Predicados únicos
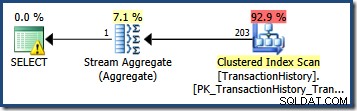
Estimar o número de linhas qualificadas por um único predicado de consulta geralmente é simples. Quando um predicado faz uma comparação simples entre uma coluna e um valor escalar, as chances são boas de que o estimador de cardinalidade será capaz de derivar uma estimativa de boa qualidade a partir do histograma estatístico. Por exemplo, a seguinte consulta do AdventureWorks produz uma estimativa exatamente correta de 203 linhas (supondo que nenhuma alteração tenha sido feita nos dados desde que as estatísticas foram criadas):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
Observando o histograma de estatísticas para o
TransactionDate coluna, fica claro de onde veio essa estimativa:DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM; 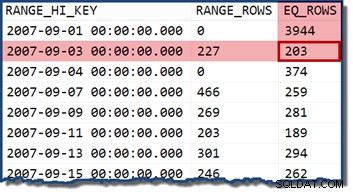
Se alterarmos a consulta para especificar uma data que caia em um intervalo de histograma, o estimador de cardinalidade assume que os valores são distribuídos uniformemente. Usando uma data de
2007-09-02 produz uma estimativa de 227 linhas (do RANGE_ROWS entrada). Como uma observação interessante, a estimativa permanece em 227 linhas, independentemente de qualquer porção de tempo que possamos adicionar ao valor de data (o TransactionDate coluna é um datetime tipo de dados). Se tentarmos a consulta novamente com uma data de
2007-09-05 ou 2007-09-06 (ambos estão entre o 2007-09-04 e 2007-09-07 etapas do histograma), o estimador de cardinalidade assume os 466 RANGE_ROWS são divididos igualmente entre os dois valores, estimando 233 linhas em ambos os casos. Existem muitos outros detalhes para a estimativa de cardinalidade para predicados simples, mas o anterior servirá como uma atualização para nossos propósitos atuais.
Os problemas de vários predicados
Quando uma consulta contém mais de um predicado de coluna, a estimativa de cardinalidade se torna mais difícil. Considere a seguinte consulta com dois predicados simples (cada um dos quais é fácil de estimar sozinho):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; Os intervalos específicos de valores na consulta são escolhidos deliberadamente para que ambos os predicados identifiquem exatamente as mesmas linhas. Poderíamos facilmente modificar os valores da consulta para resultar em qualquer quantidade de sobreposição, incluindo nenhuma sobreposição. Imagine agora que você é o estimador de cardinalidade:como você derivaria uma estimativa de cardinalidade para esta consulta?
O problema é mais difícil do que pode parecer à primeira vista. Por padrão, o SQL Server cria automaticamente estatísticas de coluna única em ambas as colunas de predicado. Também podemos criar estatísticas de várias colunas manualmente. Isso nos dá informações suficientes para produzir uma boa estimativa para esses valores específicos? E quanto ao caso mais geral em que pode haver qualquer grau de sobreposição?
Usando os dois objetos estatísticos de coluna única, podemos facilmente derivar uma estimativa para cada predicado usando o método de histograma descrito na seção anterior. Para os valores específicos na consulta acima, os histogramas mostram que o
TransactionID espera-se que o intervalo corresponda a 68412,4 linhas e o TransactionDate espera-se que o intervalo corresponda a 68.413 linhas. (Se os histogramas fossem perfeitos, esses dois números seriam exatamente os mesmos.) O que os histogramas não podem diga-nos quantas desses dois conjuntos de linhas serão as mesmas linhas . Tudo o que podemos dizer com base nas informações do histograma é que nossa estimativa deve estar em algum lugar entre zero (para nenhuma sobreposição) e 68.412,4 linhas (sobreposição completa).
A criação de estatísticas de várias colunas não fornece assistência para essa consulta (ou para consultas de intervalo em geral). As estatísticas de várias colunas ainda criam apenas um histograma sobre a primeira coluna nomeada, duplicando essencialmente o histograma associado a uma das estatísticas criadas automaticamente. A densidade adicional as informações fornecidas pela estatística de várias colunas podem ser úteis para fornecer informações de caso médio para consultas que contêm vários predicados de igualdade, mas não nos ajudam aqui.
Para produzir uma estimativa com alto grau de confiança, precisaríamos que o SQL Server fornecesse melhores informações sobre a distribuição de dados – algo como um multidimensional histograma de estatísticas. Até onde sei, nenhum mecanismo de banco de dados comercial oferece atualmente uma facilidade como essa, embora vários artigos técnicos tenham sido publicados sobre o assunto (incluindo um da Microsoft Research que usou um desenvolvimento interno do SQL Server 2000).
Sem saber nada sobre correlações e sobreposições de dados para intervalos de valores específicos, não fica claro como devemos proceder para produzir uma boa estimativa para nossa consulta. Então, o que o SQL Server faz aqui?
SQL Server 7 – 2012
O estimador de cardinalidade nessas versões do SQL Server geralmente pressupõe que os valores de diferentes atributos em uma tabela são distribuídos de forma totalmente independente uns dos outros. Esta suposição de independência raramente é um reflexo preciso dos dados reais, mas tem a vantagem de fazer cálculos mais simples.
E Seletividade
Usando a suposição de independência, dois predicados conectados por
AND (conhecida como conjunção ) com seletividades S1 e S2 , resultam em uma seletividade combinada de:(S1 * S2) Caso o termo não seja familiar para você, seletividade é um número entre 0 e 1, representando a fração de linhas na tabela que passam o predicado. Por exemplo, se um predicado seleciona 12 linhas de uma tabela de 100 linhas, a seletividade é (12/100) =0,12.
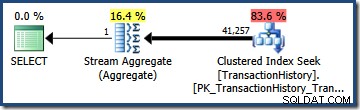
Em nosso exemplo, o
TransactionHistory tabela contém 113.443 linhas no total. O predicado em TransactionID é estimado (a partir do histograma) para qualificar 68.412,4 linhas, então a seletividade é (68.412,4 / 113.443) ou aproximadamente 0,603055 . O predicado em TransactionDate estima-se que tenha uma seletividade de (68.413 / 113.443) =aproximadamente 0,603061 . A multiplicação das duas seletividades (usando a fórmula acima) fornece uma estimativa de seletividade combinada de 0,363679 . Multiplicando essa seletividade pela cardinalidade da tabela (113.443) dá a estimativa final de 41.256,8 linhas:
OU Seletividade
Dois predicados conectados por
OR (uma disjunção ) com seletividades S1 e S2 , resulta em uma seletividade combinada de:(S1 + S2) – (S1 * S2) A intuição por trás da fórmula é somar as duas seletividades, então subtrair a estimativa para sua conjunção (usando a fórmula anterior). Claramente poderíamos ter dois predicados, cada um com seletividade de 0,8, mas simplesmente adicioná-los produziria uma seletividade combinada impossível de 1,6. Apesar da suposição de independência, devemos reconhecer que os dois predicados podem ter uma sobreposição, portanto, para evitar dupla contagem, a seletividade estimada da conjunção é subtraída.
Podemos modificar facilmente nosso exemplo em execução para usar
OR :SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313'; Substituindo as seletividades de predicado no
OR fórmula fornece uma seletividade combinada de:(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437 Multiplicado pelo número de linhas na tabela, essa seletividade nos dá a estimativa final de cardinalidade de 95.568,6 :
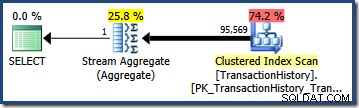
Nenhuma estimativa (41.257 para o
AND inquerir; 95.569 para o OR query) é particularmente bom porque ambos são baseados em uma suposição de modelagem que não corresponde muito bem à distribuição de dados. Ambas as consultas retornam 68.413 linhas (porque os predicados identificam exatamente as mesmas linhas). Sinalizador de rastreamento 4137 - Seletividade mínima
Para SQL Server 2008 (R1) a 2012 inclusive, a Microsoft lançou uma correção que altera a forma como a seletividade é calculada para o
AND caso (predicados conjuntivos) apenas. O artigo da Base de Conhecimento nesse link não contém muitos detalhes, mas a correção altera a fórmula de seletividade usada. Em vez de multiplicar as seletividades individuais, a estimativa de cardinalidade para predicados conjuntivos agora usa apenas a seletividade mais baixa. Para ativar o comportamento alterado, é necessário o sinalizador de rastreamento suportado 4137. Um artigo separado da Base de Conhecimento documenta que esse sinalizador de rastreamento também é suportado para uso por consulta por meio do
QUERYTRACEON dica:SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); Com esse sinalizador ativo, a estimativa de cardinalidade usa a seletividade mínima dos dois predicados, resultando em uma estimativa de 68.412,4 linhas:
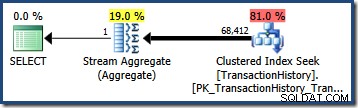
Isso é quase perfeito para nossa consulta porque nossos predicados de teste são exatamente correlacionados (e as estimativas derivadas dos histogramas básicos também são muito boas).
É razoavelmente raro que predicados sejam perfeitamente correlacionados assim com dados reais, mas o sinalizador de rastreamento pode ajudar em alguns casos. Observe que o comportamento de seletividade mínima será aplicado a todos os conjuntos conjuntivos (
AND ) predicados na consulta; não há como especificar o comportamento em um nível mais granular. Não há sinalizador de rastreamento correspondente para estimar disjuntivo (
OR ) predicados usando seletividade mínima. SQL Server 2014
A computação de seletividade no SQL Server 2014 se comporta da mesma forma que as versões anteriores (e o sinalizador de rastreamento 4137 funciona como antes) se o nível de compatibilidade do banco de dados for definido como inferior a 120 ou se o sinalizador de rastreamento 9481 está ativo. Definir o nível de compatibilidade do banco de dados é o oficial maneira de usar o estimador de cardinalidade pré-2014 no SQL Server 2014. O sinalizador de rastreamento 9481 é eficaz para fazer a mesma coisa que no momento da gravação e também funciona com
QUERYTRACEON , embora não esteja documentado para fazê-lo. Não há como saber qual será o comportamento RTM desse sinalizador. Se o novo estimador de cardinalidade estiver ativo, o SQL Server 2014 usará uma fórmula padrão diferente para combinar predicados conjuntivos e disjuntivos. Embora não documentada, a fórmula de seletividade para conjunções foi descoberta e documentada várias vezes agora. A primeira que me lembro de ter visto está neste post em português e a segunda parte publicada algumas semanas depois. Para resumir, a abordagem de 2014 para predicados conjuntivos é usar recuo exponencial: dada uma tabela com cardinalidade C e seletividades de predicado S1 , S2 , S3 … Sn , onde S1 é o mais seletivo e Sn pelo menos:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) … A estimativa é calculada o predicado mais seletivo multiplicado pela cardinalidade da tabela, multiplicado pela raiz quadrada do próximo predicado mais seletivo, e assim por diante com cada nova seletividade ganhando uma raiz quadrada adicional.
Lembrando que a seletividade é um número entre 0 e 1, fica claro que aplicar uma raiz quadrada aproxima o número de 1. O efeito é levar em conta todos os predicados na estimativa final, mas reduzir o impacto dos predicados menos seletivos exponencialmente. Há indiscutivelmente mais lógica nessa ideia do que sob a suposição de independência , mas ainda é uma fórmula fixa – ela não muda com base no grau real de correlação de dados.
O estimador de cardinalidade de 2014 usa uma fórmula de recuo exponencial para ambos predicados conjuntivos e disjuntivos, embora a fórmula usada no disjuntivo (
OR ) ainda não foi documentado (oficialmente ou não). Sinalizadores de rastreamento de seletividade do SQL Server 2014
Sinalizador de rastreamento 4137 (para usar seletividade mínima) não funcionam no SQL Server 2014, se o novo estimador de cardinalidade for usado ao compilar uma consulta. Em vez disso, há um novo sinalizador de rastreamento 9471 . Quando este sinalizador está ativo, a seletividade mínima é usada para estimar múltiplas conjuntivas e disjuntivas predicados. Esta é uma mudança do comportamento 4137, que afetava apenas predicados conjuntivos.
Da mesma forma, o sinalizador de rastreamento 9472 pode ser especificado para assumir independência para vários predicados, como faziam as versões anteriores. Este sinalizador é diferente de 9481 (para usar o estimador de cardinalidade anterior a 2014) porque sob 9472 o novo estimador de cardinalidade ainda será usado, apenas a fórmula de seletividade para predicados múltiplos é afetada.
Nem 9471 nem 9472 estão documentados no momento da escrita (embora possam estar em RTM).
Uma maneira conveniente de ver qual suposição de seletividade está sendo usada no SQL Server 2014 (com o novo estimador de cardinalidade ativo) é examinar a saída de depuração da computação de seletividade produzida quando os sinalizadores de rastreamento 2363 e 3604 estão ativos. A seção a ser procurada está relacionada à calculadora de seletividade que combina filtros, onde você verá um dos seguintes, dependendo de qual suposição está sendo usada:
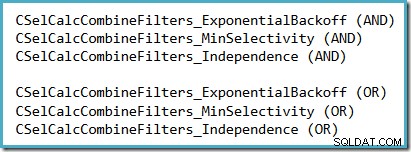
Não há perspectiva realista de que 2363 será documentado ou suportado.
Considerações finais
Não há nada de mágico na retirada exponencial, na seletividade mínima ou na independência. Cada abordagem representa uma suposição (extremamente) simplificadora que pode ou não produzir estimativas aceitáveis para qualquer consulta específica ou distribuição de dados.
Em alguns aspectos, recuo exponencial representa um compromisso entre os dois extremos da independência e seletividade mínima . Mesmo assim, é importante não ter expectativas irracionais sobre isso. Até que uma maneira mais precisa seja encontrada para estimar a seletividade para vários predicados (com características de desempenho razoáveis), continua sendo importante estar ciente das limitações do modelo e observar os erros de estimativa (potenciais) de acordo.
Os vários sinalizadores de rastreamento fornecem algum controle sobre qual suposição é usada, mas a situação está longe de ser perfeita. Por um lado, a granularidade mais fina na qual um sinalizador pode ser aplicado é uma única consulta – o comportamento de estimativa não pode ser especificado no nível de predicado. Se você tiver uma consulta em que alguns predicados são correlacionados e outros independentes, os sinalizadores de rastreamento podem não ajudar muito sem refatorar a consulta de uma forma ou de outra. Da mesma forma, uma consulta problemática pode ter correlações de predicado que não são bem modeladas por nenhuma das opções disponíveis.
O uso ad hoc dos sinalizadores de rastreamento requer as mesmas permissões que
DBCC TRACEON – ou seja, sysadmin . Isso provavelmente é bom para testes pessoais, mas para produção, use um guia de plano usando o QUERYTRACEON dica é uma opção melhor. Com um guia de plano, não são necessárias permissões adicionais para executar a consulta (embora sejam necessárias permissões elevadas para criar o guia de plano, é claro).