No PASS Summit, algumas semanas atrás, a Microsoft lançou o CTP2.1 do SQL Server 2019, e um dos grandes aprimoramentos de recursos incluídos no CTP é o Scalar UDF Inlining. Antes desta versão, eu queria brincar com a diferença de desempenho entre o inlining de UDFs escalares e a execução RBAR (linha por linha agonizante) de UDFs escalares em versões anteriores do SQL Server e encontrei uma opção de sintaxe para o CRIAR FUNÇÃO declaração nos Manuais Online do SQL Server que eu nunca tinha visto antes.
O DDL para CREATE FUNCTION suporta uma cláusula WITH para opções de função e, ao ler os Manuais Online, notei que a sintaxe incluía o seguinte:
-- Transact-SQL Function Clauses
<function_option>::=
{
[ ENCRYPTION ]
| [ SCHEMABINDING ]
| [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
| [ EXECUTE_AS_Clause ]
} Eu estava realmente curioso sobre o RETURNS NULL ON NULL INPUT opção de função, então decidi fazer alguns testes. Fiquei muito surpreso ao descobrir que, na verdade, é uma forma de otimização de UDF escalar que está no produto desde pelo menos o SQL Server 2008 R2.
Acontece que, se você souber que uma UDF escalar sempre retornará um resultado NULL quando uma entrada NULL for fornecida, a UDF SEMPRE deverá ser criada com o RETURNS NULL ON NULL INPUT opção, porque o SQL Server nem mesmo executa a definição da função para nenhuma linha em que a entrada é NULL - causando um curto-circuito e evitando a execução desperdiçada do corpo da função.
Para mostrar esse comportamento, usarei uma instância do SQL Server 2017 com a atualização cumulativa mais recente aplicada a ela e o AdventureWorks2017 banco de dados do GitHub (você pode baixá-lo aqui) que vem com um
dbo.ufnLeadingZeros função que simplesmente adiciona zeros à esquerda ao valor de entrada e retorna uma cadeia de oito caracteres que inclui esses zeros à esquerda. Vou criar uma nova versão dessa função que inclui o RETURNS NULL ON NULL INPUT opção para que eu possa compará-la com a função original para desempenho de execução. USE [AdventureWorks2017];
GO
CREATE FUNCTION [dbo].[ufnLeadingZeros_new](
@Value int
)
RETURNS varchar(8)
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @ReturnValue varchar(8);
SET @ReturnValue = CONVERT(varchar(8), @Value);
SET @ReturnValue = REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue;
RETURN (@ReturnValue);
END;
GO Com o objetivo de testar as diferenças de desempenho de execução dentro do mecanismo de banco de dados das duas funções, decidi criar uma sessão de eventos estendidos no servidor para rastrear o sqlserver.module_end evento, que é acionado no final de cada execução da UDF escalar para cada linha. Isso me permitiu demonstrar a semântica de processamento linha por linha e também acompanhar quantas vezes a função foi realmente invocada durante o teste. Resolvi também coletar o sql_batch_completed e sql_statement_completed eventos e filtrar tudo por session_id para ter certeza de que eu estava apenas capturando informações relacionadas à sessão em que eu estava realmente executando os testes (se você quiser replicar esses resultados, precisará alterar o 74 em todos os lugares do código abaixo para qualquer ID de sessão do seu teste código será executado). A sessão do evento está usando TRACK_CAUSALITY para que seja fácil contar quantas execuções da função ocorreram através do activity_id.seq_no valor para os eventos (que aumenta em um para cada evento que satisfaça o session_id filtro).
CREATE EVENT SESSION [Session72] ON SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))) WITH (TRACK_CAUSALITY=ON) GO
Assim que iniciei a sessão do evento e abri o Live Data Viewer no Management Studio, executei duas consultas; um usando a versão original da função para preencher zeros no CurrencyRateID coluna no Sales.SalesOrderHeader tabela e a nova função para produzir a saída idêntica, mas usando o RETURNS NULL ON NULL INPUT opção e capturei as informações do Plano de Execução Real para comparação.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader; GO
A revisão dos dados do Extended Events mostrou algumas coisas interessantes. Primeiro, a função original foi executada 31.465 vezes (da contagem de module_end eventos) e o tempo total de CPU para o sql_statement_completed evento foi de 204ms com 482ms de duração.
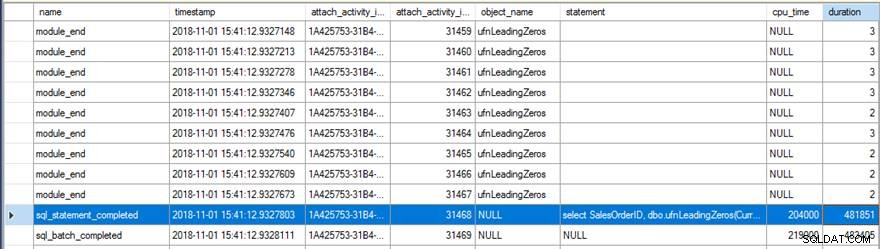
A nova versão com o RETURNS NULL ON NULL INPUT a opção especificada foi executada apenas 13.976 vezes (novamente, a partir da contagem de module_end eventos) e o tempo de CPU para o sql_statement_completed evento foi de 78ms com 359ms de duração.

Achei isso interessante para verificar as contagens de execução, executei a seguinte consulta para contar NOT NULL linhas de valor, linhas de valor NULL e linhas de total no Sales.SalesOrderHeader tabela.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT(*) FROM Sales.SalesOrderHeader;
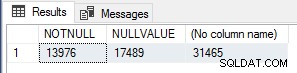
Esses números correspondem exatamente ao número de module_end eventos para cada um dos testes, então esta é definitivamente uma otimização de desempenho muito simples para UDFs escalares que deve ser usada se você souber que o resultado da função será NULL se os valores de entrada forem NULL, para curto-circuitar/desviar a execução da função inteiramente para essas linhas.
As informações de QueryTimeStats nos Planos de Execução Reais também refletiram os ganhos de desempenho:
<QueryTimeStats CpuTime="204" ElapsedTime="482" UdfCpuTime="160" UdfElapsedTime="218" /> <QueryTimeStats CpuTime="78" ElapsedTime="359" UdfCpuTime="52" UdfElapsedTime="64" />
Esta é uma redução bastante significativa apenas no tempo de CPU, o que pode ser um ponto de dor significativo para alguns sistemas.
O uso de UDFs escalares é um antipadrão de design bem conhecido para desempenho e há uma variedade de métodos para reescrever o código para evitar seu uso e impacto no desempenho. Mas se eles já estiverem em vigor e não puderem ser alterados ou removidos facilmente, basta recriar o UDF com o RETURNS NULL ON NULL INPUT A opção pode ser uma maneira muito simples de melhorar o desempenho se houver muitas entradas NULL no conjunto de dados em que a UDF é usada.