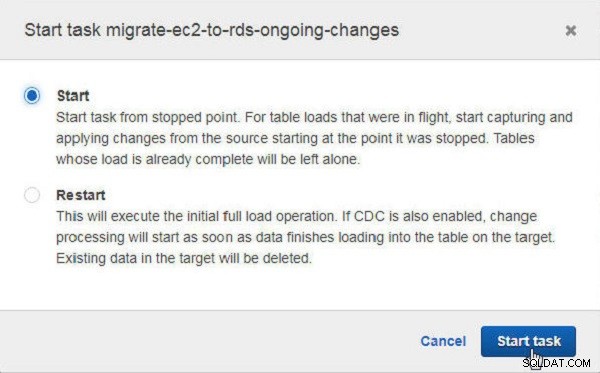
Figura 31: Iniciando Tarefa após parar
O status da tarefa se torna Iniciando , conforme mostrado na Figura 32.

Figura 32: Iniciando uma tarefa
Quando a migração dos dados existentes for concluída, a tarefa continuará sendo executada com o status como Carregamento concluído, replicação em andamento , conforme mostrado na Figura 33.

Figura 33: Carregamento concluído, replicação em andamento
Exclusão de bancos de dados
A instância de banco de dados RDS pode ser excluída com as ações da instância>Excluir comando. O banco de dados Oracle na instância do EC2 pode ser interrompido com Ações>Estado da instância>Parar , conforme mostrado na Figura 34.

Figura 34: Parando a instância do EC2
Conclusão
Em quatro artigos, discutimos a migração de um banco de dados Oracle do AWS EC2 para o AWS RDS.