Os Grupos de Disponibilidade, introduzidos no SQL Server 2012, representam uma mudança fundamental na maneira como pensamos sobre alta disponibilidade e recuperação de desastres para nossos bancos de dados. Uma das grandes coisas possíveis aqui é descarregar as operações somente leitura para uma réplica secundária, para que a instância primária de leitura/gravação não seja incomodada por coisas incômodas, como relatórios do usuário final. Configurar isso não é simples, mas é muito mais fácil e sustentável do que as soluções anteriores (levante a mão se você gostou de configurar espelhamento e instantâneos, e toda a manutenção perpétua envolvida com isso).
As pessoas ficam muito animadas quando ouvem falar dos Grupos de Disponibilidade. Então, a realidade atinge:o recurso requer a Enterprise Edition do SQL Server (a partir do SQL Server 2014, de qualquer maneira). A Enterprise Edition é cara, especialmente se você tiver muitos núcleos, e especialmente desde a eliminação do licenciamento baseado em CAL (a menos que você tenha adquirido a partir de 2008 R2, caso em que você está limitado aos primeiros 20 núcleos). Ele também requer o Windows Server Failover Clustering (WSFC), uma complicação não apenas para demonstrar a tecnologia em um laptop, mas também requer a Enterprise Edition do Windows, um controlador de domínio e várias configurações para oferecer suporte ao cluster. E também há novos requisitos em torno do Software Assurance; um custo adicional se você quiser que suas instâncias em espera sejam compatíveis.
Alguns clientes não podem justificar o preço. Outros vêem o valor, mas simplesmente não podem pagar. Então, o que esses usuários devem fazer?
Seu novo herói:envio de logs
O envio de logs existe há muito tempo. É simples e simplesmente funciona. Quase sempre. Além de contornar os custos de licenciamento e os obstáculos de configuração apresentados pelos Grupos de Disponibilidade, também pode evitar a penalidade de 14 bytes que Paul Randal (@PaulRandal) falou no boletim informativo SQLskills Insider desta semana (13 de outubro de 2014).
Um dos desafios que as pessoas têm ao usar a cópia do log enviado como um secundário legível, porém, é que você precisa expulsar todos os usuários atuais para aplicar novos logs - então você tem usuários ficando irritados porque são repetidamente interrompidos de executar consultas, ou você tem usuários ficando irritados porque seus dados estão obsoletos. Isso ocorre porque as pessoas se limitam a um único secundário legível.
Não precisa ser assim; Acho que há uma solução graciosa aqui e, embora possa exigir muito mais trabalho inicial do que, digamos, ativar os Grupos de Disponibilidade, certamente será uma opção atraente para alguns.
Basicamente, podemos configurar vários secundários, onde faremos o log ship e tornaremos apenas um deles o secundário "ativo", usando uma abordagem round-robin. O trabalho que envia os logs sabe qual está ativo no momento, portanto, apenas restaura novos logs para o servidor "próximo" usando o
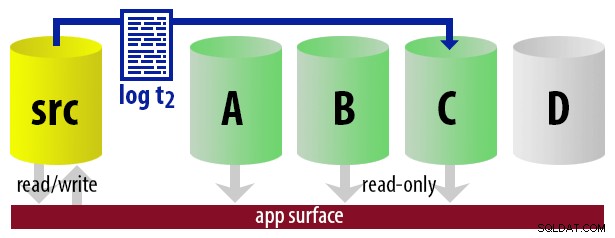
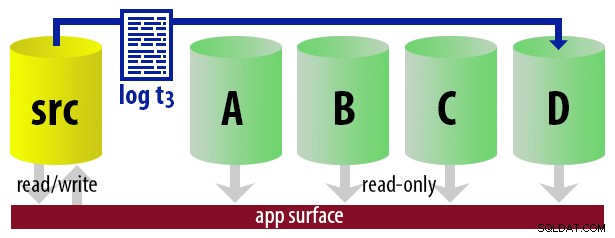
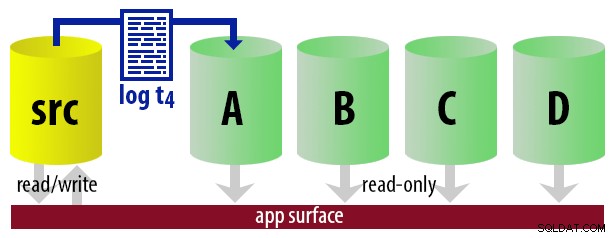
WITH STANDBY opção. O aplicativo de relatório usa as mesmas informações para determinar em tempo de execução qual deve ser a cadeia de conexão para o próximo relatório que o usuário executar. Quando o próximo backup de log estiver pronto, tudo muda em um, e a instância que agora se tornará o novo secundário legível é restaurada usando WITH STANDBY . Para manter o modelo descomplicado, digamos que temos quatro instâncias que servem como secundárias legíveis e fazemos backups de log a cada 15 minutos. A qualquer momento, teremos um secundário ativo no modo de espera, com dados com no máximo 15 minutos, e três secundários no modo de espera que não estão atendendo a novas consultas (mas ainda podem estar retornando resultados para consultas mais antigas).
Isso funcionará melhor se não for esperado que nenhuma consulta dure mais de 45 minutos. (Pode ser necessário ajustar esses ciclos dependendo da natureza de suas operações somente leitura, quantos usuários simultâneos estão executando consultas mais longas e se é possível interromper os usuários expulsando todos.)
Também funcionará melhor se consultas consecutivas executadas pelo mesmo usuário puderem alterar sua string de conexão (essa é a lógica que precisará estar no aplicativo, embora você possa usar sinônimos ou visualizações dependendo da arquitetura) e contiver dados diferentes que tenham mudou nesse meio tempo (como se eles estivessem consultando o banco de dados ativo e em constante mudança).
Com todas essas suposições em mente, aqui está uma sequência ilustrativa de eventos para os primeiros 75 minutos de nossa implementação:
| hora | eventos | visuais |
|---|---|---|
| 12:00 (t0) |
| 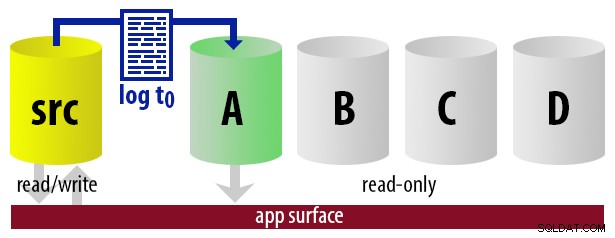 |
| 12:15 (t1) |
| 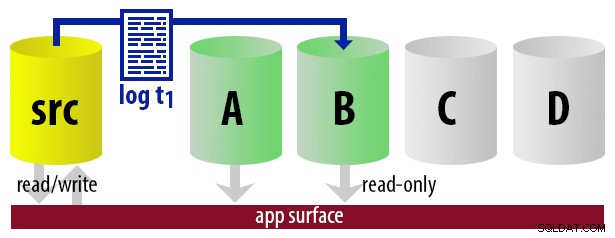 |
| 12:30 (t2) |
|  |
| 12:45 (t3) |
|  |
| 13:00 (t4) |
|  |
Isso pode parecer bastante simples; escrever o código para lidar com tudo isso é um pouco mais assustador. Um esboço grosseiro:
- No servidor primário (vou chamá-lo de
BOSS), crie um banco de dados. Antes mesmo de pensar em continuar, ative o Trace Flag 3226 para evitar que mensagens de backup bem-sucedidas estraguem o log de erros do SQL Server. - Em
CHEFE, adicione um servidor vinculado para cada secundário (vou chamá-los dePEON1->PEON4). - Em algum lugar acessível a todos os servidores, crie um compartilhamento de arquivos para armazenar backups de banco de dados/log e garanta que as contas de serviço de cada instância tenham acesso de leitura/gravação. Além disso, cada instância secundária precisa ter um local especificado para o arquivo em espera.
- Em um banco de dados utilitário separado (ou MSDB, se preferir), crie tabelas que conterão informações de configuração sobre o(s) banco(s) de dados, todos os secundários e registre o histórico de backup e restauração.
- Criar procedimentos armazenados que farão backup do banco de dados e restaurarão para os secundários
COM NORECOVERYe, em seguida, aplique um logWITH STANDBYe marque uma instância como secundária em espera atual. Esses procedimentos também podem ser usados para reinicializar toda a configuração de envio de logs caso algo dê errado. - Crie um job que será executado a cada 15 minutos, para realizar as tarefas descritas acima:
- fazer backup do registro
- determinar em qual secundário aplicar quaisquer backups de log não aplicados
- restaure esses registros com as configurações apropriadas
- Crie um procedimento armazenado (e/ou uma exibição?) que informará aos aplicativos de chamada qual secundário eles devem usar para quaisquer novas consultas somente leitura.
- Crie um procedimento de limpeza para limpar o histórico de backup dos logs que foram aplicados a todos os secundários (e talvez também para mover ou limpar os próprios arquivos).
- Aprimore a solução com tratamento de erros e notificações robustos.
Etapa 1 – criar um banco de dados
Minha instância principal é a Standard Edition, chamada
.\BOSS . Nessa instância eu crio um banco de dados simples com uma tabela:USE [master]; GO CREATE DATABASE UserData; GO ALTER DATABASE UserData SET RECOVERY FULL; GO USE UserData; GO CREATE TABLE dbo.LastUpdate(EventTime DATETIME2); INSERT dbo.LastUpdate(EventTime) SELECT SYSDATETIME();
Em seguida, crio um trabalho do SQL Server Agent que apenas atualiza esse carimbo de data/hora a cada minuto:
UPDATE UserData.dbo.LastUpdate SET EventTime = SYSDATETIME();
Isso apenas cria o banco de dados inicial e simula a atividade, permitindo validar como a tarefa de envio de logs gira em cada um dos secundários legíveis. Quero declarar explicitamente que o objetivo deste exercício não é enfatizar o envio de logs de teste ou provar quanto volume podemos processar; esse é um exercício completamente diferente.
Etapa 2 – adicionar servidores vinculados
Tenho quatro instâncias secundárias do Express Edition chamadas
.\PEON1 , .\PEON2 , .\PEON3 e .\PEON4 . Então eu executei este código quatro vezes, alterando @s cada vez:USE [master];
GO
DECLARE @s NVARCHAR(128) = N'.\PEON1', -- repeat for .\PEON2, .\PEON3, .\PEON4
@t NVARCHAR(128) = N'true';
EXEC [master].dbo.sp_addlinkedserver @server = @s, @srvproduct = N'SQL Server';
EXEC [master].dbo.sp_addlinkedsrvlogin @rmtsrvname = @s, @useself = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'collation compatible', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'data access', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc out', @optvalue = @t; Etapa 3 – validar o(s) compartilhamento(s) de arquivo
No meu caso, todas as 5 instâncias estão no mesmo servidor, então acabei de criar uma pasta para cada instância:
C:\temp\Peon1\ , C:\temp\Peon2\ , e assim por diante. Lembre-se de que, se seus secundários estiverem em servidores diferentes, a localização deve ser relativa a esse servidor, mas ainda ser acessível a partir do primário (portanto, normalmente um caminho UNC seria usado). Você deve validar se cada instância pode gravar nesse compartilhamento e também validar se cada instância pode gravar no local especificado para o arquivo em espera (usei as mesmas pastas para espera). Você pode validar isso fazendo backup de um pequeno banco de dados de cada instância para cada um dos locais especificados – não continue até que isso funcione. Etapa 4 – criar tabelas
Eu decidi colocar esses dados em
msdb , mas não tenho nenhum sentimento forte a favor ou contra a criação de um banco de dados separado. A primeira tabela que preciso é aquela que contém informações sobre o(s) banco(s) de dados que vou enviar o log:CREATE TABLE dbo.PMAG_Databases ( DatabaseName SYSNAME, LogBackupFrequency_Minutes SMALLINT NOT NULL DEFAULT (15), CONSTRAINT PK_DBS PRIMARY KEY(DatabaseName) ); GO INSERT dbo.PMAG_Databases(DatabaseName) SELECT N'UserData';
(Se você estiver curioso sobre o esquema de nomenclatura, PMAG significa "Grupos de Disponibilidade de Pobres".)
Outra tabela necessária é aquela que contém informações sobre os secundários, incluindo suas pastas individuais e seu status atual na sequência de envio de logs.
CREATE TABLE dbo.PMAG_Secondaries
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
CommonFolder VARCHAR(512) NOT NULL,
DataFolder VARCHAR(512) NOT NULL,
LogFolder VARCHAR(512) NOT NULL,
StandByLocation VARCHAR(512) NOT NULL,
IsCurrentStandby BIT NOT NULL DEFAULT 0,
CONSTRAINT PK_Sec PRIMARY KEY(DatabaseName, ServerInstance),
CONSTRAINT FK_Sec_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName)
); Se você deseja fazer backup do servidor de origem localmente e fazer com que os secundários sejam restaurados remotamente, ou vice-versa, você pode dividir
CommonFolder em duas colunas (BackupFolder e RestoreFolder ) e faça alterações relevantes no código (não haverá muitas). Como posso preencher esta tabela com base, pelo menos parcialmente, nas informações em
sys.servers – aproveitando o fato de que os dados / log e outras pastas são nomeados após os nomes das instâncias:INSERT dbo.PMAG_Secondaries
(
DatabaseName,
ServerInstance,
CommonFolder,
DataFolder,
LogFolder,
StandByLocation
)
SELECT
DatabaseName = N'UserData',
ServerInstance = name,
CommonFolder = 'C:\temp\Peon' + RIGHT(name, 1) + '\',
DataFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
LogFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
StandByLocation = 'C:\temp\Peon' + RIGHT(name, 1) + '\'
FROM sys.servers
WHERE name LIKE N'.\PEON[1-4]'; Também preciso de uma tabela para rastrear backups de log individuais (não apenas o último), porque em muitos casos precisarei restaurar vários arquivos de log em uma sequência. Posso obter essas informações em
msdb.dbo.backupset , mas é muito mais complicado obter coisas como a localização – e posso não ter controle sobre outros trabalhos que podem limpar o histórico de backup. CREATE TABLE dbo.PMAG_LogBackupHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT NOT NULL,
Location VARCHAR(2000) NOT NULL,
BackupTime DATETIME NOT NULL DEFAULT SYSDATETIME(),
CONSTRAINT PK_LBH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LBH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LBH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Você pode pensar que é um desperdício armazenar uma linha para cada secundário e armazenar o local de cada backup, mas isso é para proteção futura – para lidar com o caso em que você move o CommonFolder para qualquer secundário.
E, finalmente, um histórico de restaurações de log para que, a qualquer momento, eu possa ver quais logs foram restaurados e onde, e o trabalho de restauração pode restaurar apenas os logs que ainda não foram restaurados:
CREATE TABLE dbo.PMAG_LogRestoreHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT,
RestoreTime DATETIME,
CONSTRAINT PK_LRH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LRH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LRH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Etapa 5 – inicializar secundários
Precisamos de um procedimento armazenado que gere um arquivo de backup (e o espelhe em qualquer local exigido por diferentes instâncias), e também restauraremos um log para cada secundário para colocá-los todos em espera. Nesse ponto, todos eles estarão disponíveis para consultas somente leitura, mas apenas um será o modo de espera "atual" a qualquer momento. Este é o procedimento armazenado que manipulará backups completos e de log de transações; quando um backup completo é solicitado e
@init é definido como 1, ele reinicializa automaticamente o envio de logs. CREATE PROCEDURE [dbo].[PMAG_Backup]
@dbname SYSNAME,
@type CHAR(3) = 'bak', -- or 'trn'
@init BIT = 0 -- only used with 'bak'
AS
BEGIN
SET NOCOUNT ON;
-- generate a filename pattern
DECLARE @now DATETIME = SYSDATETIME();
DECLARE @fn NVARCHAR(256) = @dbname + N'_' + CONVERT(CHAR(8), @now, 112)
+ RIGHT(REPLICATE('0',6) + CONVERT(VARCHAR(32), DATEDIFF(SECOND,
CONVERT(DATE, @now), @now)), 6) + N'.' + @type;
-- generate a backup command with MIRROR TO for each distinct CommonFolder
DECLARE @sql NVARCHAR(MAX) = N'BACKUP'
+ CASE @type WHEN 'bak' THEN N' DATABASE ' ELSE N' LOG ' END
+ QUOTENAME(@dbname) + '
' + STUFF(
(SELECT DISTINCT CHAR(13) + CHAR(10) + N' MIRROR TO DISK = '''
+ s.CommonFolder + @fn + ''''
FROM dbo.PMAG_Secondaries AS s
WHERE s.DatabaseName = @dbname
FOR XML PATH(''), TYPE).value(N'.[1]',N'nvarchar(max)'),1,9,N'') + N'
WITH NAME = N''' + @dbname + CASE @type
WHEN 'bak' THEN N'_PMAGFull' ELSE N'_PMAGLog' END
+ ''', INIT, FORMAT' + CASE WHEN LEFT(CONVERT(NVARCHAR(128),
SERVERPROPERTY(N'Edition')), 3) IN (N'Dev', N'Ent')
THEN N', COMPRESSION;' ELSE N';' END;
EXEC [master].sys.sp_executesql @sql;
IF @type = 'bak' AND @init = 1 -- initialize log shipping
BEGIN
EXEC dbo.PMAG_InitializeSecondaries @dbname = @dbname, @fn = @fn;
END
IF @type = 'trn'
BEGIN
-- record the fact that we backed up a log
INSERT dbo.PMAG_LogBackupHistory
(
DatabaseName,
ServerInstance,
BackupSetID,
Location
)
SELECT
DatabaseName = @dbname,
ServerInstance = s.ServerInstance,
BackupSetID = MAX(b.backup_set_id),
Location = s.CommonFolder + @fn
FROM msdb.dbo.backupset AS b
CROSS JOIN dbo.PMAG_Secondaries AS s
WHERE b.name = @dbname + N'_PMAGLog'
AND s.DatabaseName = @dbname
GROUP BY s.ServerInstance, s.CommonFolder + @fn;
-- once we've backed up logs,
-- restore them on the next secondary
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname;
END
END Isso, por sua vez, chama dois procedimentos que você pode chamar separadamente (mas provavelmente não o fará). Primeiro, o procedimento que inicializará os secundários na primeira execução:
ALTER PROCEDURE dbo.PMAG_InitializeSecondaries
@dbname SYSNAME,
@fn VARCHAR(512)
AS
BEGIN
SET NOCOUNT ON;
-- clear out existing history/settings (since this may be a re-init)
DELETE dbo.PMAG_LogBackupHistory WHERE DatabaseName = @dbname;
DELETE dbo.PMAG_LogRestoreHistory WHERE DatabaseName = @dbname;
UPDATE dbo.PMAG_Secondaries SET IsCurrentStandby = 0
WHERE DatabaseName = @dbname;
DECLARE @sql NVARCHAR(MAX) = N'',
@files NVARCHAR(MAX) = N'';
-- need to know the logical file names - may be more than two
SET @sql = N'SELECT @files = (SELECT N'', MOVE N'''''' + name
+ '''''' TO N''''$'' + CASE [type] WHEN 0 THEN N''df''
WHEN 1 THEN N''lf'' END + ''$''''''
FROM ' + QUOTENAME(@dbname) + '.sys.database_files
WHERE [type] IN (0,1)
FOR XML PATH, TYPE).value(N''.[1]'',N''nvarchar(max)'');';
EXEC master.sys.sp_executesql @sql,
N'@files NVARCHAR(MAX) OUTPUT',
@files = @files OUTPUT;
SET @sql = N'';
-- restore - need physical paths of data/log files for WITH MOVE
-- this can fail, obviously, if those path+names already exist for another db
SELECT @sql += N'EXEC ' + QUOTENAME(ServerInstance)
+ N'.master.sys.sp_executesql N''RESTORE DATABASE ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + CommonFolder + @fn + N'''''' + N' WITH REPLACE,
NORECOVERY' + REPLACE(REPLACE(REPLACE(@files, N'$df$', DataFolder
+ @dbname + N'.mdf'), N'$lf$', LogFolder + @dbname + N'.ldf'), N'''', N'''''')
+ N';'';' + CHAR(13) + CHAR(10)
FROM dbo.PMAG_Secondaries
WHERE DatabaseName = @dbname;
EXEC [master].sys.sp_executesql @sql;
-- backup a log for this database
EXEC dbo.PMAG_Backup @dbname = @dbname, @type = 'trn';
-- restore logs
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname, @PrepareAll = 1;
END E então o procedimento que irá restaurar os logs:
CREATE PROCEDURE dbo.PMAG_RestoreLogs
@dbname SYSNAME,
@PrepareAll BIT = 0
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StandbyInstance SYSNAME,
@CurrentInstance SYSNAME,
@BackupSetID INT,
@Location VARCHAR(512),
@StandByLocation VARCHAR(512),
@sql NVARCHAR(MAX),
@rn INT;
-- get the "next" standby instance
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 0
AND ServerInstance > (SELECT ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandBy = 1);
IF @StandbyInstance IS NULL -- either it was last or a re-init
BEGIN
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries;
END
-- get that instance up and into STANDBY
-- for each log in logbackuphistory not in logrestorehistory:
-- restore, and insert it into logrestorehistory
-- mark the last one as STANDBY
-- if @prepareAll is true, mark all others as NORECOVERY
-- in this case there should be only one, but just in case
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT bh.BackupSetID, s.ServerInstance, bh.Location, s.StandbyLocation,
rn = ROW_NUMBER() OVER (PARTITION BY s.ServerInstance ORDER BY bh.BackupSetID DESC)
FROM dbo.PMAG_LogBackupHistory AS bh
INNER JOIN dbo.PMAG_Secondaries AS s
ON bh.DatabaseName = s.DatabaseName
AND bh.ServerInstance = s.ServerInstance
WHERE s.DatabaseName = @dbname
AND s.ServerInstance = CASE @PrepareAll
WHEN 1 THEN s.ServerInstance ELSE @StandbyInstance END
AND NOT EXISTS
(
SELECT 1 FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE DatabaseName = @dbname
AND ServerInstance = s.ServerInstance
AND BackupSetID = bh.BackupSetID
)
ORDER BY CASE s.ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 2 END, bh.BackupSetID;
OPEN c;
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
WHILE @@FETCH_STATUS -1
BEGIN
-- kick users out - set to single_user then back to multi
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance) + N'.[master].sys.sp_executesql '
+ 'N''IF EXISTS (SELECT 1 FROM sys.databases WHERE name = N'''''
+ @dbname + ''''' AND [state] 1)
BEGIN
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET SINGLE_USER '
+ N'WITH ROLLBACK IMMEDIATE;
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET MULTI_USER;
END;'';';
EXEC [master].sys.sp_executesql @sql;
-- restore the log (in STANDBY if it's the last one):
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance)
+ N'.[master].sys.sp_executesql ' + N'N''RESTORE LOG ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + @Location + N''''' WITH ' + CASE WHEN @rn = 1
AND (@CurrentInstance = @StandbyInstance OR @PrepareAll = 1) THEN
N'STANDBY = N''''' + @StandbyLocation + @dbname + N'.standby''''' ELSE
N'NORECOVERY' END + N';'';';
EXEC [master].sys.sp_executesql @sql;
-- record the fact that we've restored logs
INSERT dbo.PMAG_LogRestoreHistory
(DatabaseName, ServerInstance, BackupSetID, RestoreTime)
SELECT @dbname, @CurrentInstance, @BackupSetID, SYSDATETIME();
-- mark the new standby
IF @rn = 1 AND @CurrentInstance = @StandbyInstance -- this is the new STANDBY
BEGIN
UPDATE dbo.PMAG_Secondaries
SET IsCurrentStandby = CASE ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 0 END
WHERE DatabaseName = @dbname;
END
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
END
CLOSE c; DEALLOCATE c;
END (Sei que é muito código e muito SQL dinâmico enigmático. Tentei ser muito liberal com comentários; se houver alguma parte com a qual você esteja tendo problemas, por favor me avise.)
Então agora, tudo o que você precisa fazer para colocar o sistema em funcionamento é fazer duas chamadas de procedimento:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'bak', @init = 1; EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Agora você deve ver cada instância com uma cópia em espera do banco de dados:
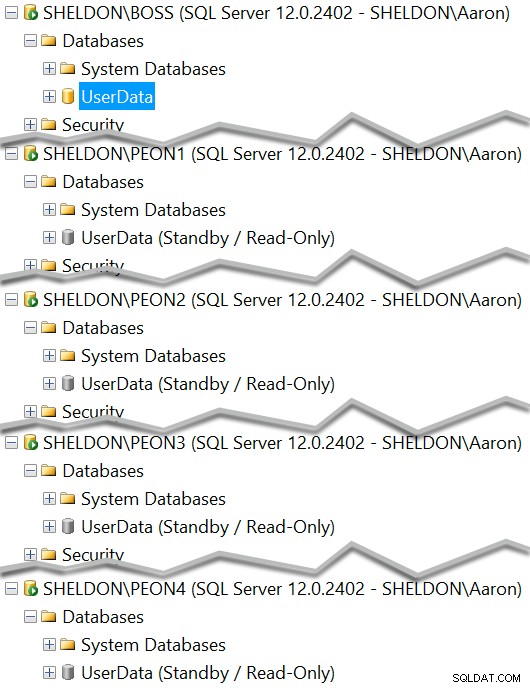
E você pode ver qual deve servir atualmente como espera somente leitura:
SELECT ServerInstance, IsCurrentStandby FROM dbo.PMAG_Secondaries WHERE DatabaseName = N'UserData';
Etapa 6 – crie um trabalho que faça backup/restaure logs
Você pode colocar este comando em um trabalho que você agenda a cada 15 minutos:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Isso mudará o secundário ativo a cada 15 minutos e seus dados serão 15 minutos mais atualizados do que o secundário ativo anterior. Se você tiver vários bancos de dados em agendamentos diferentes, poderá criar vários trabalhos ou agendar o trabalho com mais frequência e verificar o
dbo.PMAG_Databases tabela para cada LogBackupFrequency_Minutes individual valor para determinar se você deve executar o backup/restauração para esse banco de dados. Etapa 7 - visualização e procedimento para informar ao aplicativo qual espera está ativa
CREATE VIEW dbo.PMAG_ActiveSecondaries
AS
SELECT DatabaseName, ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 1;
GO
CREATE PROCEDURE dbo.PMAG_GetActiveSecondary
@dbname SYSNAME
AS
BEGIN
SET NOCOUNT ON;
SELECT ServerInstance
FROM dbo.PMAG_ActiveSecondaries
WHERE DatabaseName = @dbname;
END
GO No meu caso, também criei manualmente uma união de exibição em todos os
UserData bancos de dados para que eu pudesse comparar a atualidade dos dados no primário com cada secundário. CREATE VIEW dbo.PMAG_CompareRecency_UserData
AS
WITH x(ServerInstance, EventTime)
AS
(
SELECT @@SERVERNAME, EventTime FROM UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON1', EventTime FROM [.\PEON1].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON2', EventTime FROM [.\PEON2].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON3', EventTime FROM [.\PEON3].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON4', EventTime FROM [.\PEON4].UserData.dbo.LastUpdate
)
SELECT x.ServerInstance, s.IsCurrentStandby, x.EventTime,
Age_Minutes = DATEDIFF(MINUTE, x.EventTime, SYSDATETIME()),
Age_Seconds = DATEDIFF(SECOND, x.EventTime, SYSDATETIME())
FROM x LEFT OUTER JOIN dbo.PMAG_Secondaries AS s
ON s.ServerInstance = x.ServerInstance
AND s.DatabaseName = N'UserData';
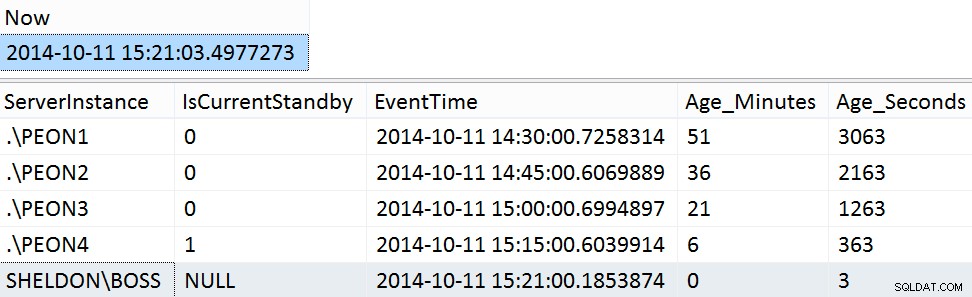
GO Exemplos de resultados do fim de semana:
SELECT [Now] = SYSDATETIME(); SELECT ServerInstance, IsCurrentStandby, EventTime, Age_Minutes, Age_Seconds FROM dbo.PMAG_CompareRecency_UserData ORDER BY Age_Seconds DESC;
Etapa 8 - procedimento de limpeza
Limpar o histórico de backup e restauração de log é muito fácil.
CREATE PROCEDURE dbo.PMAG_CleanupHistory
@dbname SYSNAME,
@DaysOld INT = 7
AS
BEGIN
SET NOCOUNT ON;
DECLARE @cutoff INT;
-- this assumes that a log backup either
-- succeeded or failed on all secondaries
SELECT @cutoff = MAX(BackupSetID)
FROM dbo.PMAG_LogBackupHistory AS bh
WHERE DatabaseName = @dbname
AND BackupTime < DATEADD(DAY, -@DaysOld, SYSDATETIME())
AND EXISTS
(
SELECT 1
FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE BackupSetID = bh.BackupSetID
AND DatabaseName = @dbname
AND ServerInstance = bh.ServerInstance
);
DELETE dbo.PMAG_LogRestoreHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
DELETE dbo.PMAG_LogBackupHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
END
GO Agora, você pode adicionar isso como uma etapa no trabalho existente ou pode agendá-lo completamente separadamente ou como parte de outras rotinas de limpeza.
Vou deixar a limpeza do sistema de arquivos para outro post (e provavelmente um mecanismo separado, como PowerShell ou C# – isso normalmente não é o tipo de coisa que você deseja que o T-SQL faça).
Etapa 9 – aumente a solução
É verdade que poderia haver um melhor tratamento de erros e outras sutilezas aqui para tornar esta solução mais completa. Por enquanto, deixarei isso como um exercício para o leitor, mas pretendo analisar as postagens de acompanhamento para detalhar melhorias e refinamentos nessa solução.
Variáveis e limitações
Observe que, no meu caso, usei a Standard Edition como primária e a Express Edition para todas as secundárias. Você poderia dar um passo adiante na escala de orçamento e até usar o Express Edition como o principal – muitas pessoas pensam que o Express Edition não suporta envio de logs, quando na verdade é apenas o assistente que não estava presente nas versões do Management Studio Express antes do SQL Server 2012 Service Pack 1. Dito isso, como o Express Edition não oferece suporte ao SQL Server Agent, seria difícil torná-lo um editor nesse cenário - você teria que configurar seu próprio agendador para chamar os procedimentos armazenados (C# aplicativo de linha de comando executado pelo Agendador de Tarefas do Windows, trabalhos do PowerShell ou trabalhos do SQL Server Agent em outra instância). Para usar o Express em qualquer extremidade, você também precisa ter certeza de que seu arquivo de dados não excederá 10 GB e suas consultas funcionarão bem com as limitações de memória, CPU e recursos dessa edição. Não estou sugerindo que o Express seja ideal; Eu apenas o usei para demonstrar que é possível ter secundários legíveis muito flexíveis de graça (ou muito próximos disso).
Além disso, todas essas instâncias separadas no meu cenário vivem na mesma VM, mas não precisa funcionar dessa maneira – você pode distribuir as instâncias em vários servidores; ou, você pode seguir o outro caminho e restaurar em diferentes cópias do banco de dados, com nomes diferentes, na mesma instância. Essas configurações exigiriam alterações mínimas no que expus acima. E quantos bancos de dados você restaura e com que frequência depende completamente de você - embora haja um limite superior prático (onde
[tempo médio de consulta]> [número de secundários] x [intervalo de backup de log] ).
Finalmente, existem definitivamente algumas limitações com esta abordagem. Uma lista não exaustiva:
- Embora você possa continuar a fazer backups completos em sua própria programação, os backups de log devem servir como seu único mecanismo de backup de log. Se você precisar armazenar os backups de log para outros fins, não poderá fazer backup de logs separadamente desta solução, pois eles interferirão na cadeia de logs. Em vez disso, você pode considerar adicionar mais
MIRROR TO argumentos para os scripts de backup de log existentes, se você precisar ter cópias dos logs usados em outro lugar.
- Embora "Grupos de Disponibilidade do Homem Pobre" possa parecer um nome inteligente, também pode ser um pouco enganoso. This solution certainly lacks many of the HA/DR features of Availability Groups, including failover, automatic page repair, and support in the UI, Extended Events and DMVs. This was only meant to provide the ability for non-Enterprise customers to have an infrastructure that supports multiple readable secondaries.
- I tested this on a very isolated VM system with no concurrency. This is not a complete solution and there are likely dozens of ways this code could be made tighter; as a first step, and to focus on the scaffolding and to show you what's possible, I did not build in bulletproof resiliency. You will need to test it at your scale and with your workload to discover your breaking points, and you will also potentially need to deal with transactions over linked servers (always fun) and automating the re-initialization in the event of a disaster.
The "Insurance Policy"
Log shipping also offers a distinct advantage over many other solutions, including Availability Groups, mirroring and replication:a delayed "insurance policy" as I like to call it. At my previous job, I did this with full backups, but you could easily use log shipping to accomplish the same thing:I simply delayed the restores to one of the secondary instances by 24 hours. This way, I was protected from any client "shooting themselves in the foot" going back to yesterday, and I could get to their data easily on the delayed copy, because it was 24 hours behind. (I implemented this the first time a customer ran a delete without a where clause, then called us in a panic, at which point we had to restore their database to a point in time before the delete – which was both tedious and time consuming.) You could easily adapt this solution to treat one of these instances not as a read-only secondary but rather as an insurance policy. More on that perhaps in another post.