Spark começou a vida em 2009 como um projeto dentro do AMPLab na Universidade da Califórnia, Berkeley. Mais especificamente, nasceu da necessidade de provar o conceito de Mesos, que também foi criado no AMPLab. O Spark foi discutido pela primeira vez no white paper da Mesos intitulado Mesos:A Platform for Fine-Grained Resource Sharing in the Data Center, escrito principalmente por Benjamin Hindman e Matei Zaharia.
Surgiu como uma solução rápida e conveniente para realizar análises complexas de dados em grande escala. O Spark evoluiu como uma nova estrutura de processamento para big data que aborda muitas das deficiências do modelo MapReduce. Ele suporta análise de dados em larga escala, e os dados podem ser de diferentes fontes, como tempo real, processamento em lote em vários formatos, como imagens, textos, gráficos e muito mais. Além de seu núcleo Apache Spark, ele também fornece um conjunto útil de bibliotecas para análise de big data.
Visão geral dos componentes do Spark
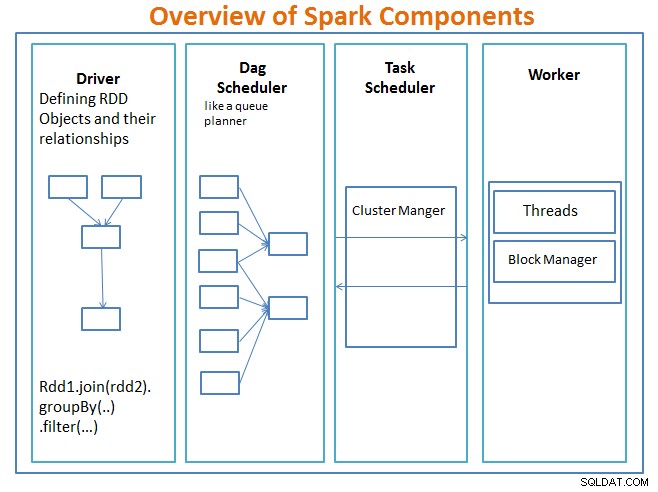
O motorista é o código que inclui a função principal e define os conjuntos de dados distribuídos resilientes (RDDs) e suas transformações. Os RDDs são as principais estruturas de dados que serão usadas em nossos programas Spark.
As operações paralelas nos RDDs são enviadas ao programador DAG , que otimizará o código e chegará a um DAG eficiente que representa as etapas de processamento de dados no aplicativo.
O DAG resultante é enviado ao gerenciador de cluster e o gerenciador de cluster tem informações sobre os trabalhadores, threads atribuídos e a localização dos blocos de dados e é responsável por atribuir tarefas de processamento específicas aos trabalhadores. Ele também lida com o retorno no caso de falha do trabalhador. O gerenciador de cluster pode ser YARN, Mesos, o gerenciador de cluster do Spark.
O trabalhador recebe unidades de trabalho e dados para gerenciar e o trabalhador executa sua tarefa específica sem conhecimento de todo o DAG e seus resultados são enviados de volta para os aplicativos de driver.
Spark, como outras ferramentas de big data, é poderoso, capaz e adequado para enfrentar uma série de desafios de dados. O Spark, como outras tecnologias de big data, não é necessariamente a melhor escolha para todas as tarefas de processamento de dados.
Na Parte 2 – discutiremos os conceitos básicos do Spark, como conjuntos de dados distribuídos resilientes, variáveis compartilhadas, SparkContext, transformações, ação , e Vantagens de usar o Spark junto com exemplos e quando usar o Spark.
Referência:
Aprenda Spark em um dia por arquiteturas de aplicativos Acodemy e Hadoop.