O design do banco de dados é um dos fatores mais importantes que contribuem para o desempenho de um aplicativo. Consequentemente, quão bem o banco de dados é projetado é de extrema importância. O design do banco de dados trata da organização eficiente de dados com base nos fluxos de trabalho do produto, roteiro futuro e padrões de uso esperados.
A saída de um exercício de design de banco de dados é um modelo de dados. Um modelo de dados representa todos os objetos, entidades, atributos, relacionamentos e restrições no sistema. De um modo geral, os modelos de dados podem ser de dois tipos:lógico ou físico . A representação do modelo de dados é feita através da criação de um diagrama ER, também conhecido como diagrama entidade-relacionamento, diagrama ERD ou diagrama de banco de dados.
O modelo de dados físico está relacionado aos detalhes de implementação reais no banco de dados. O modelo de dados lógico, por outro lado, abstrai os aspectos técnicos de implementação. Isso torna o modelo de dados lógico consumível para o negócio. Uma diferença importante entre os dois modelos é que o modelo lógico é independente do banco de dados, enquanto o modelo físico precisa ser específico para o banco de dados em uso.
O design adequado do banco de dados geralmente é subestimado e negligenciado durante o desenvolvimento do aplicativo. O custo dessa negligência é percebido geralmente muito mais tarde, quando novos recursos do aplicativo chegam ou quando recursos antigos precisam ser alterados. É quando o design do banco de dados deixa de fazer sentido. Embora não seja possível preparar o design de um banco de dados para o futuro, é muito possível fazer um esforço para entender melhor os casos de uso de negócios e projetar o banco de dados de acordo. Leia mais sobre dicas sobre um melhor design de banco de dados aqui.
Com isso em mente, vamos seguir as etapas do design de banco de dados.
Etapa 1:reunir os requisitos de negócios
O primeiro passo é conversar com a empresa sobre suas necessidades. Se a conversa for eficaz, deve resultar em informações suficientes para começar a trabalhar em um modelo de dados conceitual, que é uma abstração do modelo lógico. Falar com a empresa, antes de tudo, fornece uma visão completa dos processos de negócios, que, por sua vez, fornecem informações sobre os vários pontos de dados que são importantes para a empresa capturar e rastrear. Por exemplo, em um modelo de reserva de táxi, vale a pena fazer as seguintes perguntas:
- A empresa deseja os dados de rastreamento do veículo no banco de dados, independentemente de haver uma viagem ativa ou não? Se sim, o campo
vehicle_trip_idna tabelavehicle_tripsseria anulável . Caso contrário, não será anulável . - A empresa deseja o histórico de alterações em
trip_statusarmazenados no banco de dados? Se sim, sempre que otrip_statusalterações, haverá outro registro nastripstabela. Caso contrário, sempre que otrip_statusalterações,trip_statusserá atualizado no local.
Conforme mostrado neste exemplo, com base nas entradas do negócio, você acabaria escolhendo uma opção em detrimento da outra. Isso resultaria na mudança das entidades envolvidas e seus relacionamentos.
A coleta de requisitos também geralmente envolve iniciar uma conversa sobre segurança de dados, como quais dados devem ser mascarados e criptografados. O exercício de coleta de requisitos resulta em um documento de requisitos geralmente apoiado por um rascunho de trabalho do modelo de dados conceitual.
Etapa 2:entenda o roteiro de negócios
As empresas mudam seus processos o tempo todo; sua capacidade de adaptação os torna menos propensos a falhar. Alterar processos de negócios significa alterar fluxos de trabalho e modelos de dados. Embora não seja possível conhecer essas mudanças com antecedência, certamente é possível estar em dia com o roadmap de negócios.
Por exemplo, se uma empresa tem planos para atingir uma nova região geográfica, o modelo deve atender ao suporte a idiomas, moedas, fusos horários e assim por diante. Os benefícios de entender o roteiro de negócios de longo prazo geralmente aparecem em uma transição mais suave para novos processos de negócios.
Deixe-me compartilhar mais um exemplo, que é mais sobre prioridades de negócios em constante evolução. O negócio de táxi foi fortemente impactado no início do COVID-19. Como empresa de táxi, você deseja agir preventivamente para garantir às pessoas que está fazendo tudo para garantir que sua viagem no táxi seja a mais segura possível, que o veículo seja desinfetado todos os dias, que o motorista use máscara vezes, e que há desinfetante para as mãos disponível na cabine. Agora, para capturar todas essas informações, altere duas entidades,
drivers e vehicles , seria necessário. Vários campos de sinalização booleana precisam ser adicionados a essas entidades para atender a esse caso de uso de negócios. Etapa 3:identificar entidades e atributos
Uma vez que os requisitos de negócios são coletados, as informações podem ser usadas para identificar entidades juntamente com o conjunto essencial de atributos. Uma ou mais entidades geralmente são mapeadas diretamente para processos de negócios e o relacionamento entre essas entidades também imita o fluxo de trabalho do processo de negócios.
Esta etapa também é utilizada para identificar quais atributos atuarão como identificadores nas entidades. Os identificadores são convertidos em chaves primárias no modelo físico. Além disso, também é comum especificar tipos de dados para todos os atributos nesta etapa.
Por exemplo, no modelo de reserva de táxi, você teria que identificar os atributos que funcionariam como campos obrigatórios para o cadastro de usuários e motoristas do aplicativo de reservas. O registro do usuário seria feito usando
user_phone e o registro do driver seria feito usando driver_phone . Da mesma forma, outras entidades e atributos são identificados durante esta etapa, após terem sido mapeados para os fluxos de trabalho do processo de negócios.
Etapa 4:identificar relacionamentos
Após identificar as entidades e seus atributos, a próxima etapa é definir os relacionamentos entre as entidades com base nos fluxos de trabalho de negócios que foram documentados na fase de levantamento de requisitos. Além de estabelecer que há um relacionamento entre duas entidades, também é importante identificar qual dos quatro tipos de relacionamento a seguir existe entre elas. Considere duas entidades arbitrárias, A e B:
- Um para um → Um registro em A corresponde a no máximo um registro em B.
- Um para muitos → Um registro em A corresponde a muitos registros em B.
- Muitos para um → Muitos registros em A correspondem a no máximo um registro em B.
- Muitos para muitos → Muitos registros em A correspondem a muitos registros em B.
No modelo de reserva de táxi, foi utilizado apenas um tipo de relacionamento, ou seja, um para muitos. Pegue o relacionamento entre
users e trips como um exemplo. No modelo, há uma suposição de que apenas um usuário pode estar relacionado a uma viagem, o que implica que não há táxis compartilhados ou agrupados. Mas se houvesse táxis compartilhados ou agrupados, possivelmente haveria um relacionamento de muitos para muitos entre users e trips , se muitos usuários compartilharem o mesmo trip_id . Etapa 5:criar um diagrama ER lógico
Com entidades, atributos e relacionamentos de entidade definidos, o próximo passo imediato é desenhar o diagrama ER. Todos os passos listados acima podem ser feitos dentro do Vertabelo. Não há regras rígidas e rápidas para a forma como a modelagem lógica deve ser feita, com a possível exceção da notação de referência.
Por exemplo, dê uma olhada no exemplo a seguir de um diagrama ER lógico. Ele captura um fluxo de trabalho de negócios simples de uma empresa de táxi, onde um usuário pode reservar um passeio com a capacidade de rastrear o veículo.
Etapa 6:validar o diagrama ER lógico
A modelagem lógica é um processo no qual muitas informações de negócios precisam ser traduzidas em um design de banco de dados. Sem verificações completas, esta fase de desenvolvimento de banco de dados é propensa a erros que podem ser bastante caros em um estágio posterior.
Para cuidar disso, a Vertabelo possui uma lista completa de verificações que podem ser realizadas em um modelo lógico. As verificações podem ser realizadas em todas as granularidades, desde o modelo como um todo até atributos individuais e tudo mais. Algumas das verificações simples são:
- Nomes de entidades, atributos, relacionamentos etc. não podem ser nulos e precisam ser exclusivos.
- Uma entidade deve ter pelo menos 1 atributo.
- Identificadores (PKs) devem ser definidos para cada entidade.
- O modelo deve usar um dos tipos de dados listados para atributos.
Todas essas verificações são opcionais e podem ser configuradas para serem ignoradas, se houver outra estrutura de validação em vigor. A validação adequada da Vertabelo ajuda você a passar para a próxima etapa com o mínimo de atrito possível.
Etapa 7:crie um diagrama ER físico
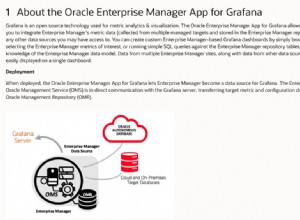
Depois que o diagrama ER lógico é criado, a próxima etapa é criar um modelo de dados físico. O modelo de dados físico será específico para o banco de dados no qual você deseja implantar o modelo de dados. Todos os bancos de dados têm sua implementação exclusiva de regras de nomenclatura, tipos de dados e restrições. Devido a isso, a linguagem de definição de dados (DDL) geralmente difere de um banco de dados para outro.
Para criar um modelo de dados físico, siga estas etapas:
- Encontre o tipo de dados mais próximo no banco de dados de destino para substituir o tipo de dados genérico selecionado no modelo de dados lógico.
- Siga as regras de nomenclatura para tabelas, colunas e restrições conforme prescrito pelo banco de dados de destino.
- Modifique o modelo para alinhá-lo aos fluxos de trabalho de consulta predefinidos. Isso geralmente resulta no aumento da redundância para salvar junções.
- Finalmente, você pode criar índices, partições, chaves de distribuição e chaves de classificação. É quando você pode criar quaisquer modificações para melhorar o desempenho do modelo.
Essas etapas podem ser executadas usando qualquer ferramenta de modelagem de dados que você possa usar para criar um modelo de dados do zero. No entanto, a Vertabelo tem a opção de converter um modelo de dados lógico em um modelo de dados físico completo para todos os principais sistemas de banco de dados, como MySQL, PostgreSQL, Oracle, Microsoft SQL Server, Amazon Redshift, Google BigQuery e muito mais. Depois que o modelo de dados lógico é convertido em um modelo de dados físico, você pode continuar com as quatro etapas que discutimos.
O Vertabelo também tem a opção de adicionar scripts de pré e pós-implantação no nível da tabela junto com quaisquer comentários no nível muito granular do modelo. Os comentários se tornam úteis quando se utiliza o recurso de geração de documentação oferecido pela Vertabelo. O documento de banco de dados pode ser exportado em qualquer um dos três formatos a seguir:HTML, PDF ou DOCX.
Continuando com o exemplo de reserva de táxi, vamos dar uma olhada no modelo de dados físicos gerado pelo Vertabelo.
Etapa 8:validar o diagrama ER físico
Assim como o diagrama ER lógico foi validado, o Vertabelo possui uma ferramenta para validar diagramas ER físicos com várias verificações adicionais, como se existem ou não FKs e se o comprimento de um nome de tabela ou de uma coluna excede o limite baseado no banco de dados selecionado.
A validação não precisa ser executada explicitamente. Isso acontece quando o diagrama é modificado. Os problemas com o modelo se enquadram em uma das três categorias:erros, avisos e dicas, em ordem de gravidade decrescente. Há um artigo útil e bem escrito que fala sobre os erros comuns cometidos durante o processo de design de banco de dados.
Etapa 9:corrigir problemas com o diagrama ER físico
Os resultados da validação podem identificar problemas que precisam ser corrigidos. Alguns dos problemas mais comuns são:
- Chaves estrangeiras ausentes onde os relacionamentos de entidade foram definidos.
- Faltam as chaves primárias das tabelas.
- Tipos de dados não suportados para o banco de dados selecionado.
Depois que esses e outros problemas semelhantes forem resolvidos, o modelo estará pronto para ser exportado para um script SQL implementável para o sistema de gerenciamento de banco de dados selecionado.
Etapa 10:gerar os scripts DDL para implantar o modelo
O design de banco de dados não é apenas criar diagramas ER. Um exercício de modelagem de dados usando diagramas ER é bem-sucedido apenas se resultar em algo implementável. O Vertabelo tem uma opção conveniente para exportar o modelo físico para um script SQL pronto para implantação. Uma vez gerado, quaisquer pendências podem ser resolvidas diretamente no script SQL.
No entanto, não é recomendado alterar o script SQL gerado. Causa um desvio entre o modelo de dados físico e o script SQL implantado no banco de dados, o que também pode significar um desvio entre as tabelas reais e a documentação do banco de dados.
Agora que chegamos ao final do processo de design do banco de dados, vamos dar uma olhada no código SQL gerado pelo Vertabelo.
Compartilhe seus pensamentos
O projeto de banco de dados é uma atividade de alto impacto no desenvolvimento de software. O campo de design de banco de dados evoluiu ao longo dos anos com novas maneiras de representar o design para os negócios, para os engenheiros e para os analistas de dados. Isso muitas vezes resultou em novos tipos de diagramas, padrões de modelagem e notações. Grande parte da evolução foi abordada na seção de fundamentos de design.
Ficaremos felizes em ver quais foram suas experiências na criação de bancos de dados. Escreva-nos para contact@vertabelo.com.