Há muitos casos de uso para gerar uma sequência de valores no SQL Server. Não estou falando de uma
IDENTITY persistente coluna (ou a nova SEQUENCE no SQL Server 2012), mas sim um conjunto transitório a ser usado apenas durante o tempo de vida de uma consulta. Ou mesmo os casos mais simples – como apenas anexar um número de linha a cada linha em um conjunto de resultados – que podem envolver a adição de um ROW_NUMBER() função para a consulta (ou, melhor ainda, na camada de apresentação, que precisa percorrer os resultados linha por linha de qualquer maneira). Estou falando de casos um pouco mais complicados. Por exemplo, você pode ter um relatório que mostra as vendas por data. Uma consulta típica pode ser:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
O problema dessa consulta é que, se não houver pedidos em um determinado dia, não haverá linha para esse dia. Isso pode levar a confusão, dados enganosos ou até cálculos incorretos (pense em médias diárias) para os consumidores dos dados.
Portanto, há a necessidade de preencher essas lacunas com as datas que não estão presentes nos dados. E às vezes as pessoas colocam seus dados em uma tabela #temp e usam um
WHILE loop ou um cursor para preencher as datas faltantes uma a uma. Não vou mostrar esse código aqui porque não quero defender seu uso, mas já o vi em todo lugar. Antes de nos aprofundarmos muito nas datas, porém, vamos primeiro falar sobre números, já que você sempre pode usar uma sequência de números para derivar uma sequência de datas.
Tabela de números
Há muito tempo defendo o armazenamento de uma "tabela de números" auxiliar em disco (e também uma tabela de calendário).
Aqui está uma maneira de gerar uma tabela de números simples com 1.000.000 de valores:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Por que MAXDOP 1? Veja a postagem do blog de Paul White e seu item Connect relacionado a metas de linha.
No entanto, muitas pessoas se opõem à abordagem da tabela auxiliar. O argumento deles:por que armazenar todos esses dados em disco (e na memória) quando eles podem gerar os dados em tempo real? Meu contador é ser realista e pensar no que você está otimizando; a computação pode ser cara, e você tem certeza de que calcular um intervalo de números em tempo real sempre será mais barato? No que diz respeito ao espaço, a tabela Numbers ocupa apenas cerca de 11 MB compactados e 17 MB não compactados. E se a tabela for referenciada com bastante frequência, ela deve estar sempre na memória, tornando o acesso rápido.
Vamos dar uma olhada em alguns exemplos e algumas das abordagens mais comuns usadas para satisfazê-los. Espero que todos possamos concordar que, mesmo com 1.000 valores, não queremos resolver esses problemas usando um loop ou um cursor.
Gerando uma sequência de 1.000 números
Começando simples, vamos gerar um conjunto de números de 1 a 1.000.
Tabela de números
Claro que com uma tabela de números esta tarefa é bem simples:
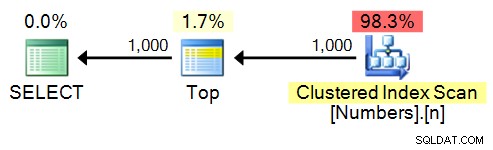
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plano:
spt_values
Esta é uma tabela que é usada por procedimentos armazenados internos para várias finalidades. Seu uso online parece ser bastante prevalente, embora não seja documentado, sem suporte, pode desaparecer um dia e porque contém apenas um conjunto de valores finito, não único e não contíguo. Existem 2.164 valores exclusivos e 2.508 valores totais no SQL Server 2008 R2; em 2012 são 2.167 únicos e 2.515 no total. Isso inclui duplicatas, valores negativos e mesmo se estiver usando
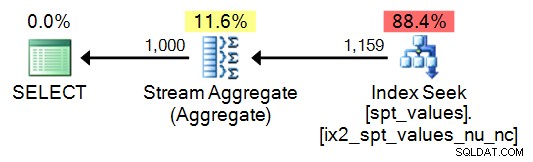
DISTINCT , muitas lacunas quando você ultrapassa o número 2.048. Portanto, a solução é usar ROW_NUMBER() para gerar uma sequência contígua, começando em 1, com base nos valores da tabela. SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Plano:

Dito isso, para apenas 1.000 valores, você pode escrever uma consulta um pouco mais simples para gerar a mesma sequência:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Isso leva a um plano mais simples, é claro, mas se desfaz rapidamente (uma vez que sua sequência precisa ter mais de 2.048 linhas):
De qualquer forma, não recomendo o uso desta tabela; Estou incluindo-o para fins de comparação, apenas porque sei o quanto disso está por aí e como pode ser tentador reutilizar o código que você encontra.
sys.all_objects
Outra abordagem que tem sido uma das minhas favoritas ao longo dos anos é usar
sys.all_objects . Como spt_values , não há uma maneira confiável de gerar uma sequência contígua diretamente e temos os mesmos problemas ao lidar com um conjunto finito (pouco menos de 2.000 linhas no SQL Server 2008 R2 e pouco mais de 2.000 linhas no SQL Server 2012), mas para 1.000 linhas podemos usar o mesmo ROW_NUMBER() truque. A razão pela qual eu gosto dessa abordagem é que (a) há menos preocupação de que essa visão desapareça em breve, (b) a própria visão é documentada e suportada e (c) ela será executada em qualquer banco de dados em qualquer versão desde o SQL Server 2005 sem precisar cruzar os limites do banco de dados (incluindo bancos de dados independentes). SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plano:

CTEs empilhados
Acredito que Itzik Ben-Gan merece o crédito final por essa abordagem; basicamente você constrói um CTE com um pequeno conjunto de valores, então você cria o produto cartesiano contra si mesmo para gerar o número de linhas que você precisa. E, novamente, em vez de tentar gerar um conjunto contíguo como parte da consulta subjacente, podemos apenas aplicar
ROW_NUMBER() ao resultado final. ;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Plano:
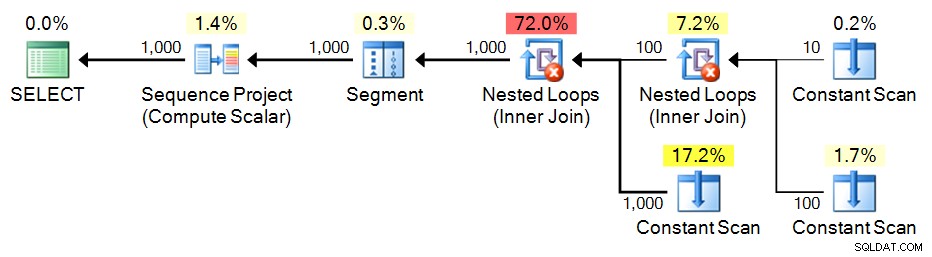
CTE recursiva
Por fim, temos um CTE recursivo, que usa 1 como âncora e adiciona 1 até atingir o máximo. Por segurança, especifico o máximo em
WHERE cláusula da parte recursiva e no MAXRECURSION contexto. Dependendo de quantos números você precisa, talvez seja necessário definir MAXRECURSION para 0 . ;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Plano:
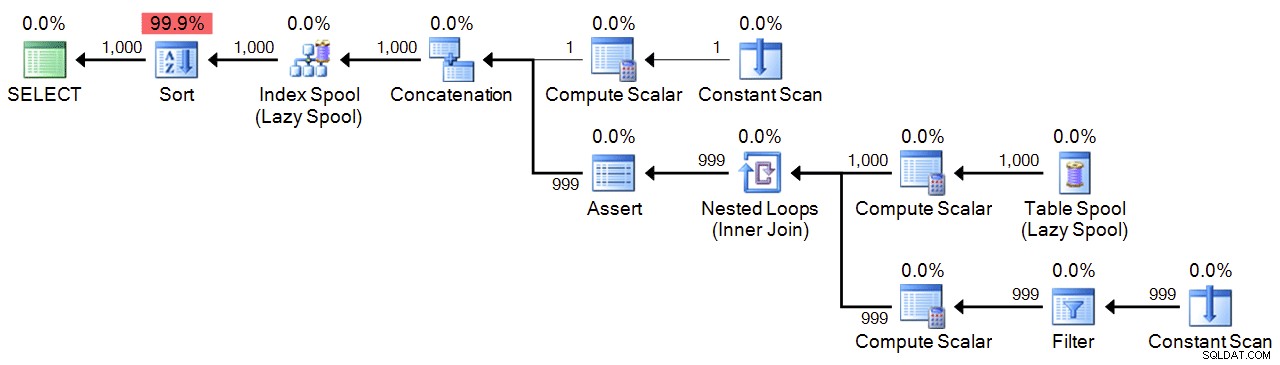
Desempenho
É claro que com 1.000 valores as diferenças de desempenho são insignificantes, mas pode ser útil ver como essas diferentes opções funcionam:
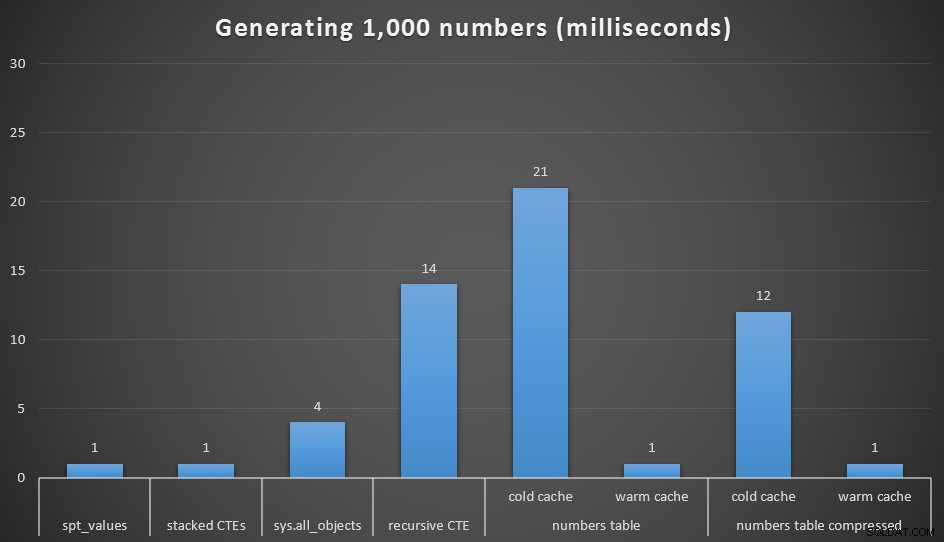
Tempo de execução, em milissegundos, para gerar 1.000 números contíguos
Executei cada consulta 20 vezes e obtive tempos de execução médios. Também testei o
dbo.Numbers table, nos formatos compactado e não compactado, e com um cache frio e um cache quente. Com um cache quente, ele rivaliza muito com as outras opções mais rápidas disponíveis (spt_values , não recomendado e CTEs empilhados), mas o primeiro hit é relativamente caro (embora eu quase ria ao chamá-lo assim). Continua…
Se este for seu caso de uso típico e você não se aventurar muito além de 1.000 linhas, espero ter mostrado as maneiras mais rápidas de gerar esses números. Se o seu caso de uso for um número maior, ou se você estiver procurando soluções para gerar sequências de datas, fique atento. Mais adiante nesta série, explorarei a geração de sequências de 50.000 e 1.000.000 números e de intervalos de datas que variam de uma semana a um ano.
[ Parte 1 | Parte 2 | Parte 3]