É muito fácil provar que as duas expressões a seguir produzem exatamente o mesmo resultado:o primeiro dia do mês atual.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); E eles levam aproximadamente a mesma quantidade de tempo para calcular:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
No meu sistema, ambos os lotes levaram cerca de 175 segundos para serem concluídos.
Então, por que você prefere um método sobre o outro? Quando um deles realmente mexe com as estimativas de cardinalidade .
Como uma cartilha rápida, vamos comparar esses dois valores:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped (Observe que os valores reais representados aqui serão alterados, dependendo de quando você estiver lendo este post – "hoje" mencionado no comentário é 5 de setembro de 2013, o dia em que este post foi escrito. Em outubro de 2013, por exemplo, a saída será ser
2013-10-01 e 1786-04-01 .) Com isso fora do caminho, deixe-me mostrar o que quero dizer…
Uma reprodução
Vamos criar uma tabela muito simples, com apenas um cluster
DATE coluna e carregue 15.000 linhas com o valor 1786-05-01 e 50 linhas com o valor 2013-09-01 :CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
E então vamos ver os planos reais para essas duas consultas:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
Os planos gráficos parecem corretos:
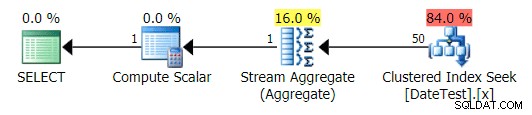
Plano gráfico para DATEDIFF(MONTH, 0, GETDATE()) consulta
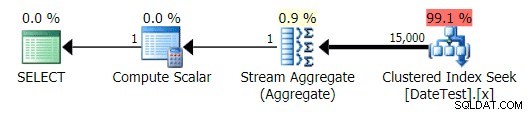
Plano gráfico para DATEDIFF(MONTH, GETDATE(), 0) consulta
Mas os custos estimados estão fora de controle – observe o quanto os custos estimados são maiores para a primeira consulta, que retorna apenas 50 linhas, em comparação com a segunda consulta, que retorna 15.000 linhas!

Grade de extrato mostrando os custos estimados
E a guia Top Operations mostra que a primeira consulta (procurando por
2013-09-01 ) estimou que encontraria 15.000 linhas, quando na verdade encontrou apenas 50; a segunda consulta mostra o contrário:esperava encontrar 50 linhas correspondentes a 1786-05-01 , mas encontrou 15.000. Com base em estimativas de cardinalidade incorretas como essa, tenho certeza de que você pode imaginar que tipo de efeito drástico isso poderia ter em consultas mais complexas em conjuntos de dados muito maiores. 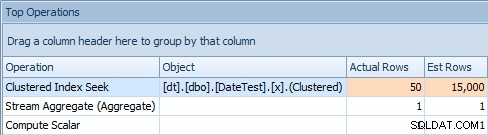
Aba superior de operações para a primeira consulta [DATEDIFF(MONTH, 0, GETDATA())]
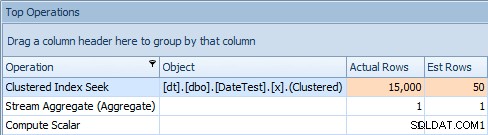
Aba superior de operações para segunda consulta [DATEDIFF(MONTH, 0, GETDATA())]
Uma variação um pouco diferente da consulta, usando uma expressão diferente para calcular o início do mês (aludida no início do post), não apresenta esse sintoma:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
O plano é muito semelhante à consulta 1 acima e, se você não olhasse mais de perto, pensaria que esses planos são equivalentes:
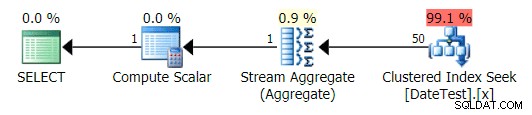
Plano gráfico para consulta não DATEDIFF
Quando você olha para a guia Top Operations aqui, no entanto, você vê que a estimativa é boa:
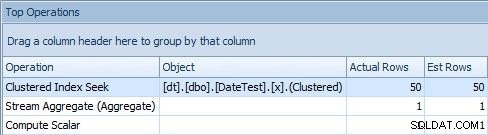
Guia Operações principais mostrando estimativas precisas
Nesse tamanho de dados e consulta específicos, o impacto líquido no desempenho (principalmente duração e leituras) é amplamente irrelevante. E é importante notar que as próprias consultas ainda retornam dados corretos; é só que as estimativas estão erradas (e podem levar a um plano pior do que o que demonstrei aqui). Dito isso, se você estiver derivando constantes usando DATEDIFF dentro de suas consultas dessa forma, você realmente deve testar esse impacto em seu ambiente.
Então, por que isso acontece?
Simplificando, o SQL Server tem um
DATEDIFF bug onde ele troca o segundo e terceiro argumentos ao avaliar a expressão para estimativa de cardinalidade. Isso parece envolver dobras constantes, pelo menos perifericamente; há muito mais detalhes sobre dobras constantes neste artigo dos Manuais Online, mas, infelizmente, o artigo não revela nenhuma informação sobre esse bug específico. Há uma correção – ou há?
Há um artigo da base de conhecimento (KB #2481274) que afirma resolver o problema, mas tem alguns problemas próprios:
- O artigo da KB afirma que o problema foi corrigido em vários service packs ou atualizações cumulativas para SQL Server 2005, 2008 e 2008 R2. No entanto, o sintoma ainda está presente em ramificações que não são mencionadas explicitamente, mesmo que tenham visto muitas CUs adicionais desde que o artigo foi publicado. Ainda posso reproduzir esse problema no SQL Server 2008 SP3 CU #8 (10.0.5828) e no SQL Server 2012 SP1 CU #5 (11.0.3373).
- Ele esquece de mencionar que, para se beneficiar da correção, você precisa ativar o sinalizador de rastreamento 4199 (e "se beneficiar" de todas as outras maneiras pelas quais o sinalizador de rastreamento específico pode afetar o otimizador). O fato de esse sinalizador de rastreamento ser necessário para a correção é mencionado em um item relacionado do Connect, #630583, mas essas informações não chegaram ao artigo da base de conhecimento. Nem o artigo da base de conhecimento nem o item Connect fornecem informações sobre a causa (que os argumentos para
DATEDIFFforam trocados durante a avaliação). No lado positivo, executando as consultas acima com o sinalizador de rastreamento ativado (usandoOPTION (QUERYTRACEON 4199)) gera planos que não apresentam o problema de estimativa incorreta.
- Sugere que você use SQL dinâmico para solucionar o problema. Nos meus testes, usando uma expressão diferente (como a acima que não usa
DATEDIFF) superou o problema nas compilações modernas do SQL Server 2008 e do SQL Server 2012. Recomendar SQL dinâmico aqui é desnecessariamente complexo e provavelmente um exagero, já que uma expressão diferente poderia resolver o problema. Mas se você usasse SQL dinâmico, eu faria dessa maneira, em vez da maneira que eles recomendam no artigo da KB, o mais importante para minimizar os riscos de injeção de SQL:
DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;
(E você pode adicionarOPTION (RECOMPILE)lá, dependendo de como você deseja que o SQL Server lide com a detecção de parâmetros.)
Isso leva ao mesmo plano da consulta anterior que não usaDATEDIFF, com estimativas adequadas e busca de 99,1% do custo no índice clusterizado.
Outra abordagem que pode tentá-lo (e por você, quero dizer eu, quando comecei a investigar) é usar uma variável para calcular o valor de antemão:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
O problema com essa abordagem é que, com uma variável, você terminará com um plano estável, mas a cardinalidade será baseada em um palpite (e o tipo de palpite dependerá da presença ou ausência de estatísticas) . Nesse caso, aqui estão os valores estimados versus reais:
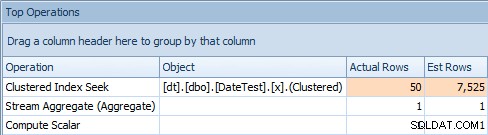
Aba de operações principais para consulta que usa uma variável
Isso claramente não está certo; parece que o SQL Server adivinhou que a variável corresponderia a 50% das linhas na tabela.
SQL Server 2014
Encontrei um problema um pouco diferente no SQL Server 2014. As duas primeiras consultas são corrigidas (por alterações no estimador de cardinalidade ou outras correções), o que significa que o
DATEDIFF argumentos não são mais trocados. Yay! No entanto, uma regressão parece ter sido introduzida na solução alternativa de usar uma expressão diferente - agora ela sofre de uma estimativa imprecisa (com base na mesma estimativa de 50% que usa uma variável). Estas são as consultas que fiz:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Aqui está a grade de declaração comparando os custos estimados e as métricas reais de tempo de execução:
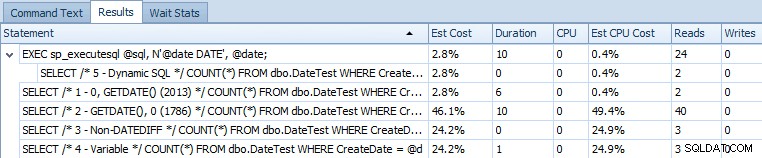
Custos estimados para as 5 consultas de amostra no SQL Server 2014
E estas são as contagens de linhas estimadas e reais (montadas usando o Photoshop):

Contagens de linhas estimadas e reais para as 5 consultas no SQL Server 2014
Fica claro a partir dessa saída que a expressão que anteriormente resolvia o problema agora introduziu uma expressão diferente. Não tenho certeza se isso é um sintoma de execução em um CTP (por exemplo, algo que será corrigido) ou se isso realmente é uma regressão.
Nesse caso, o sinalizador de rastreamento 4199 (por conta própria) não tem efeito; o novo estimador de cardinalidade está fazendo suposições e simplesmente não está correto. Se isso leva a um problema real de desempenho, depende muito de muitos outros fatores além do escopo deste post.
Se você se deparar com esse problema, você pode – pelo menos nos CTPs atuais – restaurar o comportamento antigo usando
OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . O sinalizador de rastreamento 9481 desativa o novo estimador de cardinalidade, conforme descrito nestas notas de versão (que certamente desaparecerá ou pelo menos se moverá em algum momento). Isso, por sua vez, restaura as estimativas corretas para o não-DATEDIFF versão da consulta, mas infelizmente ainda não resolve o problema em que uma suposição é feita com base em uma variável (e usar TF9481 sozinho, sem TF4199, força as duas primeiras consultas a regredir ao antigo comportamento de troca de argumento). Conclusão
Confesso que foi uma grande surpresa para mim. Parabéns a Martin Smith e t-clausen.dk por perseverarem e me convencerem de que este era um problema real e não imaginado. Também um grande obrigado a Paul White (@SQL_Kiwi) que me ajudou a manter minha sanidade e me lembrou das coisas que eu não deveria dizer. :-)
Desconhecendo esse bug, eu estava convencido de que o melhor plano de consulta foi gerado simplesmente alterando o texto da consulta, não devido à alteração específica. Acontece que, às vezes, uma alteração em uma consulta que você supõe não fará diferença, na verdade fará. Portanto, recomendo que, se você tiver padrões de consulta semelhantes em seu ambiente, teste-os e certifique-se de que as estimativas de cardinalidade estejam corretas. E anote para testá-los novamente quando você atualizar.