O destaque de ocorrências é um recurso que muitas pessoas desejam que a pesquisa de texto completo do SQL Server suporte nativamente. É aqui que você pode devolver o documento inteiro (ou um trecho) e apontar as palavras ou frases que ajudaram a combinar esse documento com a pesquisa. Fazer isso de maneira eficiente e precisa não é tarefa fácil, como descobri em primeira mão.
Como exemplo de destaque de hit:quando você faz uma pesquisa no Google ou Bing, você obtém as palavras-chave em negrito tanto no título quanto no trecho (clique em uma das imagens para ampliar):

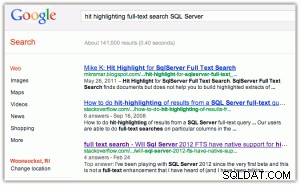
[Como um aparte, acho duas coisas divertidas aqui:(1) que o Bing favorece as propriedades da Microsoft muito mais do que o Google, e (2) que o Bing se incomoda em retornar 2,2 milhões de resultados, muitos dos quais provavelmente são irrelevantes.]
Esses trechos são comumente chamados de "snippets" ou "resumos com viés de consulta". Já solicitamos essa funcionalidade no SQL Server há algum tempo, mas ainda não recebemos nenhuma boa notícia da Microsoft:
- Conexão nº 295100 :resumos de pesquisa de texto completo (destaque de hits)
- Connect #722324:seria bom se a pesquisa de texto completo do SQL fornecesse suporte a snippets/destaques
A pergunta também aparece no Stack Overflow de tempos em tempos:
- Como fazer destaque de hits de resultados de uma consulta de texto completo do SQL Server
- O Sql Server 2012 FTS terá suporte nativo para destaque de hits?
Existem algumas soluções parciais. Esse script de Mike Kramar, por exemplo, produzirá uma extração com destaque de ocorrências, mas não aplica a mesma lógica (como separadores de palavras específicos do idioma) ao próprio documento. Ele também usa uma contagem absoluta de caracteres, para que o trecho possa começar e terminar com palavras parciais (como demonstrarei em breve). O último é bem fácil de corrigir, mas outro problema é que ele carrega todo o documento na memória, em vez de realizar qualquer tipo de streaming. Suspeito que em índices de texto completo com tamanhos de documento grandes, isso será um impacto notável no desempenho. Por enquanto, vou me concentrar em um tamanho médio de documento relativamente pequeno (35 KB).
Um exemplo simples
Então, digamos que temos uma tabela muito simples, com um índice de texto completo definido:
CREATE FULLTEXT CATALOG [FTSDemo];GO CREATE TABLE [dbo].[Document]( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL , [Title] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID));GO CREATE FULLTEXT INDEX ON [dbo].[Document]( [Content] LANGUAGE [Inglês] , [Title] LANGUAGE [English])KEY INDEX [PK_Document] ON ([FTSDemo]);
Esta tabela é preenchida com alguns documentos (especificamente, 7), como a Declaração de Independência e o discurso "Estou preparado para morrer" de Nelson Mandela. Uma pesquisa de texto completo típica nesta tabela pode ser:
SELECT d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID =t.[KEY] ORDEM POR [RANK] DESC;
O resultado retorna 4 linhas de 7:

Agora usando uma função UDF como a de Mike Kramar:
SELECT d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)FROM dbo.[Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document] ], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;
Os resultados mostram como funciona o trecho:um
<SPAN> tag é injetada na primeira palavra-chave e o trecho é esculpido com base em um deslocamento dessa posição (sem considerar o uso de palavras completas):
(Mais uma vez, isso é algo que pode ser corrigido, mas quero ter certeza de que represento adequadamente o que está por aí agora.)
Pense em destaque
Eran Meyuchas, da Interactive Thoughts, desenvolveu um componente que resolve muitos desses problemas. ThinkHighlight é implementado como um CLR Assembly com duas funções de valor escalar CLR:
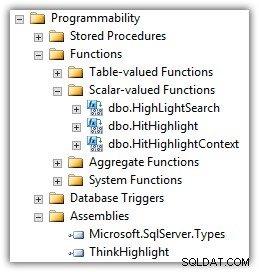
(Você também verá a UDF de Mike Kramar na lista de funções.)
Agora, sem entrar em todos os detalhes sobre como instalar e ativar o assembly em seu sistema, veja como a consulta acima seria representada com ThinkHighlight:
SELECT d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Documento] AS dINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC; Os resultados mostram como as palavras-chave mais relevantes são destacadas, e um trecho é derivado disso com base em palavras completas e um deslocamento do termo que está sendo destacado:

Algumas vantagens adicionais que não demonstrei aqui incluem a possibilidade de escolher diferentes estratégias de sumarização, controlando a apresentação de cada palavra-chave (em vez de todas) usando CSS exclusivo, bem como suporte para vários idiomas e até documentos em formato binário (a maioria dos IFilters são suportados).
Resultados de desempenho
Inicialmente, testei as métricas de tempo de execução para as três consultas usando o SQL Sentry Plan Explorer, em relação à tabela de 7 linhas. Os resultados foram:

Em seguida, eu queria ver como eles se comparariam em um tamanho de dados muito maior. Inseri a tabela em si mesma até chegar a 4.000 linhas e executei a seguinte consulta:
SET STATISTICS TIME ON;GO SELECT /* FTS */ d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT /* UDF */ d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 100)FROM dbo.[Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT / * ThinkHighlight */ d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Documento] AS dINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC;GO SET STATISTICS TIME OFF;GO
Também monitorei sys.dm_exec_memory_grants enquanto as consultas estavam em execução, para detectar quaisquer discrepâncias nas concessões de memória. Resultados com média superior a 10 execuções:
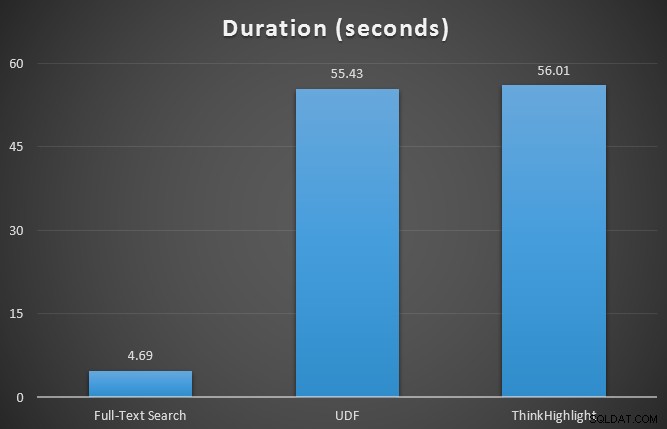
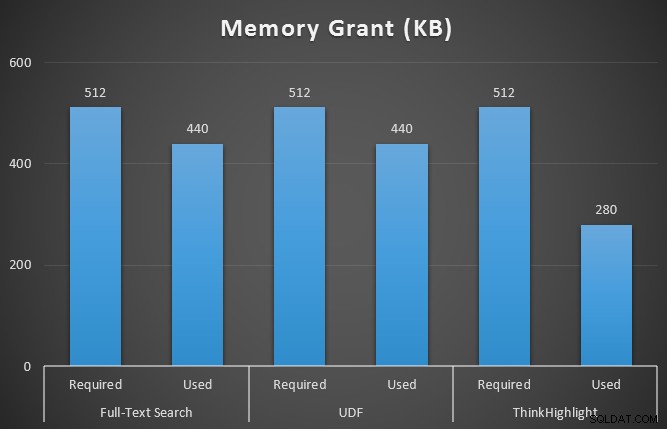
Embora ambas as opções de destaque de hit incorram em uma penalidade significativa por não destacar nada, a solução ThinkHighlight – com opções mais flexíveis – representa um custo incremental muito marginal em termos de duração (~ 1%), enquanto usa significativamente menos memória (36%) do que a variante UDF.
Conclusão
Não deve ser surpresa que o destaque de hits seja uma operação cara e, com base na complexidade do que deve ser suportado (pense em vários idiomas), que existem muito poucas soluções por aí. Acho que Mike Kramar fez um excelente trabalho produzindo uma UDF de linha de base que oferece uma boa maneira de resolver o problema, mas fiquei agradavelmente surpreso ao encontrar uma oferta comercial mais robusta – e achei muito estável, mesmo na forma beta. Eu pretendo realizar testes mais completos usando uma variedade maior de tamanhos e tipos de documentos. Enquanto isso, se o destaque de hits fizer parte dos requisitos de seu aplicativo, você deve experimentar o UDF de Mike Kramar e considerar fazer um teste com o ThinkHighlight.