No meu último post, vimos como uma consulta com um agregado escalar pode ser transformada pelo otimizador em uma forma mais eficiente. Como lembrete, aqui está o esquema novamente:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Escolhas do plano
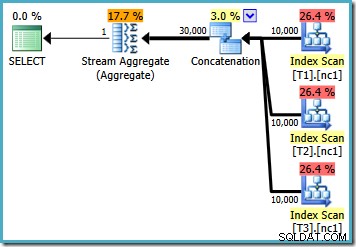
Com 10.000 linhas em cada uma das tabelas base, o otimizador apresenta um plano simples que calcula o máximo lendo todas as 30.000 linhas em um agregado:
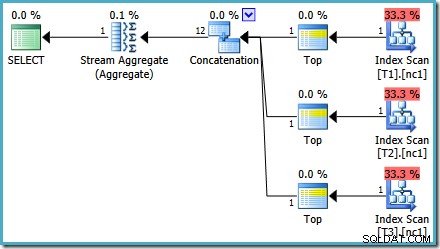
Com 50.000 linhas em cada tabela, o otimizador gasta um pouco mais de tempo no problema e encontra um plano mais inteligente. Ele lê apenas a linha superior (em ordem decrescente) de cada índice e calcula o máximo apenas dessas 3 linhas:
Um bug do otimizador
Você pode notar algo um pouco estranho nessa estimativa plano. O operador Concatenação lê uma linha de três tabelas e de alguma forma produz doze linhas! Este é um erro causado por um bug na estimativa de cardinalidade que relatei em maio de 2011. Ainda não foi corrigido no SQL Server 2014 CTP 1 (mesmo que o novo estimador de cardinalidade seja usado), mas espero que seja resolvido para o último lançamento.
Para ver como o erro surge, lembre-se de que uma das alternativas de plano consideradas pelo otimizador para o caso de 50.000 linhas tem agregações parciais abaixo do operador Concatenação:
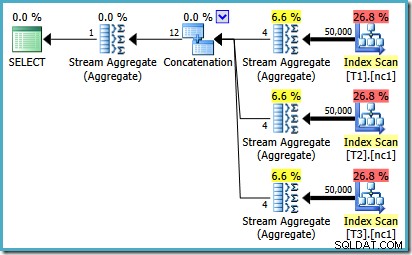
É a estimativa de cardinalidade para esses
MAX parciais agregados que estão com defeito. Eles estimam quatro linhas onde o resultado é garantido como sendo uma linha. Você pode ver um número diferente de quatro – depende de quantos processadores lógicos estão disponíveis para o otimizador no momento em que o plano é compilado (veja o link do bug acima para mais detalhes). O otimizador posteriormente substitui os agregados parciais pelos operadores Top (1), que recalculam a estimativa de cardinalidade corretamente. Infelizmente, o operador Concatenação ainda reflete as estimativas para os agregados parciais substituídos (3 * 4 =12). Como resultado, acabamos com uma concatenação que lê 3 linhas e produz 12.
Usando TOP em vez de MAX
Olhando novamente para o plano de 50.000 linhas, parece que a maior melhoria encontrada pelo otimizador é usar os operadores Top (1) em vez de ler todas as linhas e calcular o valor máximo usando força bruta. O que acontece se tentarmos algo semelhante e reescrevermos a consulta usando Top explicitamente?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
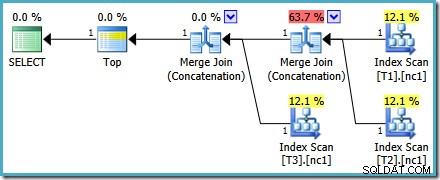
O plano de execução para a nova consulta é:
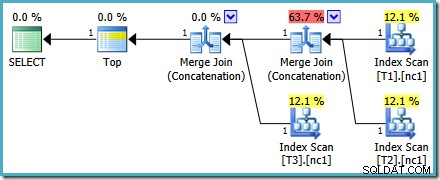
Este plano é bem diferente daquele escolhido pelo otimizador para o
MAX inquerir. Ele apresenta três varreduras de índice ordenadas, duas junções de mesclagem em execução no modo de concatenação e um único operador superior. Este novo plano de consulta tem alguns recursos interessantes que valem a pena examinar em detalhes. Análise do Plano
A primeira linha (em ordem de índice decrescente) é lida do índice não clusterizado de cada tabela, e é usada uma junção de mesclagem operando no modo de concatenação. Embora o operador Merge Join não esteja realizando uma junção no sentido normal, o algoritmo de processamento desse operador é facilmente adaptado para concatenar suas entradas em vez de aplicar critérios de junção.
O benefício de usar esse operador no novo plano é que a Concatenação de Mesclagem preserva a ordem de classificação em suas entradas. Por outro lado, um operador de concatenação regular lê suas entradas em sequência. O diagrama abaixo ilustra a diferença (clique para expandir):
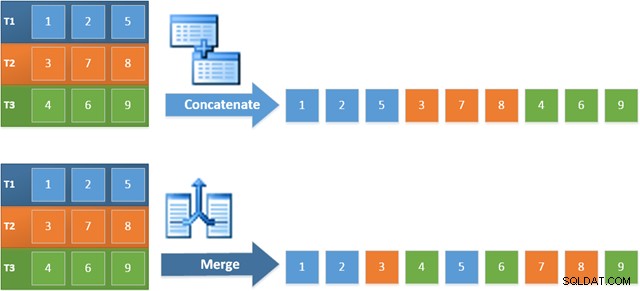
O comportamento de preservação de ordem da Concatenação de mesclagem significa que a primeira linha produzida pelo operador de mesclagem mais à esquerda no novo plano é garantida como a linha com o valor mais alto na coluna c1 em todas as três tabelas. Mais especificamente, o plano funciona da seguinte forma:
- Uma linha é lido de cada tabela (em ordem decrescente de índice); e
- Cada mesclagem realiza um teste para ver qual de suas linhas de entrada tem o valor mais alto
Esta parece uma estratégia muito eficiente, então pode parecer estranho que o
MAX do otimizador plano tem um custo estimado de menos da metade do novo plano. Em grande parte, o motivo é que a Concatenação de Mesclagem que preserva a ordem é considerada mais cara do que uma Concatenação simples. O otimizador não percebe que cada Merge só pode ver no máximo uma linha e, como resultado, superestima seu custo. Mais problemas de custo
Estritamente falando, não estamos comparando maçãs com maçãs aqui, porque os dois planos são para consultas diferentes. Comparar custos como esse geralmente não é uma coisa válida, embora o SSMS faça exatamente isso exibindo porcentagens de custo para diferentes declarações em um lote. Mas, eu discordo.
Se você observar o novo plano no SSMS em vez do SQL Sentry Plan Explorer, verá algo assim:
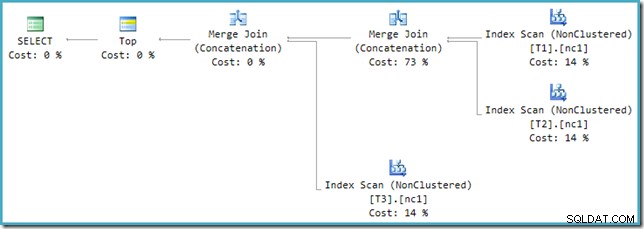
Um dos operadores Merge Join Concatenation tem um custo estimado de 73%, enquanto o segundo (operando exatamente no mesmo número de linhas) é mostrado como não custando nada. Outro sinal de que algo está errado aqui é que os percentuais de custo da operadora neste plano não somam 100%.
Otimizador versus mecanismo de execução
O problema está em uma incompatibilidade entre o otimizador e o mecanismo de execução. No otimizador, União e União Todos podem ter 2 ou mais entradas. No mecanismo de execução, apenas o operador Concatenação pode aceitar 2 ou mais entradas; O Merge Join requer exatamente duas entradas, mesmo quando configuradas para realizar uma concatenação em vez de uma junção.
Para resolver essa incompatibilidade, uma reescrita pós-otimização é aplicada para traduzir a árvore de saída do otimizador em um formato que o mecanismo de execução possa manipular. Quando um Sindicato ou Sindicato Todos com mais de dois insumos é implementado usando o Merge, é necessária uma cadeia de operadores. Com três entradas para o Union All no presente caso, dois Merge Unions são necessários:
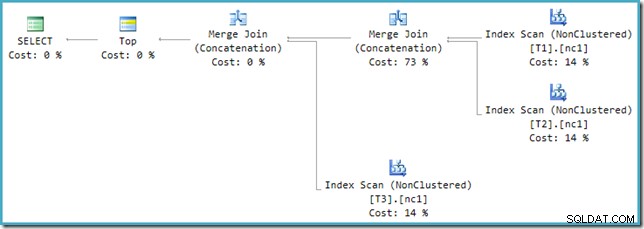
Podemos ver a árvore de saída do otimizador (com três entradas para uma união de mesclagem física) usando o sinalizador de rastreamento 8607:
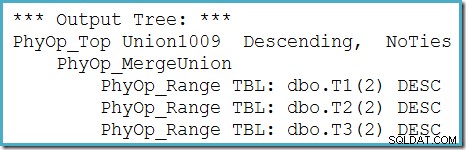
Uma correção incompleta
Infelizmente, a reescrita pós-otimização não é perfeitamente implementada. Faz um pouco de confusão dos números de custo. Arredondando questões à parte, os custos do plano somam 114% com os 14% extras provenientes da entrada para a concatenação de junção de mesclagem extra gerada pela reescrita:
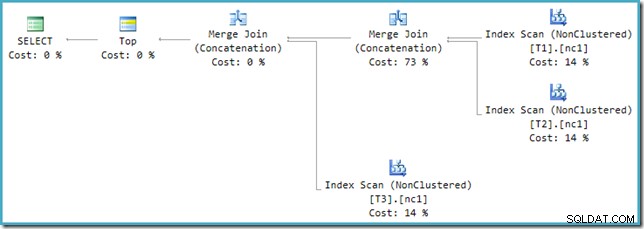
O Merge mais à direita neste plano é o operador original na árvore de saída do otimizador. É atribuído o custo total da operação Union All. A outra mesclagem é adicionada pela reescrita e recebe um custo zero.
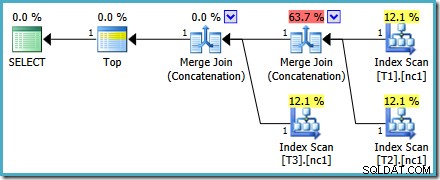
Seja qual for a maneira que escolhermos olhar para ele (e há diferentes problemas que afetam a concatenação regular), os números parecem estranhos. O Plan Explorer faz o possível para contornar as informações quebradas no plano XML, pelo menos garantindo que os números somam 100%:
Esse problema de custo específico foi corrigido no SQL Server 2014 CTP 1:
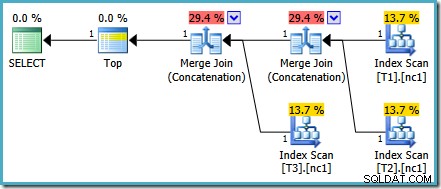
Os custos da Merge Concatenation agora são divididos igualmente entre os dois operadores, e as porcentagens somam 100%. Como o XML subjacente foi corrigido, o SSMS também consegue mostrar os mesmos números.
Qual plano é melhor?
Se escrevermos a consulta usando
MAX , temos que contar com a escolha do otimizador para realizar o trabalho extra necessário para encontrar um plano eficiente. Se o otimizador encontrar um plano aparentemente bom o suficiente no início, ele pode produzir um plano relativamente ineficiente que lê cada linha de cada uma das tabelas base: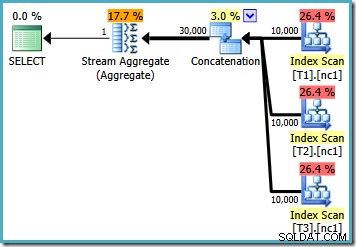
Se você estiver executando o SQL Server 2008 ou SQL Server 2008 R2, o otimizador ainda escolherá um plano ineficiente, independentemente do número de linhas nas tabelas base. O plano a seguir foi produzido no SQL Server 2008 R2 com 50.000 linhas:
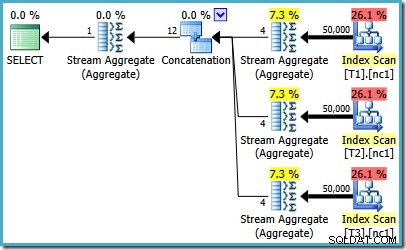
Mesmo com 50 milhões de linhas em cada tabela, o otimizador R2 2008 e 2008 apenas adiciona paralelismo, não introduz os operadores Top:
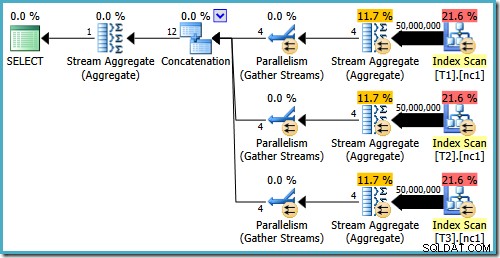
Conforme mencionado na minha postagem anterior, o sinalizador de rastreamento 4199 é necessário para obter o SQL Server 2008 e 2008 R2 para produzir o plano com os principais operadores. SQL Server 2005 e 2012 em diante não exigem o sinalizador de rastreamento:
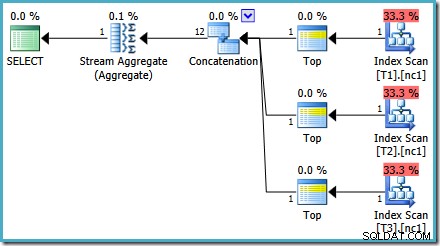
TOP com ORDER BY
Uma vez que entendemos o que está acontecendo nos planos de execução anteriores, podemos fazer uma escolha consciente (e informada) de reescrever a consulta usando um TOP explícito com ORDER BY:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
O plano de execução resultante pode ter porcentagens de custo que parecem estranhas em algumas versões do SQL Server, mas o plano subjacente é sólido. A reescrita pós-otimização que faz com que os números pareçam estranhos é aplicada após a conclusão da otimização da consulta, para que possamos ter certeza de que a seleção do plano do otimizador não foi afetada por esse problema.
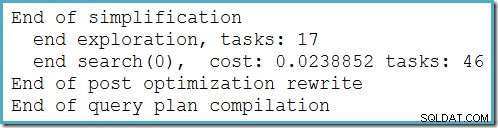
Esse plano não muda dependendo do número de linhas na tabela base e não requer nenhum sinalizador de rastreamento para ser gerado. Uma pequena vantagem extra é que esse plano é encontrado pelo otimizador durante a primeira fase da otimização baseada em custo (pesquisa 0):
O melhor plano selecionado pelo otimizador para o
MAX consulta exigia a execução de dois estágios de otimização baseada em custo (pesquisa 0 e pesquisa 1). Há uma pequena diferença semântica entre o
TOP consulta e o MAX original forma que devo mencionar. Se nenhuma das tabelas contiver uma linha, a consulta original produzirá um único NULL resultado. A substituição TOP (1) query não produz nenhuma saída nas mesmas circunstâncias. Essa diferença geralmente não é importante em consultas do mundo real, mas é algo a ser observado. Podemos replicar o comportamento de TOP usando MAX no SQL Server 2008 em diante, adicionando um conjunto vazio GROUP BY :SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Esta alteração não afeta os planos de execução gerados para o
MAX consulta de forma visível para os usuários finais. MAX com concatenação de mesclagem
Dado o sucesso da Merge Join Concatenation no
TOP (1) plano de execução, é natural se perguntar se o mesmo plano ideal poderia ser gerado para o MAX original query se forçarmos o otimizador a usar a concatenação de mesclagem em vez da concatenação regular para o UNION ALL Operação. Existe uma dica de consulta para este propósito –
MERGE UNION – mas infelizmente só funciona corretamente no SQL Server 2012 em diante. Nas versões anteriores, o UNION dica afeta apenas UNION consultas, não UNION ALL . No SQL Server 2012 em diante, podemos tentar isso:SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Somos recompensados com um plano que apresenta a Concatenação de Mesclagem. Infelizmente, não é exatamente tudo o que esperávamos:
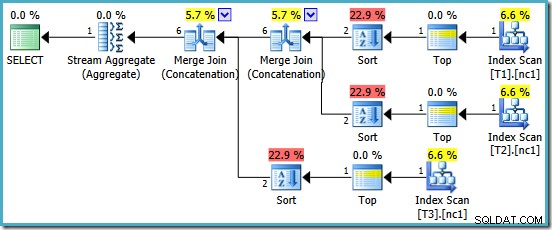
Os operadores interessantes neste plano são os tipos. Observe a estimativa de cardinalidade de entrada de 1 linha e a estimativa de 4 linhas na saída. A causa deve ser familiar para você agora:é o mesmo erro de estimativa de cardinalidade agregada parcial que discutimos anteriormente.
A presença dos tipos revela mais um problema com os agregados parciais. Eles não apenas produzem uma estimativa de cardinalidade incorreta, mas também não preservam a ordenação do índice que tornaria a classificação desnecessária (Merge Concatenation requer entradas classificadas). Os agregados parciais são escalares
MAX agregados, garantidos para produzir uma linha, então a questão da ordenação deve ser discutível de qualquer maneira (há apenas uma maneira de classificar uma linha!) Isso é uma pena, porque sem os tipos esse seria um plano de execução decente. Se os agregados parciais foram implementados corretamente e o
MAX escrito com um GROUP BY () podemos até esperar que o otimizador detecte que os três Tops e o Stream Aggregate final possam ser substituídos por um único operador Top final, fornecendo exatamente o mesmo plano que o TOP (1) explícito inquerir. O otimizador não contém essa transformação hoje e não suponho que seja útil com frequência suficiente para que sua inclusão valha a pena no futuro. Palavras Finais
Usando
TOP nem sempre será preferível a MIN ou MAX . Em alguns casos, produzirá um plano significativamente menos ideal. O ponto deste post é que entender as transformações aplicadas pelo otimizador pode sugerir maneiras de reescrever a consulta original que pode ser útil.